星型模式是由Ralph Kimball在1996年的著作《数据仓库工具包》中引入的。Kimball的新建模技术提供了一种减少数据仓库中存储数据量以及提高查询性能的方法。快进近30年,星型模式已成为数千个现代数据平台中数据仓库设计的基石。在星型模式中,数据被存储为“事实”表和“维度”表。事实表存储捕捉事件的数据,例如零售店的交易、酒店客人的预订或患者就医记录。维度表存储丰富事实表数据的信息。下面的图形使用一些示例将事实表与维度表进行匹配。
|
事实 |
尺寸 在零售店的交易 |
关于该商店中每个商品的详细信息 |
|
酒店的客人预订 |
酒店所有房间的楼层、床位数和浴室数量 |
|
|
患者就医 |
患者信息,如地址和电话号码 |
尽管事实表会不断变化以反映业务事件,但维度表的修改频率较低。但是当它们发生变化时会发生什么呢?如果维度多次更改会怎样?如何维护历史数据?
Cue,慢变维度。
慢变维度,通常称为SCD,是一个用于更新和维护维度表中存储的数据的框架,当维度发生变化时使用。处理变化维度有许多不同的方法,这些技术通常被称为SCD“类型”。我们将深入探讨这些方法的定义,以及典型的用例和实现这些技术的代码。传统上,数据架构师和数据工程师共同合作,规划、开发和维护一个利用缓慢变化的维度的数据模型。然后,数据科学家和分析师将使用这些事实和维度表来训练机器学习流水线,提供仪表盘或在其他数据中心任务中提供帮助。在整个数据行业中,了解缓慢变化的维度的基础知识以及如何使用这些数据有助于减少洞察力的时间,同时提高效率和可靠性。
理解不同类型的SCD
处理慢变维度有很多方法。让我们来看看最常见的三种方法。
SCD Type 1
使用SCD类型1,如果维度表中的记录发生变化,现有记录将被更新或覆盖。否则,新记录将被插入到维度表中。这意味着维度表中的记录始终反映当前状态,不保留历史数据。
一个存储杂货店销售商品信息的表可能使用SCD类型1来处理更改的记录。如果表中已经存在所需商品的记录,它将被更新为新的信息。否则,该记录将被插入到维度表中。
在数据工程领域,如果数据存在则更新,否则插入的做法被称为“upserting”。下面的表格包含了杂货店销售商品的信息。
|
item_id ‘ |
name ‘ |
价格 |
过道 |
|
93201 |
薯片 |
3.99 ‘ |
11 |
|
07879 |
苏打水 |
7.99 ‘ |
13 |
如果将薯片移动到第6走廊,使用SCD类型1来捕捉维度表中的这个变化将产生以下结果:
|
item_id ‘ |
name ‘ |
价格 |
过道 |
|
93201 |
薯片 |
3.99 ‘ |
6 ‘ |
|
07879 |
苏打水 |
7.99 ‘ |
13 |
SCD类型1确保表中没有重复记录,并且数据反映了最近的当前维度。这对于实时仪表盘和预测建模特别有用,因为只有当前状态才是感兴趣的。
然而,由于表中只存储最新的信息,数据从业者无法比较维度随时间的变化。例如,如果没有其他信息,数据分析师将很难确定将薯片移至第6走廊后的收入增长。
SCD类型1使得当前状态的报告和分析变得简单,但在进行历史分析时有一些限制。
SCD Type 2
虽然只反映当前状态的表可能很有用,但有时跟踪维度的历史变化是方便甚至必不可少的。 使用SCD类型2,通过在维度发生变化时添加一行新记录并正确标记此新记录为当前记录,同时相应地标记新的历史记录,来维护历史数据。
说起来容易,但实际上可能不太清楚是什么样子。让我们来看一个例子。
