稳定扩散Web UI(SDUI)是一个用户友好的浏览器界面,用于强大的生成式AI模型,即稳定扩散。这是一个先进的AI模型,能够根据文本描述生成图像或根据文本提示修改现有图像。由AUTOMATIC1111开发的Web UI为用户提供了一个互动平台,无需任何高级技术或编程技能即可与稳定扩散模型进行交互。
您可以在支持CPU和GPU的笔记本电脑或个人电脑上使用Web UI。此外,您还可以选择在服务器上部署自己的模型,让其他人进行探索和实验。它支持几乎所有操作系统和GPU,包括Nvidia、AMD和Intel。这个革命性的工具改变了艺术家在个人电脑上创作高质量艺术的方式,实现了私密且可访问的基于人工智能的创造力。
在本教程中,我们将学习如何在安装有Windows 11和Nvidia GPU的笔记本电脑上下载和设置SDUI。设置完成后,我们将探索Web UI上提供的各种功能,包括扩展和自定义稳定扩散模型。本指南适用于各种背景的个人,包括没有技术专长或青少年。
下载并安装适用于Nvidia GPU的CUDA
您可以在没有GPU或CUDA安装的情况下使用稳定的扩散Web UI。Web UI能够在CPU上运行并提供快速结果。然而,为了获得更快的结果,强烈建议您尽可能使用GPU加速。
本指南仅针对使用Windows操作系统的Nvidia GPU用户。
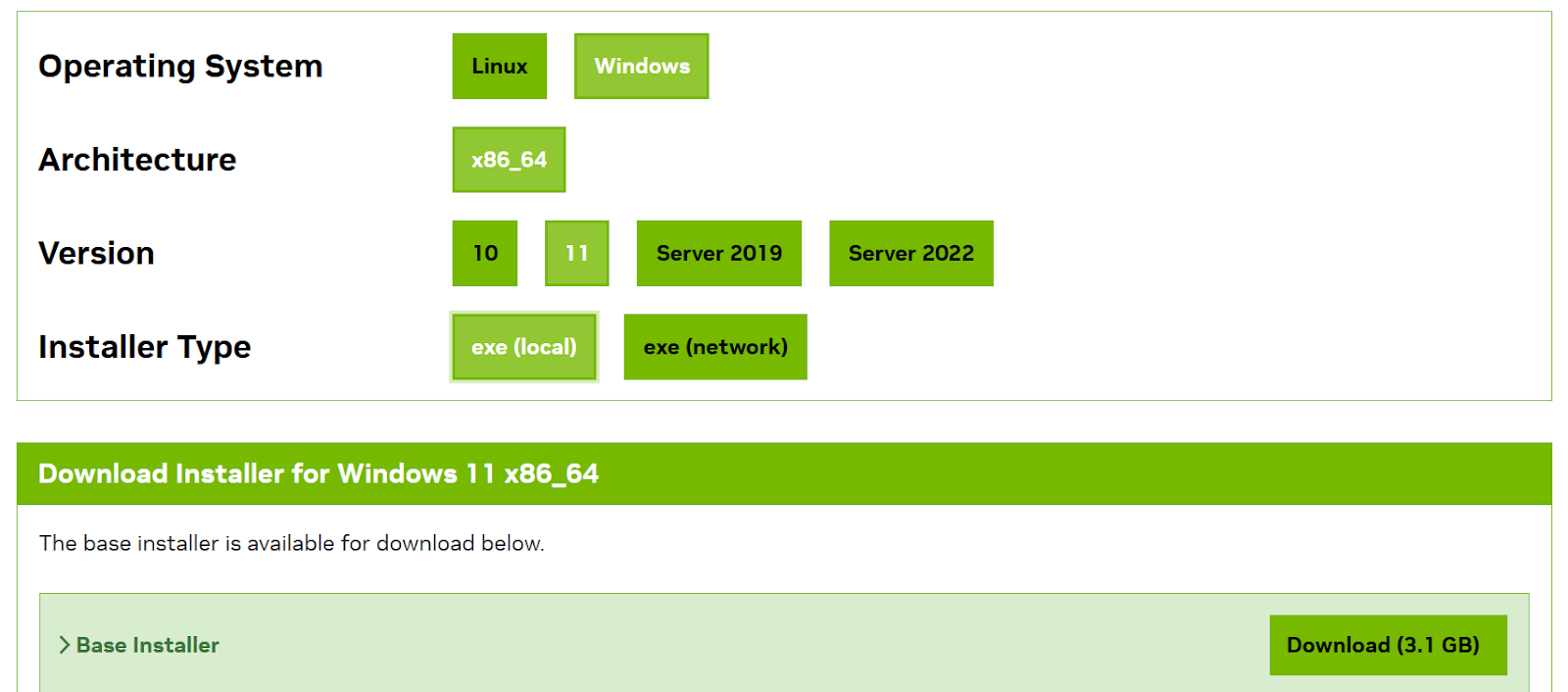
首先,下载并安装最新版本的CUDA Toolkit 12.3。根据您的操作系统选择正确的选项并下载基础安装程序。
这段文字的中文翻译如下:
