

‘在当今数据驱动的世界中,对可扩展、高性能和高可用性数据库的需求比以往任何时候都更大。亚马逊 DynamoDB 是由 AWS(亚马逊网络服务)提供的完全托管、无服务器、宽列键值存储,旨在满足这些需求。无论您是构建网页应用、移动应用还是任何需要灵活可靠存储的系统,DynamoDB 都能满足您的需求。
本教程旨在向您介绍亚马逊DynamoDB的世界,并演示如何在Node.js应用程序中有效使用它。无论您是刚开始使用NoSQL数据库的初学者,还是经验丰富的开发人员希望扩展自己的技能,本指南将引导您了解基本知识,并提供实际示例,帮助您入门。
什么是DynamoDB?
Amazon DynamoDB是一个无服务器、键值和文档数据库,提供无缝扩展和低延迟性能。与传统的关系型数据库不同,DynamoDB不需要您预配硬件或管理基础设施,这使其成为需要根据不断变化的工作负载动态扩展或缩减的应用程序的理想选择。
DynamoDB的主要特点包括:
可扩展性
DynamoDB可以处理每秒数百万个请求,适用于流量变化较大的应用程序。
高可用性
设计为具有高可用性和数据持久性,内置多个可用区的复制。
托管服务
AWS负责处理操作开销,包括硬件供应、补丁和备份,让您可以专注于构建应用程序。
灵活的数据模型
DynamoDB支持键值和文档数据模型,为您在数据结构上提供了灵活性。
安全性
AWS身份和访问管理(IAM)集成使您能够对数据库资源进行细粒度的安全访问控制,包括项目和属性级别。
成本节约
DynamoDB的无服务器架构,加上其自动扩展能力,使您能够通过仅支付您消耗的资源来优化成本。没有预先的硬件成本或长期承诺,使其成为初创企业和企业的经济选择。
数据类型
DynamoDB支持的数据类型:
- 标量类型:包括字符串、数字、二进制、布尔值和空值。
- 文档类型:DynamoDB可以容纳具有嵌套属性的复杂结构,非常适合处理JSON数据。
- 集合类型:字符串集合、数字集合和二进制集合使您能够高效地存储相关值的集合。
为什么要在Node.js中使用DynamoDB?
Node.js是用于构建服务器端应用程序(包括Web服务器和API)的流行运行时环境。它的非阻塞、事件驱动的架构与DynamoDB的异步API很搭配,使其成为Node.js开发人员的自然选择。
在本教程中,我们将涵盖以下主题:
1. 在DynamoDB中创建表并定义模式。
2. 使用AWS SDK for Node.js执行基本的CRUD(创建、读取、更新、删除)操作。
3. 具备ACID兼容性的高级查询。
在本教程结束时,您将对Amazon DynamoDB有一个扎实的理解,并且知道如何在您的Node.js应用程序中利用其强大功能。所以,让我们深入了解并发掘这个多功能的NoSQL数据库的潜力!