在这里,我们有一个与我们在探索SCD类型1时使用的示例非常相似的表格。然而,增加了一个额外的列。is_current存储一个布尔值;如果记录反映了最新的值,则为true,否则为false。
|
item_id ‘ |
name ‘ |
价格 |
过道 |
is_current |
|
93201 |
薯片 |
3.99 ‘ |
11 |
真 |
|
07879 |
苏打水 |
7.99 |
13 |
真 |
如果薯片搬到6号过道,使用SCD类型2来记录这个变化,将创建一个如下所示的表格:
|
item_id ‘ |
name ‘ |
价格 |
过道 |
is_current |
|
93201 |
薯片 |
3.99 ‘ |
11 |
False |
|
07879 |
苏打水 |
7.99 ‘ |
13 |
真 |
|
93201 |
薯片 |
3.99 ‘ |
6 ‘ |
真 |
添加了一行新数据以反映薯片的位置变化,is_current列中存储了True。为了保留历史数据并准确地描述当前状态,上一条记录的is_current列被设置为False。使用SCD类型1,
但是,如果你想探索薯片销售在位置变化时的反应怎么办?如果一个项目有多个历史记录,仅使用单列就很困难。幸运的是,有一种简单的方法可以解决这个问题。
请看下面的表格。这个维度表包含了与之前相同的信息,但是不同于一个is_current列,它有一个start_date和一个end_date列。这些日期表示一个维度是最新的时间段。由于这个表中的数据是最新的,所以end_date被设置在未来很远的时间。
|
item_id ‘ |
name ‘ |
价格 |
过道 |
开始日期 |
end_date ‘ |
|
93201 |
薯片 |
3.99 ‘ |
11 |
2023年11月13日 |
2099年12月31日 |
|
07879 |
苏打水 |
7.99 ‘ |
13 |
2023年8月24日 |
2099年12月31日 |
如果薯片在2024年1月4日搬到6号过道,更新后的表格将如下所示:
|
item_id ‘ |
name ‘ |
价格 |
过道 |
开始日期 |
end_date ‘ |
|
93201 |
薯片 |
3.99 ‘ |
6 ‘ |
2024年1月4日 |
2099年12月31日 |
|
07879 |
苏打水 |
7.99 ‘ |
13 |
2023年8月24日 |
2099年12月31日 |
|
93201 |
薯片 |
3.99 ‘ |
11 |
2023年11月13日 |
2024年1月3日 |
请注意,第一行的end_date已更新为土豆片在11号过道上最后一天可用的日期。添加了一条新记录,现在土豆片被放在6号过道上。start_date和end_date有助于显示更改是何时进行的,并表示哪条记录是当前记录。
使用这种技术来实现SCD类型1不仅保留了历史数据,还提供了数据何时发生变化的信息。这使得数据分析师和数据科学家能够探索运营变化,进行A/B测试,并支持明智的决策。
SCD Type 3
当处理只预计发生一次变化的数据,或者只对最近的历史记录感兴趣时,SCD类型3非常有用。与将更改后的维度“upsert”或将更改存储为新行不同,SCD类型3使用列来表示更改。这有点难以解释,所以让我们直接进入一个例子。
下表包含了美国各地团队的体育信息。这里,表格包含两列,用于存储当前和历史体育场的名称。由于每个团队都使用原始体育场名称,previous_stadium_name列中填充了NULL。