接下来,安装最新的cuDNN。您可以从Nvidia cuDNN下载zip文件。确保它与正确版本的CUDA Toolkit匹配。
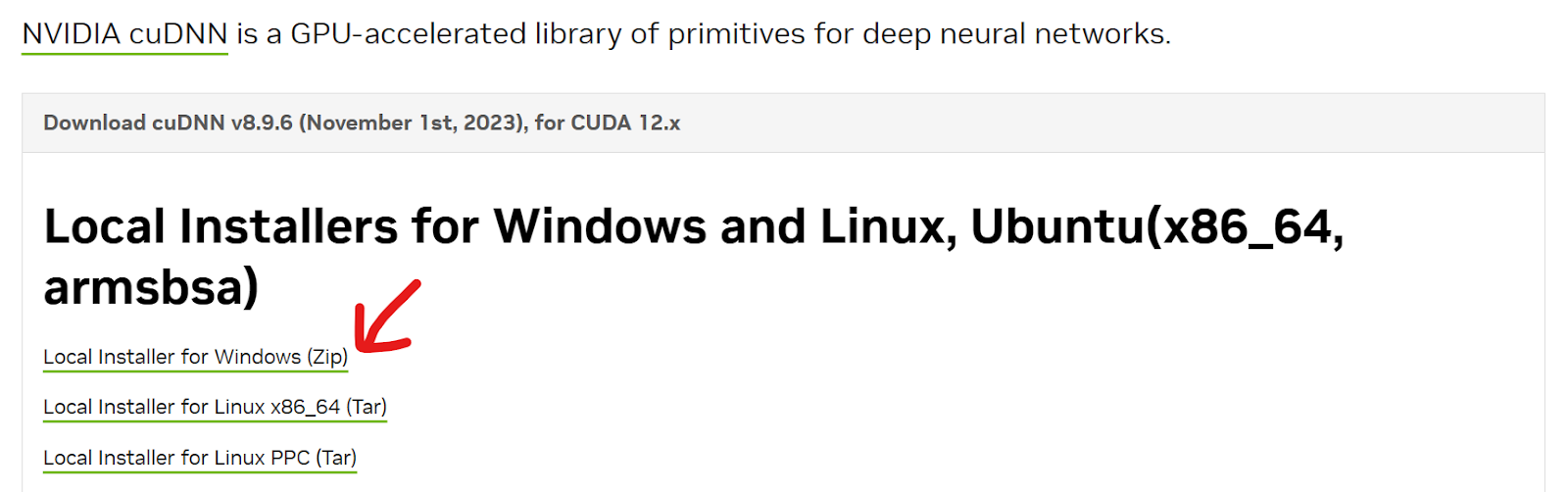
这段文字的中文翻译如下:从zip文件中提取所有文件夹,打开它,并将内容移动到CUDA工具包文件夹中。在这种情况下,目录是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3;但是,对于您来说可能会有所不同。如果遇到提示询问重复文件,请选择”全部替换”。
注意:始终确保您的计算机安装了最新的Nvidia驱动程序,以获得最佳性能。
下载并安装稳定版Diffusion Web UI
在本节中,我们将学习安装SDUI最简单和最自动化的方法。我们将使用二进制分发来安装它,适用于那些无法安装Python和Git的用户。
- 从Release v1.0.0-pre下载
sd.Web UI.zip文件。尽管这是一个较旧的版本,在安装过程中它会自动更新到最新版本。 - 将zip文件的内容解压到您选择的位置。例如,您可以将其解压到
C:\Desktop\Web UI。 - 要更新Stable Diffusion Web UI,只需双击
update.bat文件。 - 之后,双击
run.bat按钮启动Web UI。第一次下载所需文件和模型将需要大约一个小时。 - 一旦下载并安装了所有必要的Python包和Stable Diffusion模型,您将被重定向到带有本地URL“http://127.0.0.1:7860”的浏览器页面。如果链接没有自动打开,请在终端中点击提供的链接。