准备工作
在开始之前,您需要一个AWS账户。虽然我们可以在没有AWS账户的情况下完成所有操作,但为了更真实的示例,我们将使用terraform在AWS中创建基础设施。有关如何使用Docker在本地使用AWS服务的更多信息,您可以参考并尝试我的示例演示localstack github存储库。
现在是安装terraform的时候,如果你还没有安装的话。
本教程的其余部分将假设您已经设置了AWS CLI,并且已经配置了凭据和配置文件,并且已经安装了terraform。
入门
在本教程中,我们将使用TypeScript和Yarn。在本教程中,我们将简单地使用ts-node开始,然后在下一个教程中,我们将使用AWS Lambda来进行无服务器开发并扩展此内容。
为了设置我们的演示项目,请创建一个新文件夹,然后通过运行以下命令添加以下依赖项和设置:
yarn init
yarn add --dev typescript ts-node @types/node @types/ramda @types/uuid
yarn add @aws-sdk/client-dynamodb ramda uuid
npx tsc --init
mkdir src src/domain infra
touch ./src/index.ts ./src/client.ts ./infra/main.tf ./src/domain/student.ts
接下来将以下脚本部分添加到package.json中
"scripts": {
"dev": "ts-node src/index.ts"
},
main.tf
provider "aws" {
region = "eu-west-1"
}
resource "aws_dynamodb_table" "demo-table" {
name = "demo-table"
billing_mode = "PAY_PER_REQUEST"
hash_key = "pk"
range_key = "sk"
attribute {
name = "pk"
type = "S"
}
attribute {
name = "sk"
type = "S"
}
}
从命令行进入 infra 目录并运行 terraform init && terraform apply -auto-approve,然后转到 AWS 控制台并查看您的 DynamoDB 表:
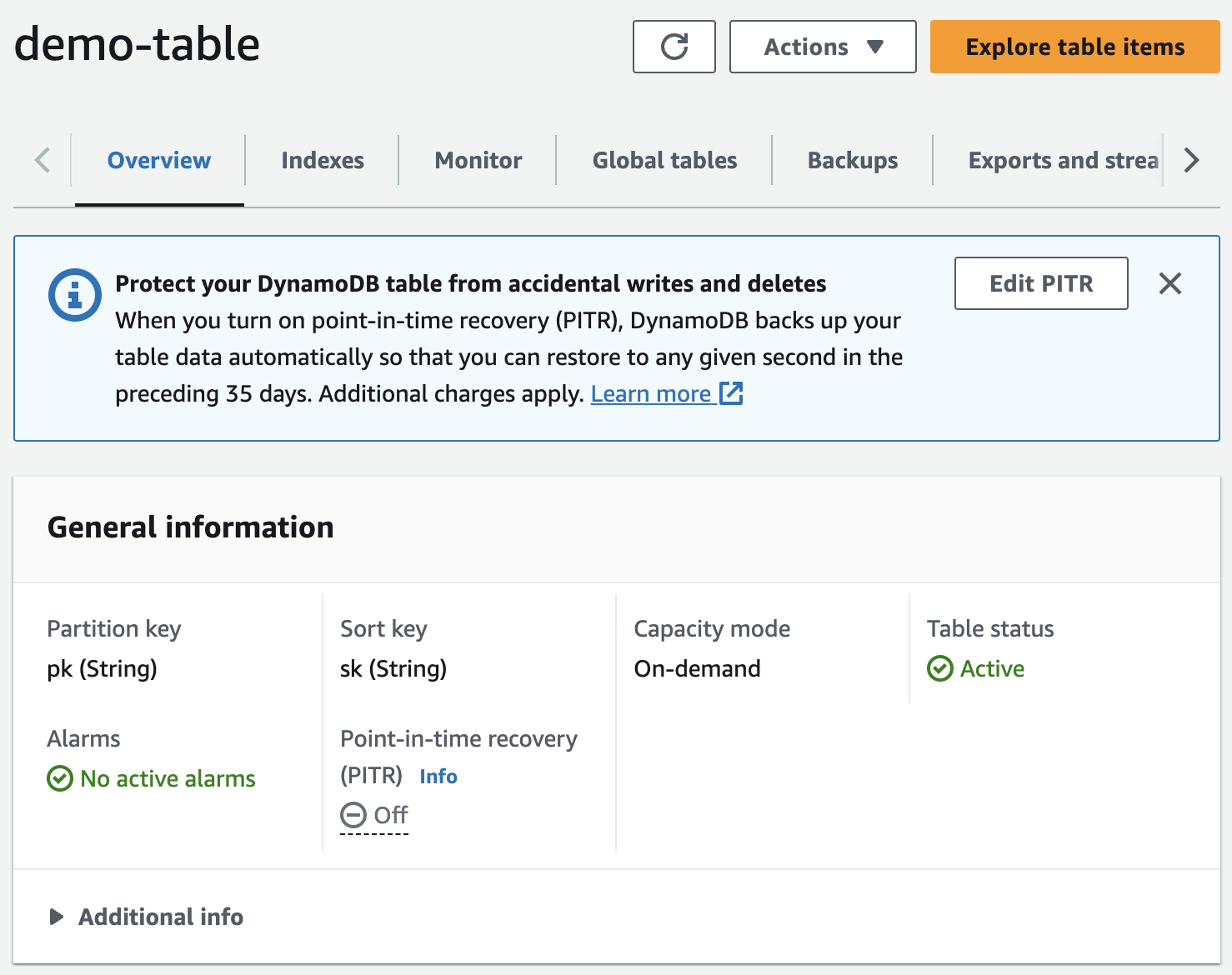
我将在另一篇文章中介绍DynamoDB的计费模式、WCUs和RCUs。
client.ts
import { DynamoDB } from "@aws-sdk/client-dynamodb";
export const TABLE_NAME = "demo-table";
export const REGION = "eu-west-1";
export const dynamoClient = new DynamoDB({ region: REGION });
export const STUDENT_PREFIX = "student#";数据模型
在我们进一步之前,让我们定义一个数据模型,以便在本教程的范围内使用。为了保持上下文的一致性,我选择了模拟DataCamp核心功能的模型。
本教程不会涵盖所有实体。我将在后续文章中对此模型进行扩展。
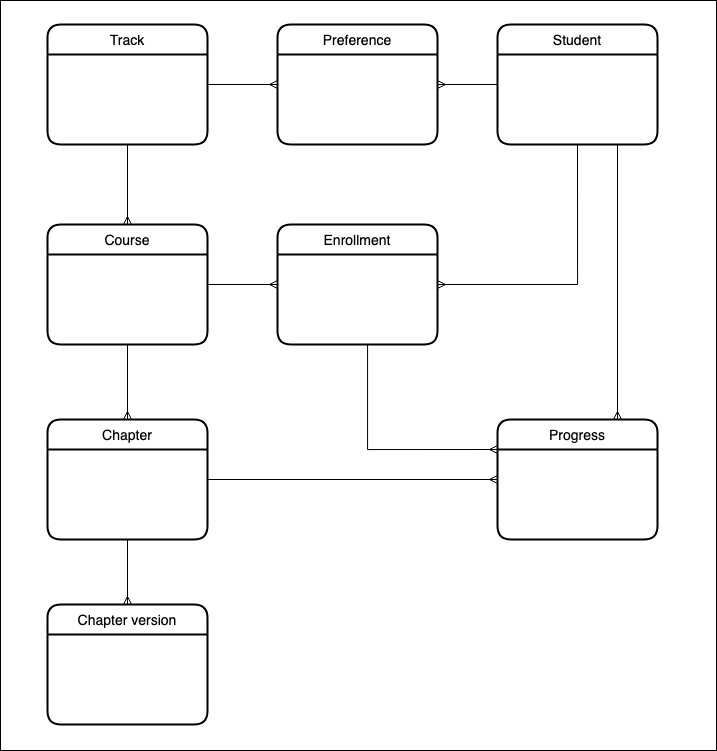
使用DynamoDB进行CRUD操作
要全面了解如何使用DynamoDB设计和建模数据,请参阅我的使用DynamoDB进行单表设计的教程。对于本教程,我将尽量将对DynamoDB工作原理的解释保持在最低限度。需要记住的关键是,DynamoDB使用分区键和排序键来进行高效的数据管理。
分区键
分区键用于将数据分布在多个存储服务器上。选择一个能够均匀分布数据的分区键非常重要,以避免出现“热分区”(数据分布不均匀),这可能会导致性能问题。