|
team_id ‘ |
team_name ‘ |
运动 |
current_stadium_name ‘ |
previous_stadium_name ‘ |
|
562819 |
拉斐特鹰队 |
足球 |
三倍X体育场 |
NULL |
|
930193 |
尼亚加拉堡松鼠 |
足球 |
火枪体育场 |
NULL |
如果拉斐特鹰队决定与一家新的赞助商签订为期25年的合约,更新后的表格将如下所示:
|
team_id ‘ |
team_name ‘ |
运动 ‘ |
current_stadium_name ‘ |
previous_stadium_name ‘ |
|
562819 ‘ |
拉斐特鹰队 ‘ |
足球 |
Wabash Field |
三倍X体育场 |
|
930193 ‘ |
尼亚加拉堡松鼠 ‘ |
足球 |
火枪体育场 |
NULL |
为了适应新的体育场名称,“Triple X Stadium”被移动到previous_stadium_name列中,而“Wabash Field”取而代之成为current_stadium_name列中的名称。这项为期25年的新赞助协议很可能会超过正在建设的模型,这意味着记录不太可能再次改变。
使用SCD类型3使得比较当前状态数据和历史数据变得非常简单。每个团队只有一行数据,当前数据和历史数据并排放在两个不同的列中。然而,这意味着只能维护一个单一维度属性的单一历史记录,这可能会有限制,特别是如果数据变化频率超出预期。除了类型1、2和3之外,还有许多其他技术可以实现慢变化维度。当维度永远不应该改变时,使用类型0。类型4将历史数据存储在单独的表中,同时将最新数据持久化存储在维度表中。类型6是类型1、2和3的综合,通常通过结合这些技术的最佳特点来实现。
逐步实施指南:慢变维度
数据仓库中的维度数据
我们已经介绍了慢变维度的基础知识。为了更好地理解如何实施这些技术中的每一种,让我们来看一个例子。
在这个例子中,我们将使用Snowflake来实现零售交易的SCD类型1、2和3。如果你需要对Snowflake进行复习,请查看我们的Introduction to Snowflake course。
有一个事实表,名为sales,和三个维度表,分别是employees、items和discounts。下面是这个星型模式的ERD。
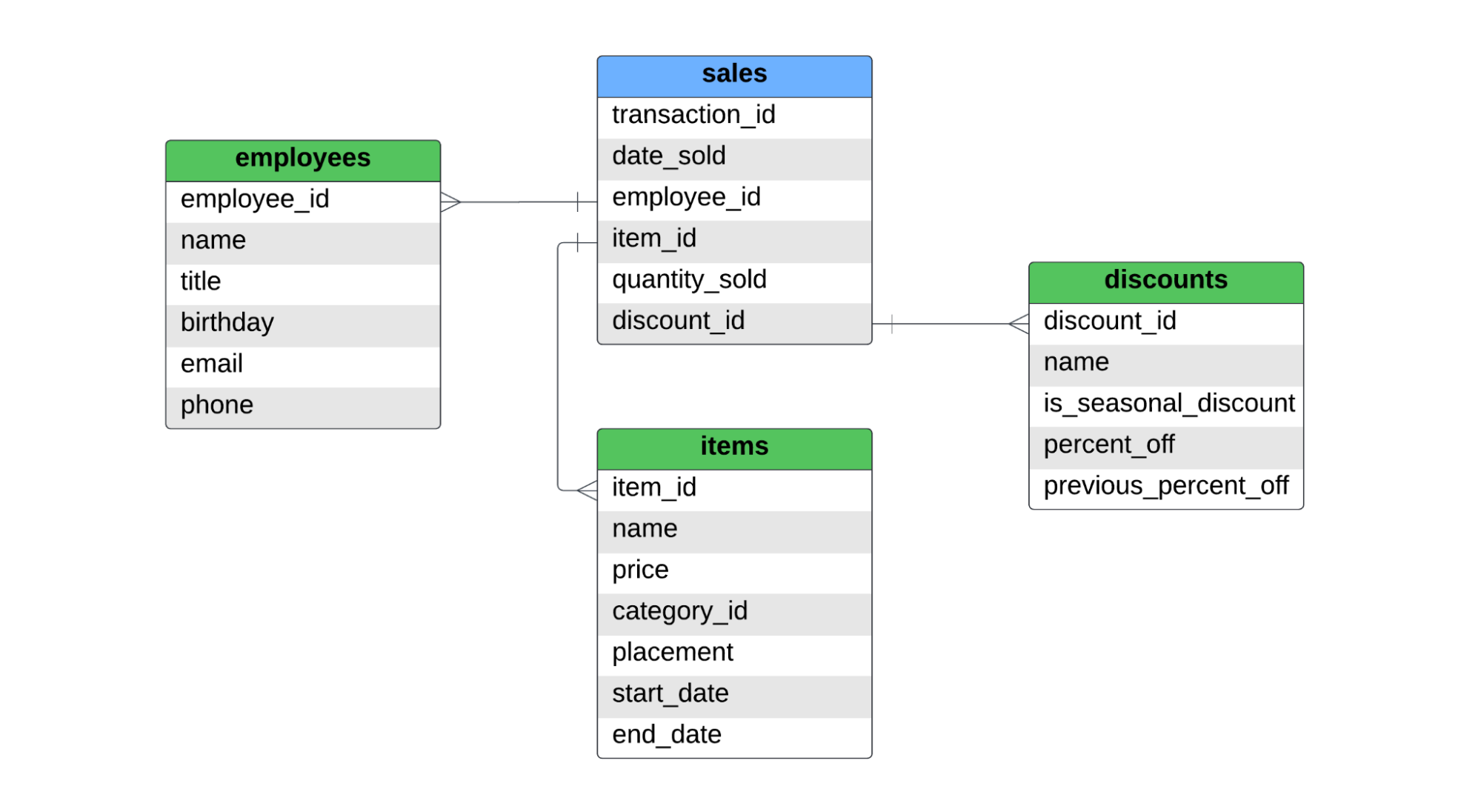
这段文字的中文翻译如下:
销售表记录了每个商品的销售情况。如果一个顾客购买了两件衬衫和一条牛仔裤,事实表中将会有两条记录,因为销售了两种不同的商品。对于SCD类型1、类型2和类型3,我们将涵盖以下内容:
- 维度可能发生变化的常见方式
- 当维度发生变化时更新表格
- 使用Snowflake实现每种SCD技术
我们不会探讨这些表格最初是如何填充的,但通常,在数据仓库上游,一个ETL或ELT流水线从源头提取原始数据,将其转换为所需的模型,并将其加载到最终目的地。
实现SCD类型1
为了练习实现SCD类型1,我们将查看employee表。该表包含有关员工的基本信息,包括姓名、职位和联系信息。它可能包含如下记录。
|
employee_id ‘ |
name ‘ |
标题 ‘ |
生日 |
电子邮件 |
电话 ‘ |
|
477379 ‘ |
Emily Verplank |
经理 |
1989年7月28日 |
‘ |
