‘

‘ 这段文字的中文翻译如下:
‘
‘
LoRA: 大型语言模型的低秩适应
机器学习和自然语言处理(NLP)领域在引入大型语言模型(LLMs)如GPT、LLaMa、Claude 2等之后取得了显著的进展。这些模型在各种应用中展示了出色的能力,从文本生成到语言理解等各个方面。
然而,这些模型的实际部署和微调面临着重大挑战,主要是由于它们的规模和复杂性。
这就是低秩适应(LoRA)发挥作用的地方,为这些挑战提供了有效的解决方案。
本教程的目标是建立对LoRA是什么以及如何从中受益的理论和实践理解。
背景
LoRA的起源可以追溯到2021年初,当时GPT-3发布。微软与OpenAI合作,面临着使像GPT-3这样的大型模型在商业上可行的挑战。
他们发现仅仅使用一次提示是不足以在生产中实现最佳性能的,尤其是对于像将自然语言翻译成代码这样复杂的任务。这促使他们探索了既具有成本效益又高效的微调方法。
LoRA的发明是基于产品需要,以实现对大型语言模型的快速、高效和经济有效的微调,以实现领域特定性、高效任务切换或用户切换。
这篇LoRA研究论文是由微软的研究团队于2021年10月发表的。
为什么我们需要LoRA?
在我们了解LoRa是什么以及它是如何解决问题之前,让我们先了解一下问题。
像GPT-4、Claude 2、LLaMA 70b等大型语言模型非常强大,但它们非常通用和庞大。要将这些大型语言模型应用于特定领域,如医疗保健或银行业,或者用于将文本转换为代码等特定任务,我们需要一种称为微调的方法。
Fine-tuning是指在特定的、较小的数据集上对预训练模型进行训练,以便使其在特定任务或领域中的性能更加专业化。随着模型变得越来越大(例如,GPT-3有1750亿个参数),由于时间、成本和资源的限制,完全的fine-tuning,即重新训练所有模型参数,变得不太可行。
LoRA是一种用于对大型模型进行微调的技术。
LoRA的工作原理
以下是LoRA的工作原理:
它保持原始模型不变,并在模型的每一层添加小的、可变的部分。这显著减少了模型的可训练参数,并减少了训练过程中对GPU内存的需求,这是在微调或训练大型模型时面临的另一个重要挑战。
例如,对GPT-3模型进行完全微调将需要我们训练1750亿个参数。使用LoRA,GPT-3的可训练参数将减少大约10,000倍,GPU内存需求减少三倍。
从本质上讲,LoRA解决了以下问题:
- 速度 – 因为可训练参数较少,所以训练速度更快
- 计算资源 – 可训练参数较少意味着训练过程所需的计算资源较少,使得对大型模型进行微调在经济上可行。
- 内存效率 – 可训练参数较少意味着我们可以将它们缓存在内存中,消除了从磁盘读取的需求,与从内存读取相比,磁盘读取效率低下。
低秩矩阵
在我们深入了解LoRA的细节之前,让我们先了解一下低秩矩阵的概念。
低秩矩阵是数学中的一个概念,特别是在线性代数领域。简单来说,矩阵的秩是表示矩阵所代表的数据的“信息内容”或“维度”的度量。让我们来详细解释一下:
- 矩阵:
矩阵是一个由数字组成的矩形数组。例如,一个3×3的矩阵有3行和3列。
- 矩阵的秩:
矩阵的秩由矩阵中线性独立的行或列的数量确定。线性独立意味着没有行(或列)可以由其他行(或列)的组合形成。
如果所有行(或列)都是线性独立的,矩阵具有满秩。
如果一些行(或列)可以通过组合其他行(或列)形成,矩阵的秩较低。
- 秩较低的矩阵:
如果矩阵的秩小于其尺寸所允许的最大值,则矩阵的秩较低。例如,在一个3×3的矩阵中,如果秩小于3,则它是一个秩较低的矩阵。
示例:
‘
考虑一个3 x 3的矩阵:
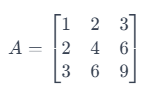
这段文字的中文翻译如下:在这里,第二行只是第一行乘以2,第三行是第一行乘以3。这意味着这些行不是线性独立的。这个矩阵的秩是1(因为只有第一行是独立的),这个秩比一个3×3矩阵的最大可能秩3要低。所以,这是一个低秩矩阵。
低秩矩阵在各种应用中都很重要,比如数据压缩,通过降低矩阵的秩来压缩数据,同时尽可能地保留更多的信息。
矩阵的秩对行和列都适用。关键要理解的是,无论是基于行还是列计算,矩阵的秩都是相同的。这是因为线性代数中的一个基本性质,被称为秩-零空间定理。
简单来说,定理表明矩阵的行空间(由行张成的空间)和列空间(由列张成的空间)的维度是相等的。我们称这个共同的维度为矩阵的秩。
所以,在上面的3 x 3矩阵的例子中,秩为1,这意味着只有一行是线性独立的,也只有一列是线性独立的。
什么是LoRA?