常用的分区键选择有助于均匀分布数据的属性包括高基数属性,例如:
- 唯一标识符
- 用户标识符
- 哈希值
- 地理区域
- 基于时间的键
- 复合键
分区键的选择将在很大程度上取决于应用程序的访问模式和数据模型。
排序键
排序键是可选的,可以帮助你在分区内组织数据。使用排序键可以在分区内进行高效的查询和排序。
复合键
复合键由分区键和排序键组成。它们允许您创建丰富的查询模式,例如按范围、时间或其他属性进行过滤。当您的数据访问模式需要复杂查询时,请使用复合键。
热分区
为了减轻热分区的影响,可以考虑使用分片(使用随机前缀作为分区键)、基于时间的分区或均匀分布写入等策略。监控并使用AWS自动扩展来动态调整容量。
student.ts
我们将保持简单,并将学生ID同时用作分区键和排序键。这可能看起来很奇怪,但我们需要保持模式的灵活性,并准备支持各种数据关系和访问模式。我将在接下来的DynamoDB文章中详细介绍这个模型。
import { head, omit, pathOr } from “ramda”;
import { STUDENT_PREFIX, TABLE_NAME, dynamoClient as client } from “../client”;
import { v4 as uuidv4 } from “uuid”;
import {
addPrefix,
attributeMapToValues,
attributeValueToValue,
removePrefix,
valueToAttributeValue,
} from “../utils”;
const entityType = “student”;
export const dynamoRecordToStudent = (record: any) => {
const { pk, …data } = record;
return omit([“sk”], {
…attributeMapToValues(data),
id: removePrefix(attributeValueToValue(pk), STUDENT_PREFIX),
});
};
export const getStudentById = (id: string) =>
client
.getItem({
TableName: TABLE_NAME,
Key: {
pk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
},
})
.then(({ Item }) => (Item ? dynamoRecordToStudent(Item) : undefined));
export const saveStudent = async ({
firstName,
lastName,
email,
}: {
firstName: string;
lastName: string;
email: string;
}): Promise => {
const _id = uuidv4();
const _email = email.toLocaleLowerCase();
const xp = 0;
await client.putItem({
TableName: TABLE_NAME,
Item: {
pk: valueToAttributeValue(addPrefix(_id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(_id, STUDENT_PREFIX)),
firstName: valueToAttributeValue(firstName),
lastName: valueToAttributeValue(lastName),
email: valueToAttributeValue(_email),
xp: valueToAttributeValue(xp),
entityType: valueToAttributeValue(entityType),