928-144-8201 |
|
392005 |
乔希·默里 |
收银员 |
2002年12月11日 |
‘ |
717-304-5547 |
使用SCD类型1来捕获这个慢变化的维度,现有记录将被最新的记录覆盖。如果其中一个维度属性发生变化,新记录应该被“upserted”到现有表中。例如,如果Emily的电话号码变为928-652-9704,新表将如下所示:
|
employee_id ‘ |
name ‘ |
标题 ‘ |
生日 |
电子邮件 |
电话 ‘ |
|
477379 ‘ |
Emily Verplank |
经理 |
1989年7月28日 |
‘ |
928-652-9704 ‘ |
|
392005 ‘ |
乔希·默里 |
收银员 |
2002年12月11日 |
‘ |
717-304-5547 |
要使用Snowflake完成这个操作,我们将使用MERGE INTO命令。 MERGE INTO允许数据专业人员提供匹配键和条件。如果匹配键和条件满足,记录可以使用UPDATE关键字进行更新。否则,可以INSERT一条记录,或者停止执行。
在开始使用MERGE INTO命令之前,我们首先要创建并向名为stage_employees的表中添加记录。这个表将包含自上次刷新employees表以来已更新的所有记录。我们可以使用以下语句来完成这个操作。
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'[email protected]',
'928-652-9704'
);
现在,我们可以使用Snowflake的MERGE功能来“upsert”现有记录。
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
上面的代码是将employees表和stage_employees表之间的数据合并的关键。另一个条件没有设置,这意味着如果employee_id匹配,name、title、email和phone这些维度属性将会被更新为stage_employees表中对应的值。如果stage_employees中的记录与employees表中的任何记录都不匹配,则该记录将被插入到employees表中。
实现SCD类型2
实现SCD类型2比SCD类型1要复杂一些。虽然它不像覆盖现有记录或插入新记录那样简单,但我们仍然可以使用Snowflake的MERGE INTO逻辑来解决这个问题。请看下面的维度。
|
item_id ‘ |
name ‘ |
价格 |
category_id ‘ |
放置 |
开始日期 |
end_date ‘ |
|
667812 |
袜子 |
8.99 |
156 |
第11过道 |
2023年8月24日 |
NULL |
|
747295 ‘ |
运动球衣 |
59.99 |
743 |
第8走廊 |
2023年2月17日 |
NULL |
这个表格包含了零售店销售的特定物品的信息。维度属性包括物品的名称、价格和摆放位置,以及物品所属类别的外键。为了实现SCD类型2,我们需要使用start_date和end_date来维护历史和当前数据,这次需要进行“upsert”操作。
假设在NFL(美国国家橄榄球联盟)赛季开始时,运动球衣被移到商店前面,以便顾客进来时更容易看到。除了新的位置,该商品的价格也有所降低。为了说明这种运营行为,并保留历史数据,现有记录会被更新并添加一个结束日期,同时插入一个新记录。快来看看吧!