简单来说,LoRA利用低秩矩阵的概念使模型训练过程变得非常高效和快速。
大型模型有很多参数。例如,GPT-3有1750亿个参数。这些参数只是存储在矩阵中的数字。存储它们需要大量的存储空间。
全面微调意味着所有参数都将被训练,这将需要大量的计算资源,对于像GPT这样的模型大小,这很容易花费数百万美元。
与需要调整整个模型的传统微调不同,LoRA专注于修改较小的参数子集(低秩矩阵),从而减少计算和内存开销。
LoRA是建立在对大型模型具有低维结构的理解基础上的。通过利用低秩矩阵,LoRA有效地适应这些模型。该方法专注于核心概念,即重要的模型变化可以用更少的参数表示,从而使适应过程更加高效。
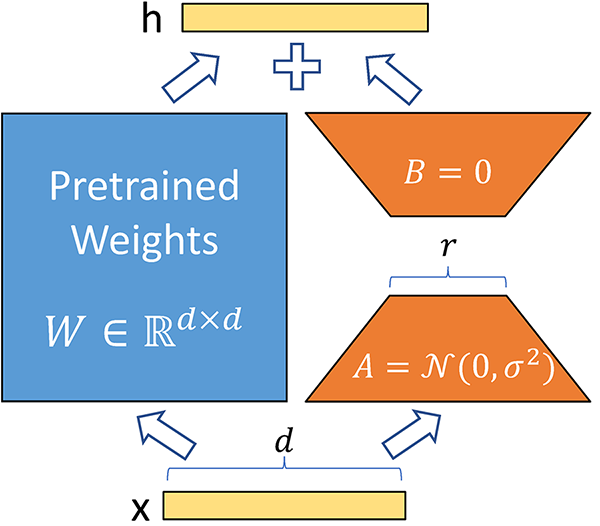
这段文字的中文翻译如下:
来源:Fine-Tuning LLMs: LoRA or Full-Parameter? An in-depth Analysis with Llama 2
那么它是如何工作的?