},
});
return _id;
};
utils.ts
AWS最新的DynamoDB SDK增加了对数据库中存储的项目的类型安全性,但同时也使得与之一起工作变得更加困难。为了减轻这种痛苦,让我们创建一些辅助函数。稍后当我们看到DynamoDB如何在内部存储数据时,为什么我们需要它们将变得清晰明了。
在src文件夹的根目录下创建一个名为utils.ts的新文件。
import { AttributeValue } from “@aws-sdk/client-dynamodb”;
export const valueToAttributeValue = (value: T): AttributeValue => {
switch (typeof value) {
case “string”:
return { S: value };
case “number”:
return { N: `${value}` };
case “boolean”:
return { BOOL: value };
case “object”:
if (Array.isArray(value)) {
return { L: value.map((item) => valueToAttributeValue(item)) };
}
return {
M: Object.entries(value as any).reduce(
(acc, [key, item]) => ({
…acc,
[key]: valueToAttributeValue(item),
}),
{}
),
};
default:
throw new Error(`Unknown type ${typeof value}`);
}
};
export const attributeValueToValue = (value: AttributeValue): T => {
switch (true) {
case !!value.S:
return value.S as T;
case !!value.N:
return Number(value.N) as T;
case !!value.BOOL:
return value.BOOL as T;
case !!value.L:
return value.L?.map((item) =>
attributeValueToValue(item)
) as unknown as T;
case !!value.M:
return Object.entries(value.M || []).reduce(
(acc, [key, item]) => ({ …acc, [key]: attributeValueToValue(item) }),
{}
) as unknown as T;
default:
throw new Error(`Unknown type ${JSON.stringify(value)}`);
}
};
export const attributeMapToValues = (
items: Record<string, AttributeValue>
): unknown[] =>
Object.keys(items).reduce(
(acc, key) => ({
…acc,
[key]: attributeValueToValue(items[key]),
}),
[]
);
export const removePrefix = (id: string, prefix: string): string =>
id.replace(prefix, “”);
export const addPrefix = (id: string, prefix: string): string =>
`${prefix}${removePrefix(id, prefix)}`;
创建一个新的学生
最后,我们现在可以开始向DynamoDB发送CRUD操作的API调用了!