注意:Stable Diffusion Web UI 存储库提供其他操作系统的安装指南。
Txt2img 标签指南
在您的默认浏览器中,您将看到具有多个选项的用户界面。让我们尝试每个选项以生成高质量的图像。
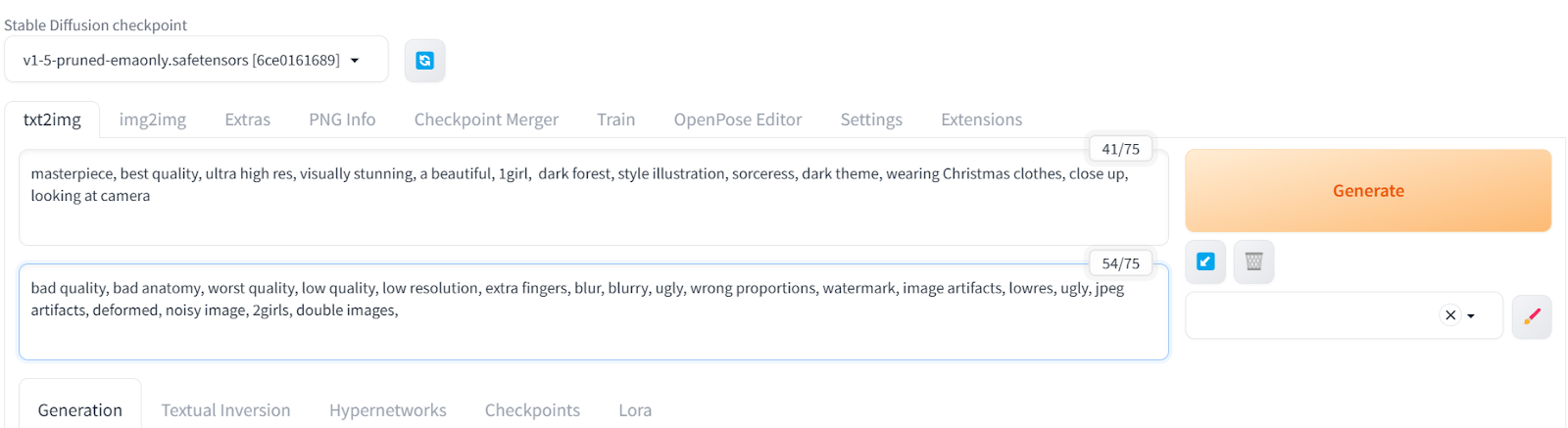
首先,我们将点击txt2img选项卡,并输入积极和消极的提示,生成一个穿着圣诞服装的女孩在黑暗森林中的图片。为了提高图片的质量和风格,还添加了其他关键词。
我们将从一个有限的负面提示开始,并逐渐添加更多关键词来消除图像中的重复畸形。
积极提示:“杰作,最佳质量,超高分辨率,视觉震撼,美丽,一个女孩,黑暗森林,风格插图,女巫,黑暗主题,穿着圣诞服装,特写,看着镜头”
负面提示:“质量差,解剖错误,最差质量,低质量,低分辨率,多余的手指,模糊,丑陋,比例错误,水印,图像伪影,低分辨率,丑陋,JPEG伪影,变形,噪点图像,两个女孩,重复图像,”
这段文字的中文翻译如下:
这段文字的中文翻译如下:
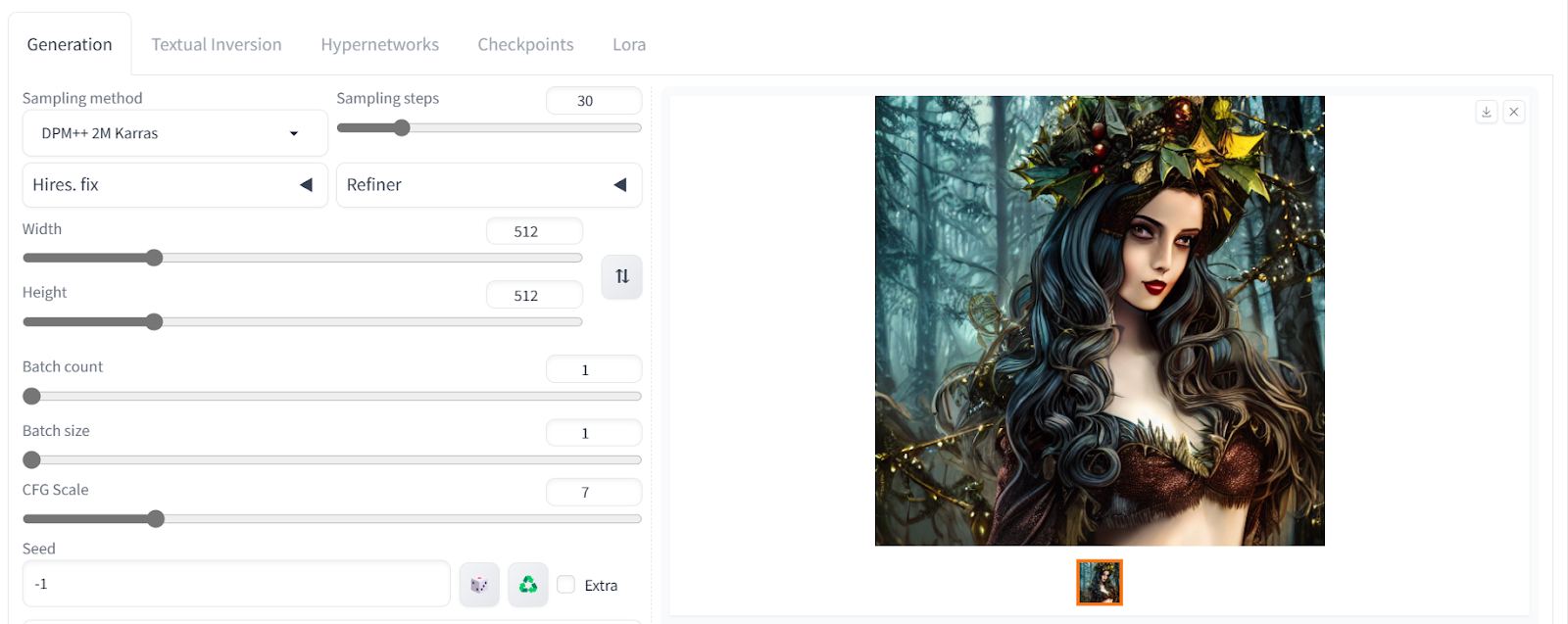
我们生成的艺术作品以卓越的质量描绘了一个身处黑暗的圣诞场景中的女性。
让我们调整高级设置。我们可以更改图像大小并增加采样步骤以添加更多细节。
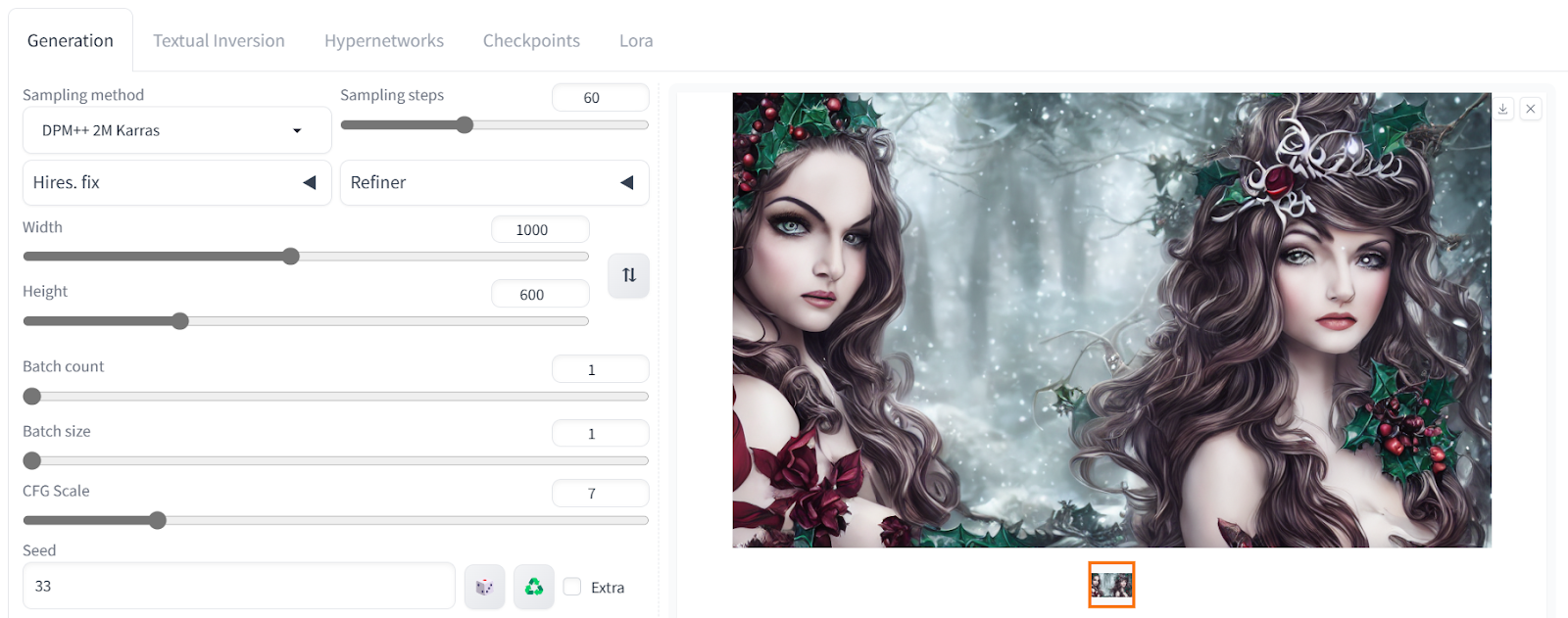
这段文字的中文翻译如下:
这段文字的中文翻译如下:
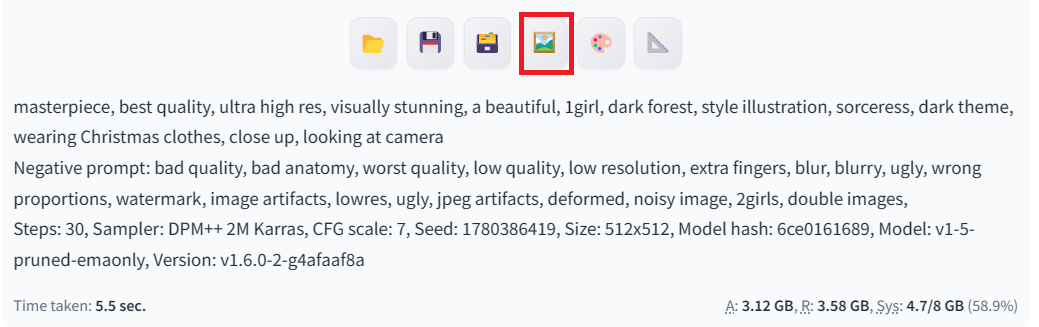
所有生成的图像都带有包括正面和负面提示以及高级设置在内的元数据。您可以使用它来生成相同的结果。