|
item_id ‘ |
name ‘ |
价格 |
category_id ‘ |
放置 |
开始日期 |
end_date ‘ |
|
667812 |
袜子 |
8.99 |
156 |
第11过道 |
2023年8月24日 |
NULL |
|
747295 ‘ |
运动球衣 |
59.99 |
743 |
第8走廊 |
2023年2月17日 |
2023年11月13日 |
|
747295 ‘ |
运动球衣 |
49.99 |
743 |
显示入口 |
2023年11月13日 |
NULL |
与之前类似,我们首先创建一个名为stage_items的表。这个表将存储用于实现相应的items维度中的SCD类型2的记录,其形式如上所示。一旦创建了stage_items表,我们将插入一条包含运动球衣的放置和价格变动的记录。
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'运动衫',
49.99,
743,
'入口展示',
'2023-11-13',
NULL
);
现在,是时候使用Snowflake的MERGE INTO功能来实现SCD类型2了。这比之前的例子要复杂一些,需要一些思考。由于只有在不满足匹配条件时才能插入记录,我们需要分两步来完成。首先,我们将创建以下三个语句的匹配条件:
items表和stage_items表中的item_id必须匹配stage_items表中的start_date必须大于items表中的start_dateitems表中的end_date必须为NULL
如果满足这三个条件,则必须更新items表中的原始记录。请注意,items.end_date列将不再是NULL,而是取stage_items表中的start_date的值。如果记录在第一个语句中不匹配,则没有逻辑。
接下来,我们将使用一个单独的MERGE INTO调用来插入新记录。这有点困难。要插入新记录,匹配条件必须不满足。在这个例子中,我们可以通过检查两个表中的items_id是否匹配,并且items表中的end_date是否为NULL来实现这一点。让我们进一步分解一下。
- 如果
items_id匹配,并且items.end_date为NULL,则items表中已经存在一条最新的记录。这意味着不应该插入新记录。 - 如果两个表中的
item_id没有匹配,那么匹配条件将不会满足,将插入一行新记录。这将是items表中该item_id的第一条记录。 - 如果
stage_items表中的item_id与items表中具有相同item_id的记录匹配,并且end_date不是NULL,则将插入新值。这样可以保留历史数据,并确保items表中存在当前记录。
下面是实现代码,使用两个MERGE INTO语句首先更新现有记录,然后插入最新数据。
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- 更新现有记录
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
实现SCD类型3
最后,我们将介绍如何使用新的维度实现SCD类型3。在我们的示例中,discounts表存储了客户在结账时可以使用的某些折扣的信息。该表包括折扣的ID,以及名称、折扣百分比和是否为季节性折扣的分类。以下是可能存在于discounts表中的两条记录的示例。
|
discount_id ‘ |
name ‘ |
is_seasonal |
percent_off ‘ |
previous_percent_off ‘ |
|
994863 ‘ |
奖励会员 |
False |
10 |
NULL |
|
467782 |
员工折扣 |
False |
50 |
NULL |
由于零售商不希望折扣经常变动,这个维度非常适合采用类型3的方法来处理慢变化维度。如果通过折扣提供的折扣百分比发生变化,先前的折扣百分比将移至previous_percent_off列,而新值将占据percent_off列的位置。
这样可以在保留历史数据的同时,在percent_off列中显示最新的值。
|
discount_id ‘ |
name ‘ |
is_seasonal |
percent_off ‘ |
previous_percent_off ‘ |
|
994863 ‘ |
奖励会员 |
False |
10 |
NULL |
|