打开index.ts文件,然后粘贴以下代码,然后从命令行运行yarn dev。
import { getStudentById, saveStudent } from “./domain/student”;
Promise.resolve()
.then(async () => {
const id = await saveStudent({
firstName: “John”,
lastName: “Smith”,
email: “[email protected]“,
});
const john = await getStudentById(id);
console.log(john);
})
.catch((err) => {
console.error(err);
process.exit(1);
})
.then(() => {
console.log(“done”);
process.exit(0);
});
{
"entityType": "student",
"id": "dd4c2ee4-9422-4957-ae6f-f9fff748e5ab",
"firstName": "John",
"lastName": "Smith",
"email": "[email protected]",
"xp": 0
}
现在使用CLI运行以下命令来扫描DynamoDB:
aws dynamodb scan --table-name demo-table --no-cli-pager
从输出中可以看出DynamoDB是如何内部存储和类型化数据的,其中N表示数字类型,S表示字符串类型,这应该能解答你对utils.ts中的代码所产生的任何疑问。
{
“Items”: [
{
“entityType”: {
“S”: “student”
},
“lastName”: {
“S”: “Smith”
},
“email”: {
“S”: “[email protected]”
},
“xp”: {
“N”: “0”
},
“sk”: {
“S”: “student#dd4c2ee4-9422-4957-ae6f-f9fff748e5ab”
},
“pk”: {
“S”: “student#dd4c2ee4-9422-4957-ae6f-f9fff748e5ab”
},
“firstName”: {
“S”: “John”
}
}
],
“Count”: 1,
“ScannedCount”: 1,
“ConsumedCapacity”: null
}
通过电子邮件地址获取学生
如果我们只有学生的电子邮件地址来查找记录,我们可以通过添加全局二级索引来支持这种访问模式。首先,我们需要销毁我们的原始表格(为了以后的terraform更改,我们将引入一个截断表格函数来绕过这一步骤):
terraform destroy
的中文翻译为:
接下来,通过添加以下全局二级索引(GSI)到我们的demo-table来更新terraform:
属性 {
名称 = "gsi1_pk"
类型 = "S"
}
属性 {
名称 = "gsi1_sk"
类型 = "S"
}
全局二级索引 {
名称 = "gsi1"
哈希键 = "gsi1_pk"
范围键 = "gsi1_sk"
投影类型 = "ALL"
}
使用以下命令应用此更改:
terraform apply -auto-approve
的中文翻译为:
接下来,我们需要对保存学生的方式进行轻微修改:
export const saveStudent = async ({
firstName,
lastName,
email,
}: {
firstName: string;
lastName: string;
email: string;
}): Promise => {
const _id = uuidv4();
const _email = email.toLocaleLowerCase();
const xp = 0;
await client.putItem({
TableName: TABLE_NAME,
Item: {
pk: valueToAttributeValue(addPrefix(_id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(_id, STUDENT_PREFIX)),
gsi1_pk: valueToAttributeValue(_email),
gsi1_sk: valueToAttributeValue(addPrefix(_id, STUDENT_PREFIX)),
firstName: valueToAttributeValue(firstName),
lastName: valueToAttributeValue(lastName),
xp: valueToAttributeValue(xp),
entityType: valueToAttributeValue(entityType),
},
});
return _id;
};
注意我们不再明确存储电子邮件,而是将其用作GSI PK值。
我们需要对如何转换DynamoDB学生数据进行微调:
export const dynamoRecordToStudent = (record: any) => {
const { pk, gsi1_pk, …data } = record;
return omit([“sk”, “gsi1_sk”], {
…attributeMapToValues(data),
id: removePrefix(attributeValueToValue(pk), STUDENT_PREFIX),
email: attributeValueToValue(gsi1_pk),
});
};
最后,我们可以使用新创建的GSI gsi1,通过电子邮件地址查询学生记录:export const getStudentByEmail = (email: string) =>