我们现在将通过点击图片下方的照片表情按钮,将图片移动到“img2img”选项卡中,如上所示。
如果你想从零开始构建自己的生成式AI模型,你可以按照这个指南进行操作:使用PyTorch从零开始构建扩散模型。
Img2img标签指南
“img2img”标签允许您上传参考图像,使用不同的提示生成具有不同风格的类似图像。我们添加了一个新的正面提示,并保持负面提示不变,以生成具有不同风格的四个图像。如果您想使用单个提示生成多个图像,可以通过调整生成设置中的”批次计数”来实现。
积极提示:“杰作,最佳质量,超高分辨率,视觉震撼,美丽,1barbie,粉色主题,穿着圣诞服装,特写,看着摄像头,3D,”

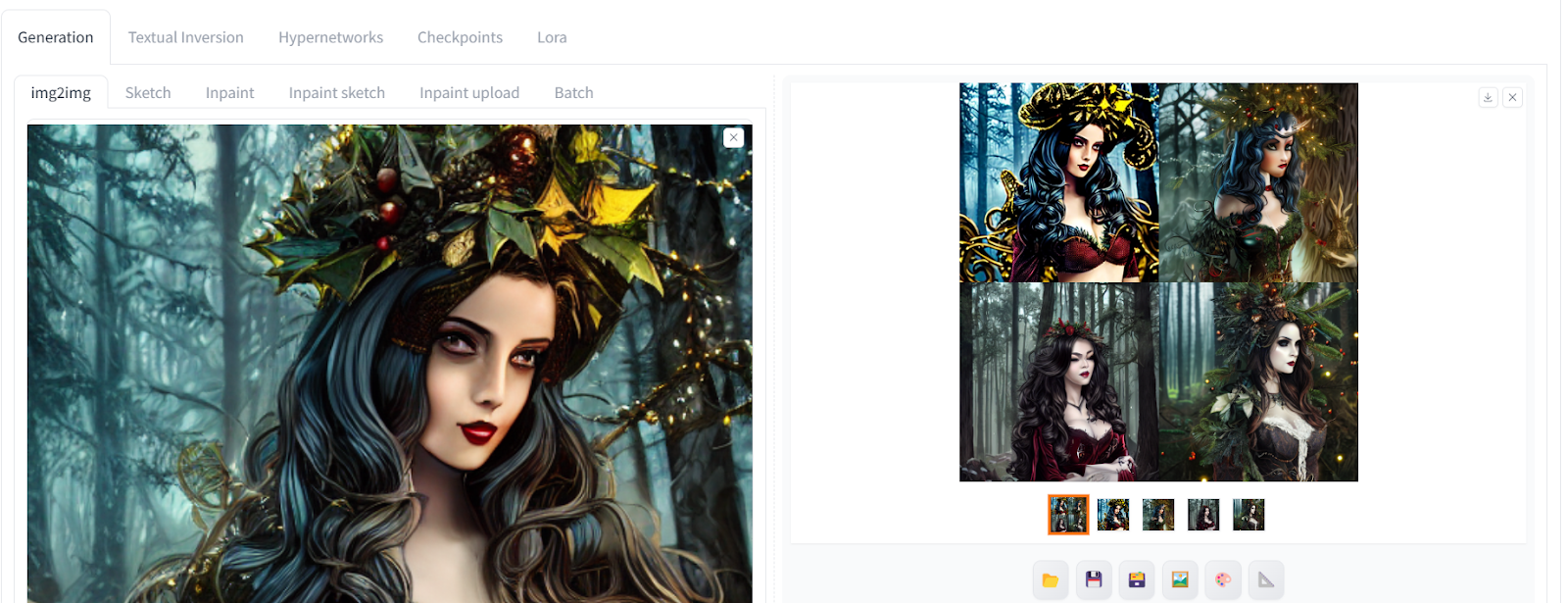
生成的图片看起来令人惊叹,具有不同的风格和道具。有些没有皇冠,有些色彩丰富。
这段文字的中文翻译如下:
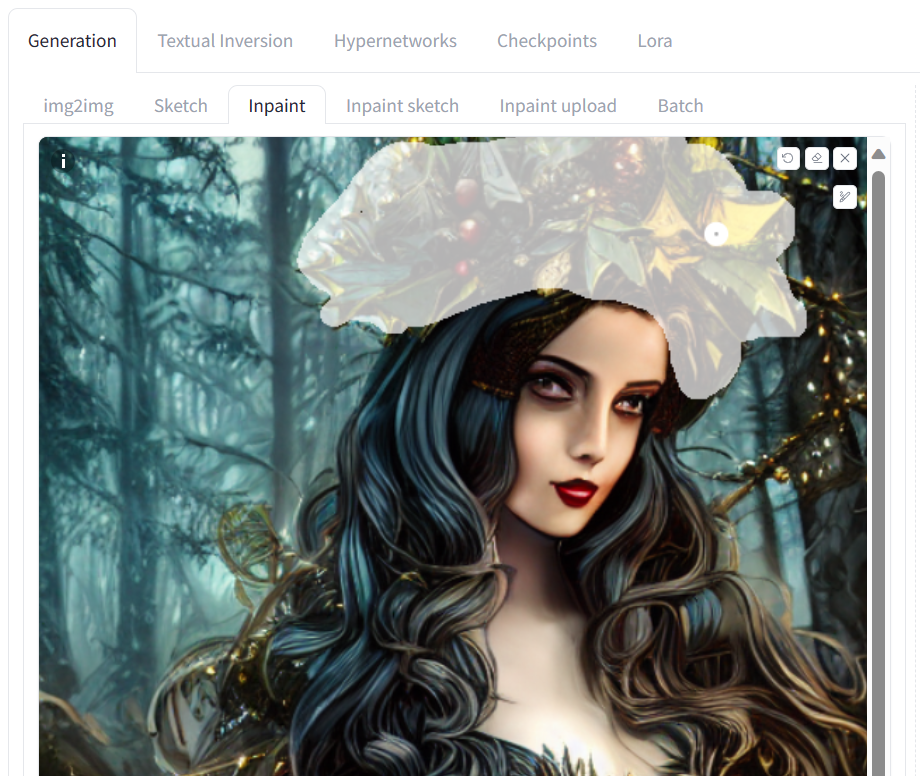
让我们转到“Inpaint”选项卡,尝试更改照片中的木制皇冠。我们可以使用修复工具仅选择女孩的上半部分,并将其更改为金色皇冠。修复功能使我们能够仅修改图像的选定部分。
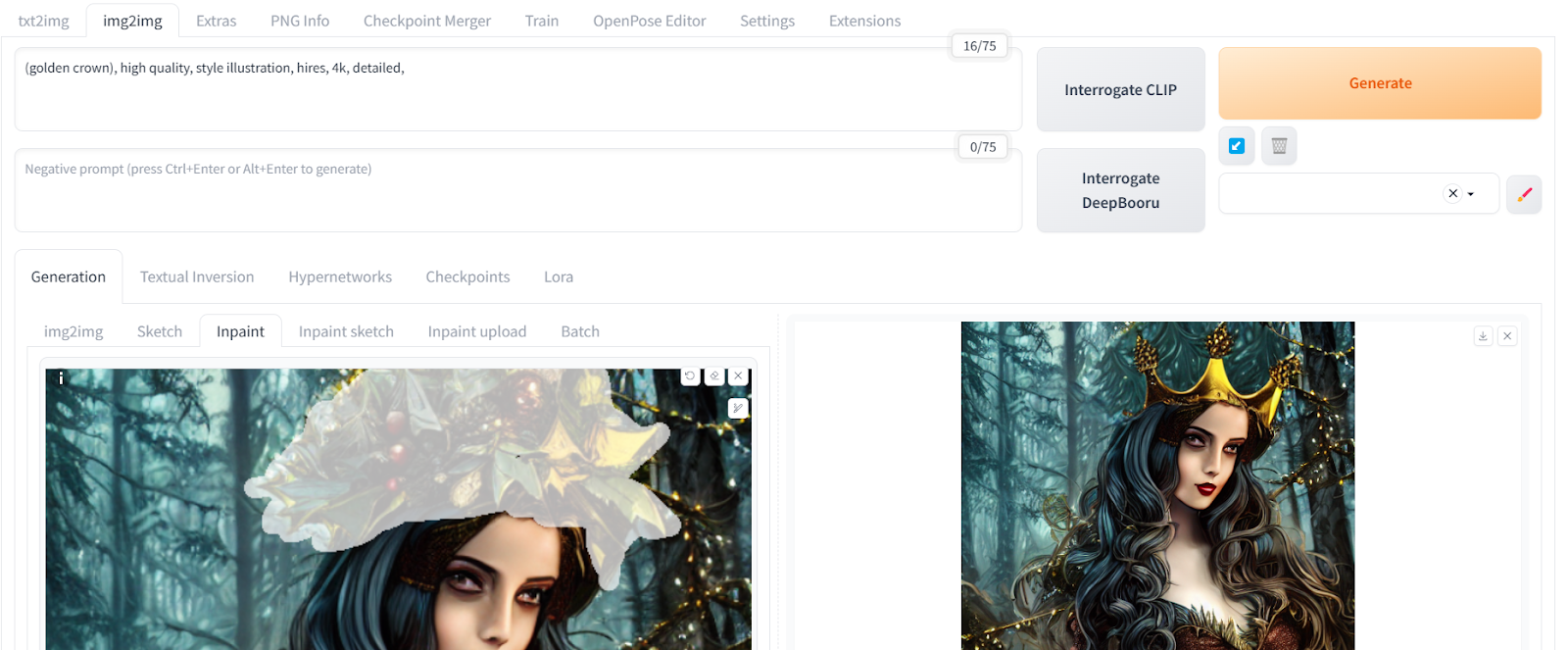
这段文字的中文翻译如下:
这顶新的金色皇冠与图片完美融合,无需使用Photoshop。通过使用一个高亮工具和一个简单的提示,我们能够修改图像的一部分。
使用Upscaler
为了将我们生成的图像进行放大,我们将把图像发送到Extras选项卡。我们将把图像放大四倍,其他保持不变。
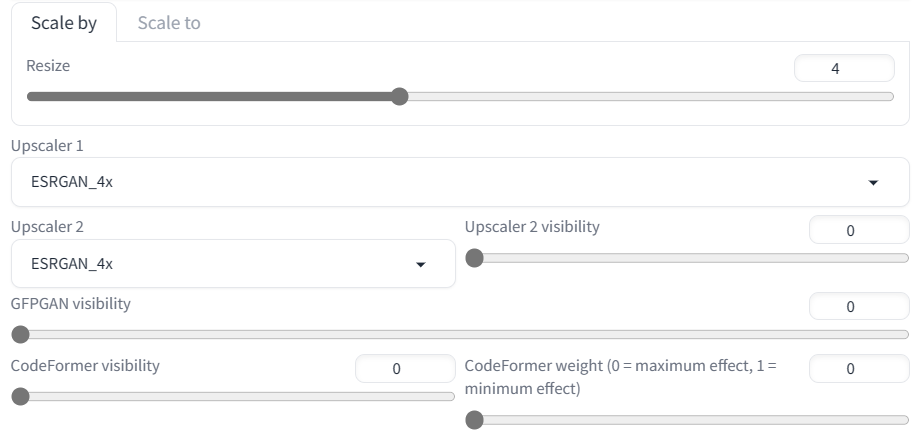
