基础模型是大规模的深度学习模型,它们在大量通用的无标签数据上进行了预训练。它们可以应用于各种任务,如生成图像或回答客户问题。
但是,这些模型(如ChatGPT和DALL-E)可能提供错误或误导性的信息。在安全关键的情况下,例如行人接近自动驾驶汽车,这些错误可能会产生严重后果。
为了帮助防止此类错误,麻省理工学院(MIT)和MIT-IBM Watson AI实验室的研究人员开发了一种技术,用于在将基础模型部署到特定任务之前估计其可靠性。
他们通过考虑一组略有不同的基础模型来实现这一点。然后,他们使用算法评估每个模型对相同测试数据点学习的表示的一致性。如果表示一致,则表示模型可靠。
当他们将自己的技术与最先进的基准方法进行比较时,它在各种下游分类任务中更好地捕捉到了基础模型的可靠性。
某人可以使用这种技术来决定是否在特定环境中应用模型,而无需在真实数据集上进行测试。这在数据集可能由于隐私问题而无法访问的情况下特别有用,例如在医疗保健环境中。此外,该技术可以用于根据可靠性评分对模型进行排序,使用户可以选择最适合其任务的模型。
“所有模型都可能出错,但知道何时出错的模型更有用。对于这些基础模型来说,量化不确定性或可靠性的问题更具挑战性,因为它们的抽象表示很难进行比较。我们的方法允许量化表示模型对任何给定输入数据的可靠性,”高级作者Navid Azizan说道,他是麻省理工学院机械工程系和数据、系统与社会研究所(IDSS)的Esther和Harold E. Edgerton助理教授,也是信息与决策系统实验室(LIDS)的成员。
他在这项工作的论文中与首席作者Young-Jin Park(LIDS研究生)、MIT-IBM Watson AI实验室的研究科学家Hao Wang和Netflix的高级研究科学家Shervin Ardeshir一起合作。该论文将在不确定性人工智能会议上进行展示。
衡量共识
传统的机器学习模型被训练来执行特定任务。这些模型通常根据输入进行具体预测。例如,模型可能会告诉您某个图像是否包含猫或狗。在这种情况下,评估可靠性可能是查看最终预测结果是否正确。
但是基础模型不同。该模型是使用通用数据进行预训练的,在创建者不知道它将应用于哪些下游任务的情况下。用户在已经训练好的模型上适应其特定任务。
与传统的机器学习模型不同,基础模型不会给出像“猫”或“狗”标签这样的具体输出。相反,它们根据输入数据点生成抽象表示。
为了评估基础模型的可靠性,研究人员使用了一种集成方法,通过训练多个模型,这些模型在许多属性上相似但略有不同。
“我们的想法就像衡量共识。如果所有这些基础模型对我们数据集中的任何数据都提供一致的表示,那么我们可以说这个模型是可靠的,”Park说。
但是他们遇到了一个问题:如何比较抽象表示?
“这些模型只输出一个由一些数字组成的向量,所以我们无法轻松比较它们,”他补充道。
他们通过使用称为邻域一致性的思想解决了这个问题。
对于他们的方法,研究人员准备了一组可靠的参考点,用于在模型集合上进行测试。然后,对于每个模型,他们研究与该模型对测试点的表示附近的参考点。
通过观察相邻点的一致性,他们可以估计模型的可靠性。
对齐表示
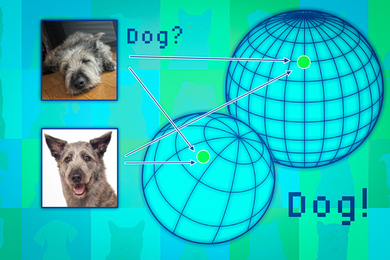
基础模型将数据点映射到所谓的表示空间。可以将这个空间想象成一个球体。每个模型将相似的数据点映射到其球体的同一部分,因此猫的图像放在一个地方,狗的图像放在另一个地方。
但是每个模型会在自己的球体中以不同的方式映射动物,因此猫可能在一个球体的南极附近分组,而另一个模型可能将猫映射到北半球的某个地方。
研究人员使用邻域点作为锚点,将这些球体对齐,以使表示可比较。如果数据点的邻域在多个表示中保持一致,那么可以对该点的模型输出的可靠性感到自信。
当他们在各种分类任务上测试这种方法时,他们发现它比基准方法更一致。此外,它不会被导致其他方法失败的具有挑战性的测试点所困扰。
此外,他们的方法可以用于评估任何输入数据的可靠性,因此可以评估模型对特定类型个体(例如具有特定特征的患者)的工作效果。
“即使所有模型的整体性能都是平均水平,从个体的角度来看,您更喜欢最适合该个体的模型,”Wang说。
然而,一个限制是他们必须训练一个基础模型的集合,这在计算上是昂贵的。未来,他们计划寻找更高效的构建多个模型的方法,可能是使用单个模型的小扰动。
“随着当前趋势使用基础模型的嵌入来支持各种下游任务 – 从微调到检索增强生成 – 在表示级别量化不确定性的主题变得越来越重要,但也更具挑战性,因为嵌入本身没有基础。相反,重要的是不同输入的嵌入如何相互关联,这个工作通过提出的邻域一致性得分巧妙地捕捉到了这个思想,”斯坦福大学航空航天系副教授Marco Pavone说道,他与这项工作无关。“这是朝着高质量嵌入模型的不确定性量化迈出的一步,我很期待看到未来的扩展,这些扩展可以在不需要模型集成的情况下运行,从而真正实现这种方法在基础模型规模上的扩展。”
这项工作部分资助来自MIT-IBM Watson AI实验室、MathWorks和亚马逊。