client
.query({
TableName: TABLE_NAME,
IndexName: “gsi1”,
KeyConditionExpression: “#gsi1_pk = :gsi1_pk”,
ExpressionAttributeNames: {
“#gsi1_pk”: “gsi1_pk”,
},
ExpressionAttributeValues: {
“:gsi1_pk”: {
S: email.toLocaleLowerCase(),
},
},
})
.then((res) => head(pathOr([], [“Items”], res).map(dynamoRecordToStudent)));
更新学生
为了更新学生,我们需要使用update方法,并提供分区键和排序键,以唯一标识我们想要更新的项。
export const updateStudent = async ({
id,
firstName,
lastName,
email,
}: {
id: string;
firstName?: string;
lastName?: string;
email?: string;
}) => {
const updateExpressionParts = [];
const ExpressionAttributeValues: Record<string, any> = {};
if (firstName !== undefined) {
updateExpressionParts.push(“#firstName = :firstName”);
ExpressionAttributeValues[“:firstName”] = valueToAttributeValue(firstName);
}
if (lastName !== undefined) {
updateExpressionParts.push(“#lastName = :lastName”);
ExpressionAttributeValues[“:lastName”] = valueToAttributeValue(lastName);
}
if (email !== undefined) {
updateExpressionParts.push(“#gsi1_pk = :gsi1_pk”);
ExpressionAttributeValues[“:gsi1_pk”] = valueToAttributeValue(email);
}
const UpdateExpression = `SET ${updateExpressionParts.join(“, “)}`;
const ExpressionAttributeNames = {
…(firstName && { “#firstName”: “firstName” }),
…(lastName && { “#lastName”: “lastName” }),
…(email && { “#gsi1_pk”: “gsi1_pk” }),
};
await client.updateItem({
TableName: TABLE_NAME,
Key: {
pk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
},
UpdateExpression,
ExpressionAttributeNames,
ExpressionAttributeValues,
});
};
删除数据
首先,让我们明确一点,DynamoDB不支持原生的截断表操作,除非删除整个表然后重新创建(就像我们之前为了引入新的GSI而必须做的那样)。我将在我们的client.ts中添加一个截断方法,但我要强调这仅用于测试目的,不应在生产环境中使用。原因是为了知道要删除什么,我们必须扫描整个表,而DynamoDB中的每个操作都会产生成本,所以如果你有一个拥有一百万个项目的表,那么对你来说,只需删除该表然后重新开始(使用某种数据迁移过程,以便不丢失任何生产数据)会更便宜。这是我们的截断函数:
type AttributeMap = Record<string, AttributeValue>;
const getItemKeyAndValue = (item: AttributeMap, key?: string) =>
key ? { [`${key}`]: item[`${key}`] } : {};
export const truncateTable = async (
client: DynamoDB,
TableName: string,
hash: string,
range?: string
): Promise<void> => {
const { Items } = await client.scan({ TableName });
if (!Items) {
return;
}
const keys = Items.map((item: AttributeMap) => ({
...getItemKeyAndValue(item, hash),
...getItemKeyAndValue(item, range),
}));
if (!keys.length) {
return;
}
await Promise.all(keys?.map((Key) => client.deleteItem({ TableName, Key })));
};
要清空demo-table:
await truncateTable(dynamoClient, TABLE_NAME, "pk", "sk");