这段文字的中文翻译如下:
之后,我们将点击生成按钮,在几秒钟内将“512X512”转换为“2048X2048”,而不会损失任何图像质量。
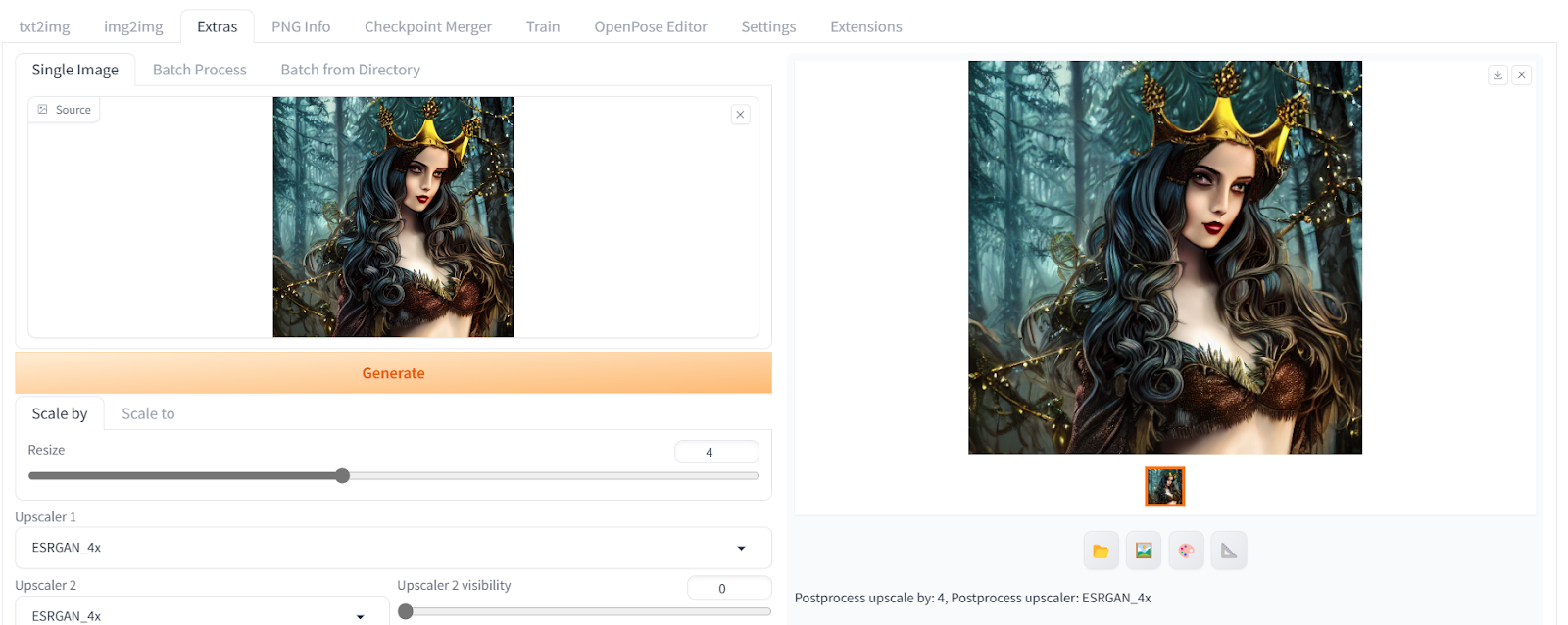
这段文字的中文翻译如下:
您可以通过将图像下载到计算机并访问图像文件属性来检查图像的大小。
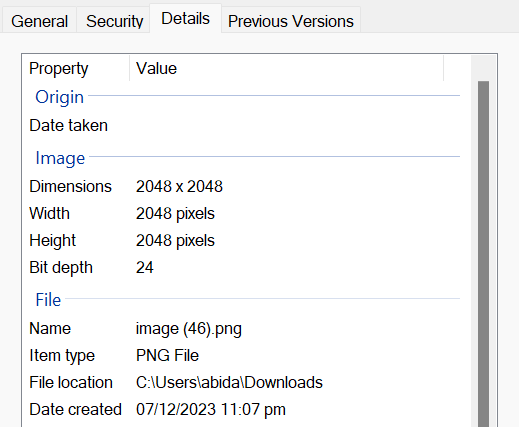
这段文字的中文翻译如下:
PNG 信息
正如我们之前学到的,每个图像都包含元数据,用于指示它是如何生成的。如果你想查看先前生成的图像的信息,可以将其上传到“PNG 信息”选项卡中。从那里,你可以查看正面和负面提示,以及高级设置。
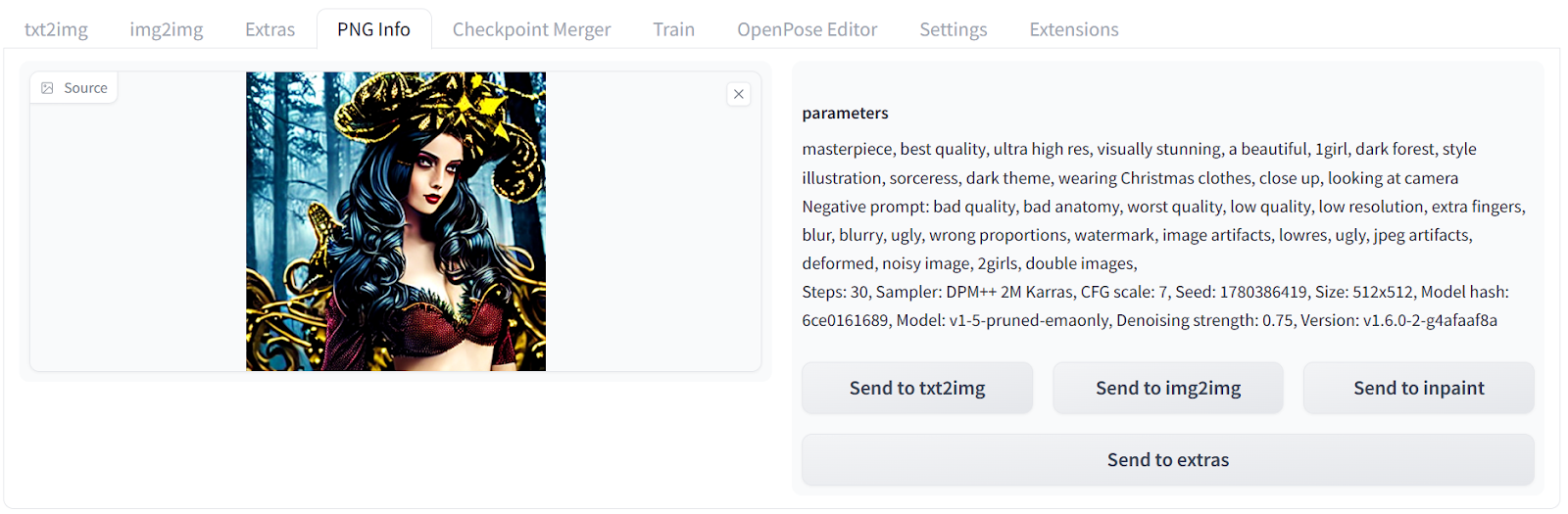
这段文字的中文翻译如下:
安装扩展
要将扩展安装到Web UI中,您需要切换到“扩展”选项卡,然后点击“从URL安装”选项卡。然后,将扩展的存储库URL添加到其中。在我们的例子中,我们使用https://github.com/Mikubill/sd-Web UI-controlnet来安装ControNet扩展。ControNet是一种神经网络架构,可以通过提供额外条件来控制扩散模型。
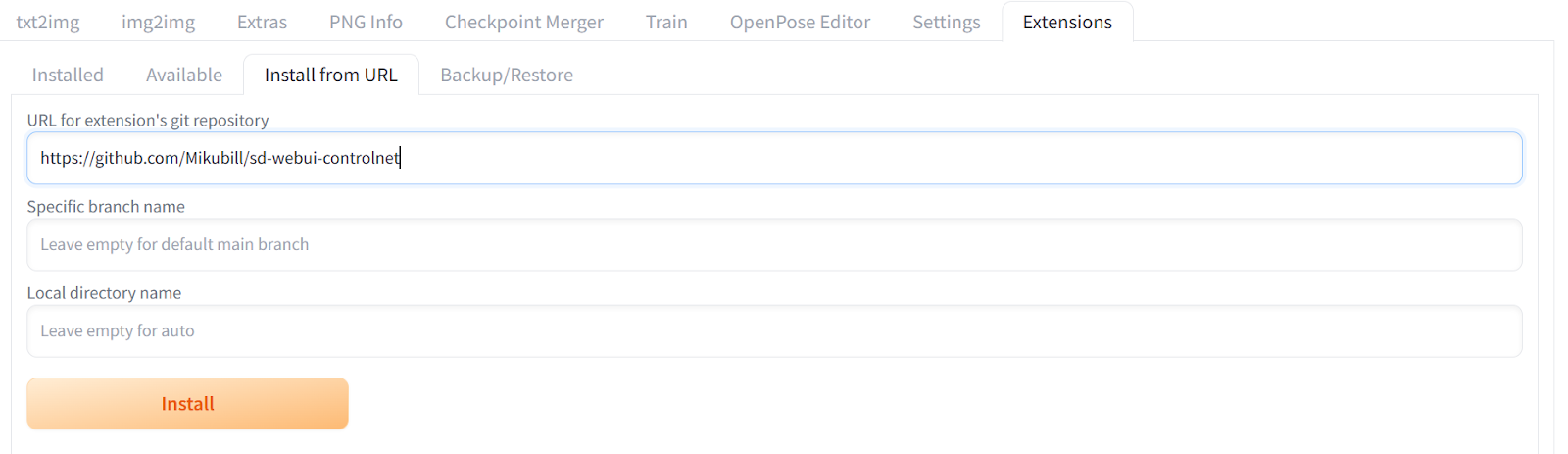
这段文字的中文翻译如下:
- 首先,我们将使用Github的URL安装OpenPose Editor扩展:
https://github.com/fkunn1326/openpose-editor,然后点击安装。 - 从Hugging Face仓库下载OpenPose模型:
hf.co/lllyasviel/ControlNet-v1-1/tree/main。确保下载“control_v11p_sd15_openpose.pth”文件。 - 将模型文件移动到Stable Diffusion Web UI目录下:
stable-diffusion-Web UI\extensions\sd-Web UI-controlnet\models - 成功安装扩展后,您将可以访问
OpenPose Editor。 - 使用鼠标改变棒人的姿势,完成后点击“Send to txt2img”。
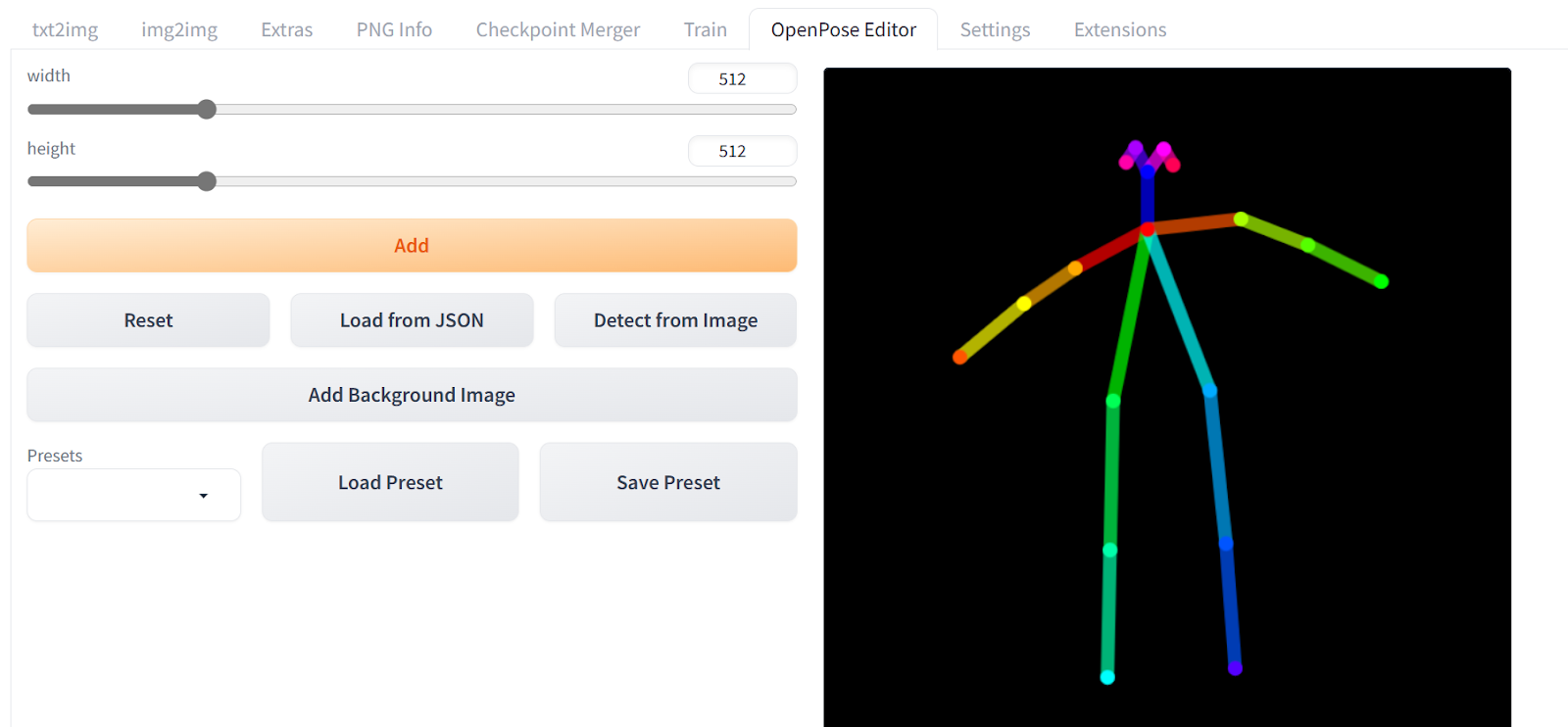
向下滚动并打开ControlNet面板。选择启用、像素完美和OpenPose选项。
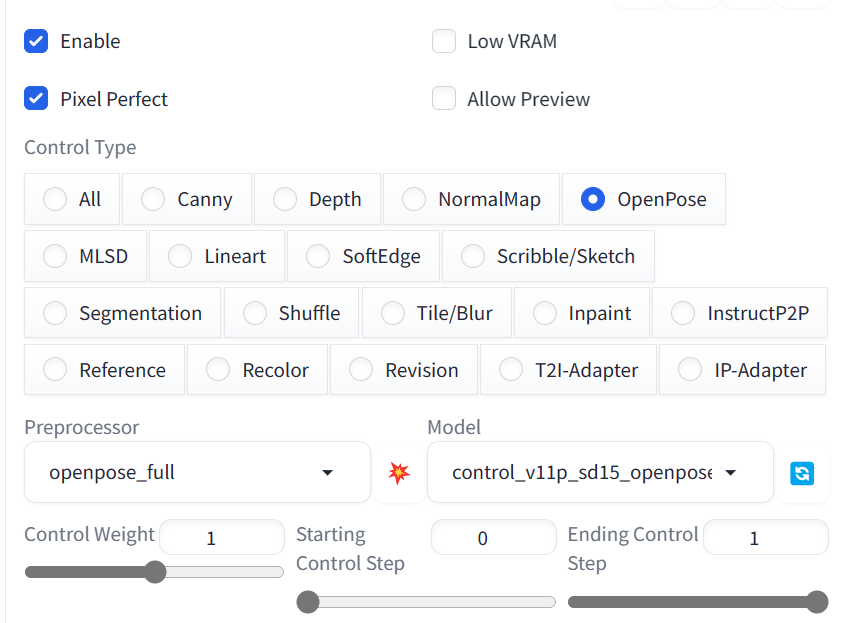
这段文字的中文翻译如下:
之后,向上滚动并编写一个正面和一个负面的提示,以生成四张具有相似姿势的图片。
积极提示:“一个美丽的舞者,在海滩附近,看着摄像机,高质量,雇佣,4k,详细”
负面提示:“最差质量,低质量,低分辨率,单色,灰度,多视角,漫画,素描,解剖错误,畸形,变形,水印,多视角,变异手,水印,面部不好看,”
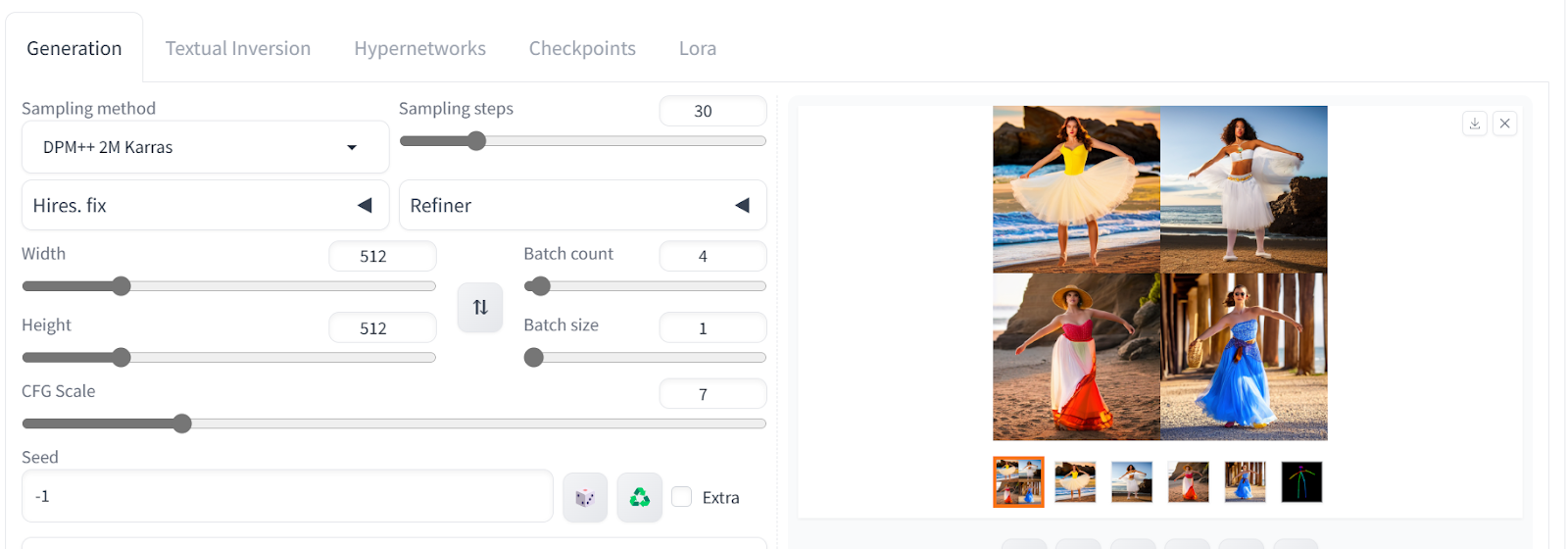
这段文字的中文翻译如下:
我们有四张女性以相同姿势的图片。点击任意图片以将它们作为一张单独的图片查看。
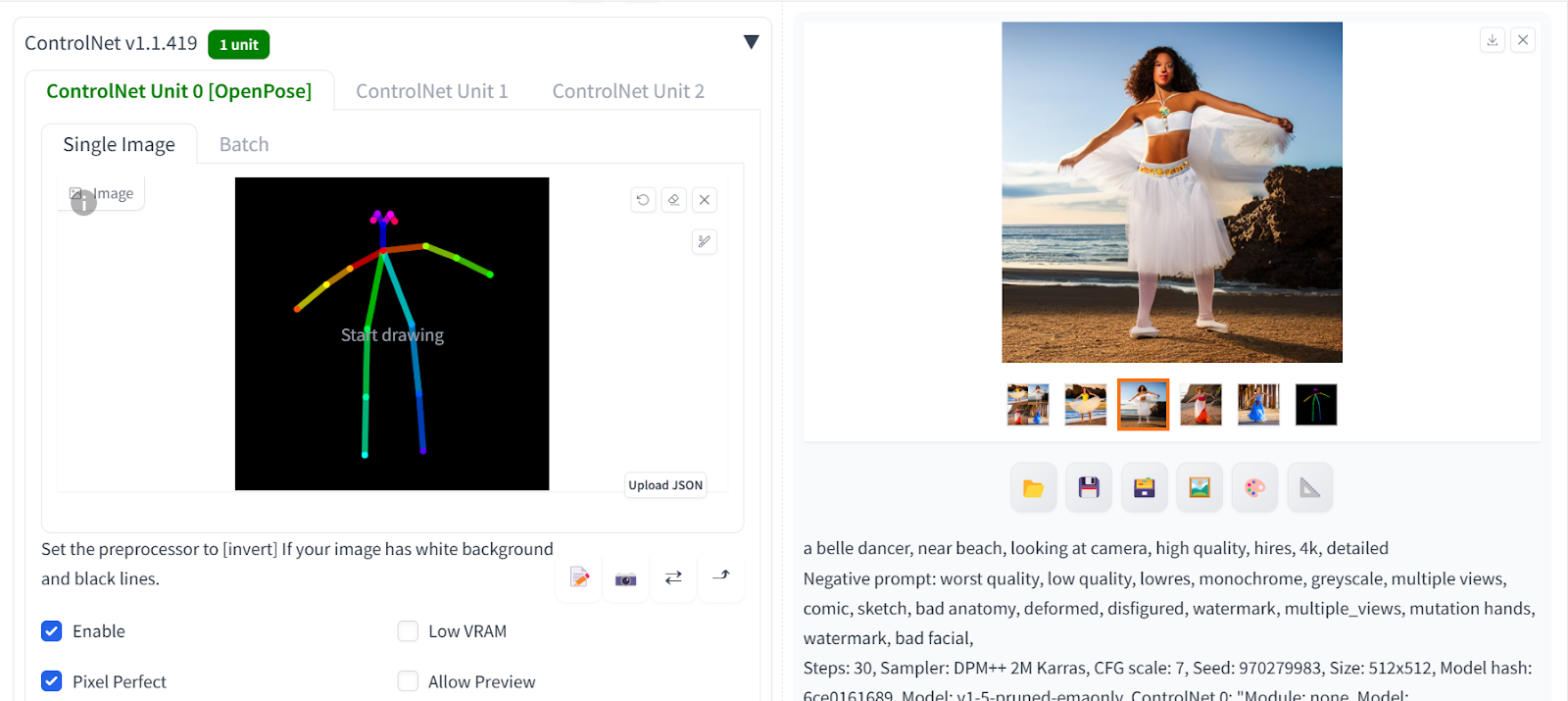