首先,我们使用低秩矩阵技术将大型权重矩阵分解为较小的矩阵,如上所述。这大大减少了可训练参数的数量。对于像GPT-3这样的模型,可训练参数减少了10000倍。这意味着如果应用LoRA,您只需要训练1750亿个参数,而不是1750亿个参数。
我们不会改变预训练模型的任何参数。相反,我们只训练较低秩的矩阵,由于参数较少,这个过程相对较快。
权重是可加的。这意味着在推理过程中,我们只需将低秩矩阵的权重与预训练权重相加,而无需额外的延迟。低秩矩阵的大小也非常小,因此非常容易为不同的任务和不同的用户加载和卸载它们。
LoRA的优势
使用LoRA进行微调有几个优点:
1. 训练和部署的效率
LoRA减少了计算负担,使模型能够更快地适应。通过减少可训练参数的数量,LoRA使得在性能较低的硬件上对大型模型进行微调成为可能。
2. 保持模型质量和速度
尽管参数数量减少,但LoRA仍保持了原始模型的质量和推理速度。
3. 检查点大小的减小
LoRA大大减小了模型检查点的大小。例如,在GPT-3上,检查点的大小从1 TB减小到了仅有25 MB。
4. 无推理延迟
LoRA在推理过程中不会引入任何额外的延迟。虽然在训练过程中使用了低秩矩阵,但在推理过程中它们会与原始参数合并,确保没有减速。这使得在运行时可以快速切换模型,而不会增加额外的推理延迟。
5. 多功能性
LoRA适用于任何使用矩阵乘法的模型(如支持向量机),使其成为许多其他用例中广泛适用的技术。事实上,LoRA广泛用于稳定扩散模型中,以在大型图像模型中摄取风格。
稳定扩散 LoRA
LoRA 技术也被广泛应用于像稳定扩散这样的图像模型中。
这个想法与语言模型基本相同。与完全微调像稳定扩散这样的大型模型不同,我们只在小数据集上训练低秩矩阵。
对于语言模型来说,目标是领域特定性。对于图像模型来说,最明显的用例是在生成图像时采用一种风格或一致的特征。
这些低秩矩阵被称为适配器;它们的尺寸非常小,在互联网上有成千上万个可以下载的适配器,你可以将它们放在基础的稳定扩散模型之上,生成具有特定风格的图像。
LoRA稳定扩散模型的一些常见用途包括:
- 风格专业化 – 动漫风格、油画风格等
- 角色专业化 – 可靠地生成马里奥或海绵宝宝的图像
- 质量改进 – 更多细节、更好的面部等
您可以组合多个LoRA来获得反映多种专业化的输出。

这段文字的中文翻译如下:
稳定扩散模型的不同适配器(图片来源)
如果你想学习如何成功地在个人照片上进行稳定扩散XL的微调,请查看Datacamp上的Fine-tuning Stable Diffusion XL with DreamBooth and LoRA blog。
将LoRA与前缀调整相结合
前缀调整是一种轻量级的方法,其中连续的向量称为“前缀”,并且被优化并添加到每个Transformer层的输入中。模型以去除前缀的方式进行训练,只关注这些向量。
预修调谐的好处:
- 只需要存储每个任务的小前缀向量,而不是完整的微调模型副本。
- 便于任务切换和个性化。
- 在低数据情况下,与完全微调相比表现良好。
- 在训练过程中,只更新前缀,计算成本较低。
LoRA和前缀调谐可以在PEFT(参数高效微调)框架中结合使用:
- LoRA减少了总体参数,而前缀调整提供了任务特定的控制
- 它们共同实现了使用最少的数据和计算进行专门的微调
- 非常适合使用有限的领域数据进行大型LLM的领域适应
- 这种模块化的微调释放了大型LLM的全部潜力,适用于资源受限的用户。
使用Loralib库在Python中实现LoRA的示例
要实现LoRA,您可以使用微软的Loralib库。要安装该库:
pip install loralib
通常训练神经网络的方式在采用LoRA时并没有太大变化。
在训练循环开始之前,您只需要添加以下内容:
import loralib as lora
model = YourNeuralNetwork()
# 这将所有参数的requires_grad设置为False
lora.mark_only_lora_as_trainable(model)
# 训练循环
for batch in dataloader:
...
保存检查点时,您可以生成一个仅包含LoRA参数的state_dic。
# ===== Before =====
# torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
如果你对神经网络不太了解,不用担心。请查看如何使用PyTorch训练大型语言模型的博客,掌握使用PyTorch训练大型语言模型的过程,从初始设置到最终实现。
致谢:此代码示例已从Microsoft/LoRA github重新制作。
结论
LoRA在应对大型模型的规模和复杂性所带来的重大挑战中显得不可或缺。
通过利用低秩矩阵,LoRA提供了一种更高效和经济的模型适应方法,显著减少了可训练参数和GPU内存需求,从而实现了更快的训练速度和内存效率。
LoRA的应用不仅限于语言模型,还可以在图像模型中发挥作用,例如在稳定扩散中,它可以促进图像生成中的风格专业化和字符一致性。
如果你好奇并且想要了解更多关于你可以用这些技术构建什么的信息,可以查看我们的指南:5 Projects You Can Build with Generative AI Models blog 以获取更多信息。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”