要删除特定的学生,我们实际上不想使用SDK中的deleteItem方法。 NoSQL数据库没有引用完整性的概念,如果我们的数据库中有任何其他项目引用了一个不存在的学生,这将是一个问题,而DynamoDB将高兴地删除我们告诉它的任何项目,而不像关系数据库那样有一个安全网确保没有外键引用(并随后为该删除操作抛出错误)。
为了保险起见,我们将实现软删除,并对我们的两个读取函数进行轻微修改。
export const deleteStudent = async (id: string) => {
await client.updateItem({
TableName: TABLE_NAME,
Key: {
pk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
},
UpdateExpression: "SET #deleted = :deleted",
ExpressionAttributeNames: {
"#deleted": "deleted",
},
ExpressionAttributeValues: {
":deleted": valueToAttributeValue(true),
},
});
};
现在,getStudentByEmail的查询应该过滤掉已删除的记录。需要注意的是,这个“过滤”是在客户端而不是在数据库中进行的,这意味着这个查询仍然会产生检索已删除记录的相同成本。
{
TableName: TABLE_NAME,
IndexName: "gsi1",
KeyConditionExpression: "#gsi1_pk = :gsi1_pk",
ExpressionAttributeNames: {
"#gsi1_pk": "gsi1_pk",
},
ExpressionAttributeValues: {
":gsi1_pk": {
S: email.toLocaleLowerCase(),
},
":notDeleted": {
BOOL: false,
},
},
FilterExpression:
"attribute_not_exists(deleted) OR deleted = :notDeleted",
}
函数getStudentById使用getItem,所以我们没有应用过滤表达式的选项,相反我们将明确编写逻辑:
export const getStudentById = (id: string): Promise<Student | null> =>
client
.getItem({
TableName: TABLE_NAME,
Key: {
pk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
},
})
.then(({ Item }) => {
if (!Item) {
return null;
}
const _item = dynamoRecordToStudent(Item);
return _item.deleted ? null : _item;
});
具有ACID合规性的原子更新
DataCamp为每个学生收集XP数据,提供动力、成就感、跟踪整体进度的简便方式以及学生可以与同龄人进行比较的手段。在关系型数据库中,我们有各种工具可以用来操作和聚合数据,但对于NoSQL数据库来说情况并非如此。尽管一些NoSQL数据库(如MongoDB)提供了聚合框架,但这些工具往往在数据库达到大规模时会出现问题,而选择NoSQL的原因通常是因为我们需要支持大量的数据和流量。
在DynamoDB中,原子更新是指以确保原子性、一致性、隔离性和持久性(ACID属性)的方式,在单个项目的某个属性上执行某些更新操作的能力。原子更新是修改特定属性值的操作,即使存在并发更新,也能保证操作的成功。
使用这种技术,当用户完成学习目标时,我们可以轻松地添加经验值。
export const updateStudentXp = async ({
id,
xp,
}: {
id: string;
xp: number;
}) => {
await client.updateItem({
TableName: TABLE_NAME,
Key: {
pk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
sk: valueToAttributeValue(addPrefix(id, STUDENT_PREFIX)),
},
UpdateExpression: "set xp = xp + :inc",
ExpressionAttributeValues: {
":inc": valueToAttributeValue(xp),
},
});
};
如果这段代码看起来很熟悉,那是因为我们已经在deleteStudent函数中使用了这个模式!
结论
在本教程中,我们探讨了亚马逊 DynamoDB 的基础知识,这是一种由 AWS 提供的无服务器、高度可扩展的数据库。DynamoDB 的关键特性,包括无缝扩展性、高可用性和灵活的数据建模,使其成为现代应用的优秀选择。
我们涵盖了创建表、使用Node.js执行CRUD操作以及讨论了原子更新对于维护数据一致性的重要性等基本主题。在整个教程中,我们开发了一个数据模型并实现了与DynamoDB交互的函数。
在您继续学习DynamoDB的过程中,考虑深入研究一些高级主题,如单表设计、性能优化以及用于实时数据处理的DynamoDB Streams。DynamoDB的多功能性和可扩展性使您能够在AWS生态系统中构建高性能的无服务器应用程序。
你可以在Github上找到本教程的完整源代码。祝你编码愉快!
额外学习资料
- DataCamp教程:使用DynamoDB进行单表设计
- DataCamp课程:NoSQL概念
- AWS re:Invent:DynamoDB的高级设计模式
- Rick Houlihan:DynamoDB单表设计基础
- Alex DeBrie:《DynamoDB书籍》