这段文字的中文翻译如下:
使用自定义模型
在本节中,我们将下载并加载在高质量肖像上进行微调的自定义模型,以生成高度逼真的图像。 CivitAI 是一个包含各种开源自定义图像生成模型的平台。您可以轻松搜索特定模型并下载,甚至无需创建帐户。
您可以按照Fine-tuning Stable Diffusion XL with DreamBooth and LoRA指南来对稳定扩散模型进行微调。该指南提供了在Kaggle上使用免费GPU访问进行模型微调的简单步骤。
在我们的案例中,我们将通过在网站上搜索并点击右侧面板上的下载按钮来下载RealVisXL V2.0模型。
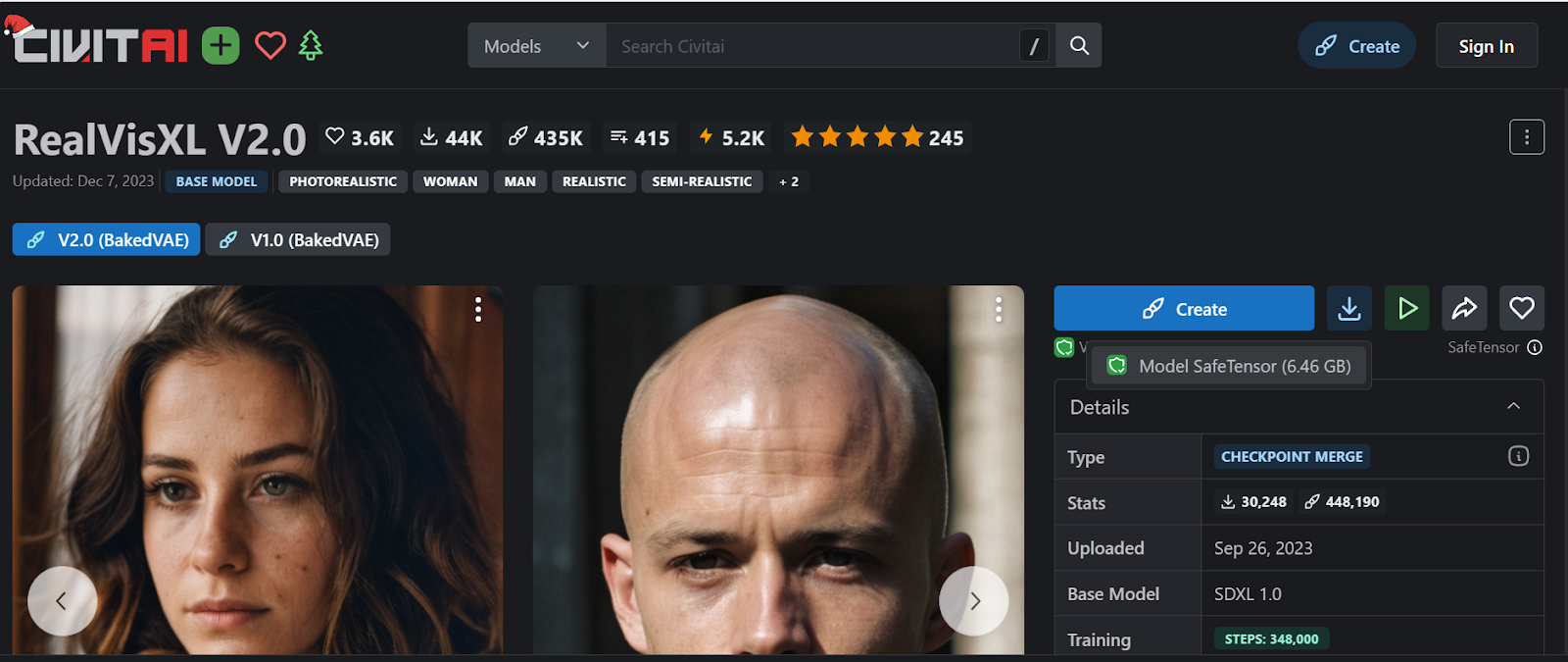
这段文字的中文翻译如下:
下载模型后,将其移动到位于C:\Desktop\Web UI\Web UI\models\Stable-diffusion的稳定扩散Web UI模型目录中。
点击左上角的刷新按钮,然后从下拉面板中选择更新的RealVisXL模型以激活模型。
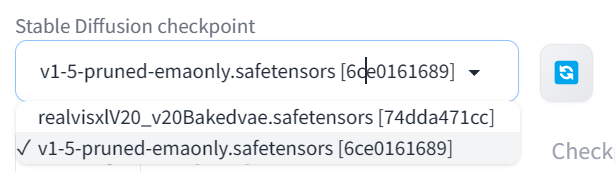
这段文字的中文翻译如下:
注意:如果您正在使用CPU加速的机器,生成一张图片可能需要长达5分钟的时间。因此,请确保您在GPU机器上运行Web UI。
要访问针对ReallVisXL模型优化的正面和负面提示,只需向下滚动模式页面并点击所需的图像。这些图像带有可用于生成逼真图像的元数据。例如,如果我们想生成一张蜘蛛女人抬头面对摄像机的图像,我们可以使用相应的元数据。
积极提示:“一张来自漫威蜘蛛女侠的图片,聚焦、果断、超现实、动态姿势、超高分辨率、锐度纹理、高细节原始照片、详细的面部、浅景深、锐利的眼睛、(逼真的皮肤纹理:1.2)、(雀斑、痣:0.6)、单反相机、胶片颗粒”
负面提示:“(最差质量,低质量,插图,3D,2D,绘画,卡通,素描),张嘴”
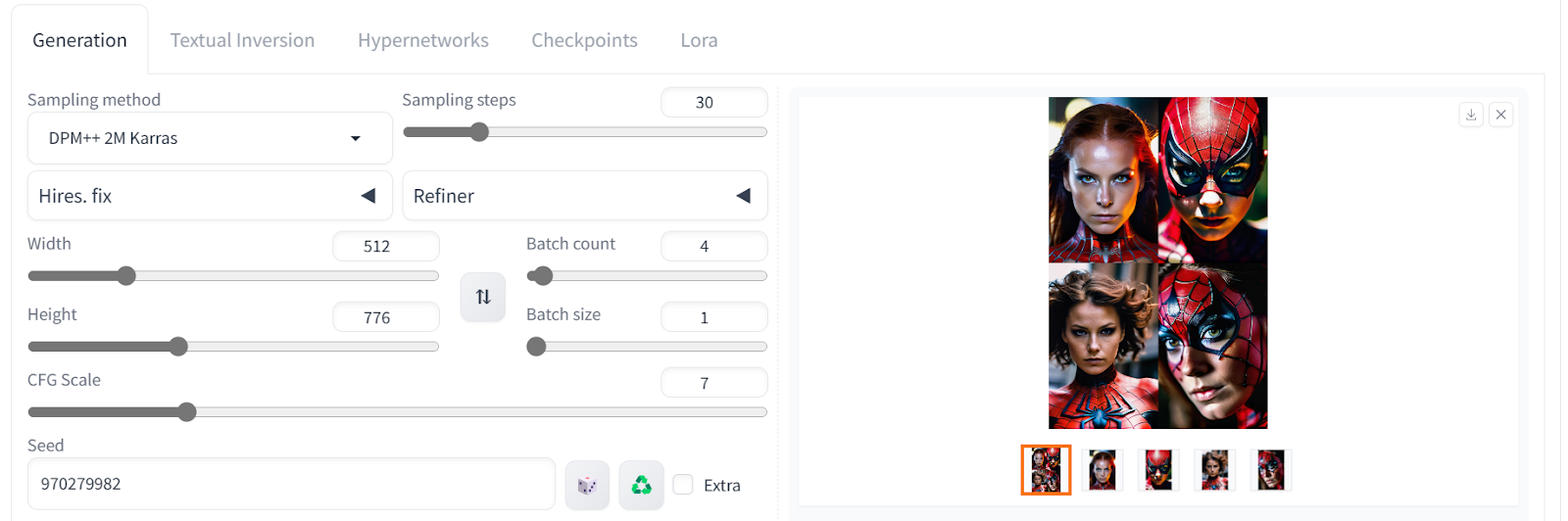
这段文字的中文翻译如下:
结果超乎完美。我们实现了完美的照明、色彩、肤质、头发和面部特征。

这段文字的中文翻译如下:
这是两张最好看的图片。如果你向同事展示它们,他们甚至不会相信这些是生成的图片。
目前,最好的模型是DALLE-3;您可以通过阅读博客《使用DALL-E 3的介绍:技巧、示例和特点》了解它。
结论
稳定扩散网络用户界面为任何人提供了一个方便的方式来利用人工智能图像生成的能力。这个用户友好的界面使得与稳定扩散等先进模型的交互变得容易,即使对于非技术用户也是如此。
在本教程中,我们介绍了如何在Windows上使用Nvidia GPU下载、安装和更新Web UI。通过SDUI设置,我们探索了核心功能,如文本转图像生成、图像编辑、增加分辨率等。我们还安装了扩展来增强工具的功能,使用ControNet控制生成了使用OpenPose模型的图像。最后,我们使用了一个经过微调的模型来生成非常逼真的人脸。通过这个简要的概述,很明显,Web UI解锁了以前没有先进的人工智能和编程技能就无法实现的创造潜力。对于您的下一个项目,尝试使用Python中的扩散器来生成具有人工智能的逼真图像。这将帮助您创建自己的界面并轻松生成图像。
这段文字翻译成中文,不要去除视频和图片标签,保留代码块: ‘
‘