467782 |
员工折扣 |
False |
35 |
50 |
要在Snowflake中实现这一点,我们将创建一个stage_discounts表,并插入一条记录。这条记录将包括新的percent_off。
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
再次,我们将使用MERGE INTO来实现SCD类型3。匹配条件很简单;如果discounts和stage_discounts表中的discount_id匹配,并且percent_off的值不同,那么discounts表中的现有记录将被更新。现有的percent_off值将被移动到previous_percent_off字段中,然后如果两个表中的discount_id不匹配,则插入一个新记录,值为NULL。请注意,这些记录不是时间限定的,只能维护一个历史值percent_off。
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
请记住,SCD类型3最适合用于很少更改的数据,并且只保留最近的历史记录。如果预计会对维度进行多次更改,最好使用SCD类型2。
实施SCD时的常见挑战
重复数据
在实施任何慢变维度技术时,要牢记可能存在重复数据的可能性。有两种类型的重复数据需要注意:批内重复和批间重复。让我们来详细了解一下。
批内重复
批内重复是指存在于不同数据批次之间的重复数据。如果存在一个维度表,并且两个用于更新该表的文件可能包含重复记录。
为了处理这个问题,重要的是在“upserting”和/或加载数据到维度表时给你的逻辑添加约束。在上面的例子中,我们添加了逻辑来确保没有重复数据。这包括:
- 仅在使用SCD类型1时插入数据,如果具有匹配的
employee_id的记录不存在 - 在我们的SCD类型2实现中添加额外条件,以确保如果表中已经有当前记录,则不再插入数据
- 在更新现有记录之前,检查项目和
stage_items表中的percent_off值是否不同
批间重复
批间重复是指在同一批数据中发生的重复。例如,如果一个文件包含两个条目来更新维度表中的单个记录,必须采取预防措施。与批内重复一样,重要的是向实现SCD类型1、2或3的逻辑添加约束。
如果同一文件中存在冲突的记录,这些记录必须以某种方式进行区分。这可以是有关记录的元数据或源提供的时间戳。无论您选择以哪种方式处理这些重复记录,都很重要的是记录下您的假设,并与团队一起审查,以确保生成的维度准确捕捉操作值。
确保数据完整性
有时候,数据在不应该改变的情况下发生了变化。通过我们目前讨论的三种SCD技术,这可能导致数据被覆盖,添加新行,或者在新列中填充数据。
我们已经讨论了确保重复数据不会进入维度表的方法。除了重复数据之外,实施处理缓慢变化维度技术的数据专业人员还需要注意以下问题:
- 错误地撤销的更改
- 对尺寸进行极其频繁或大量的更改
- 格式错误的记录
虽然上述情况并非都可以直接在用于维护维度表的代码中捕捉到,但拥有强大的数据质量规则和过程来监控维度可以帮助确保数据完整性得到维护。
SCD高级主题
优化大型数据集的SCD实现
在上面的零售示例中,我们处理的数据集只包含几行数据。在实际生产环境中,这些维度表可能包含数百甚至数千条记录。这在实现SCD类型2时非常常见,特别是当维度经常发生变化时。
随着维度表中行数的增加,对于数据从业者来说,将性能放在设计和实施计划的首要位置非常重要。以下是使用Snowflake优化大型数据集的SCD实现的几种方法:
- 在目标表上使用约束,如主键,以减少
MERGE语句处理的数据量 - 利用微分区和数据聚类来减少
MERGE语句处理的数据量 - 使用查询计划和查询概要来识别和解决查询瓶颈
- 在适当的情况下考虑使用
UPDATE和INSERT语句,而不是MERGE语句
在历史准确性和系统性能之间取得平衡
如果维度数据集变得非常庞大,导致系统性能受到影响,可能需要在历史准确性和系统性能之间做出权衡。如上所述,当实施SCD类型2时通常会出现这种情况。
如果记录经常变化,表中的行数可能会迅速增加。在这种情况下,使用SCD类型2来维护维度数据可能不再明智。
切换到使用SCD类型1或类型3可能提供类似的功能,同时系统性能显著提升。但这样做的代价是历史数据的不完整表示。在改变实施SCD方法之前,请与您的团队一起权衡这种权衡。
编排慢变维度
运行一次性查询来实现维度表的慢变维度(SCD)是相对容易的。然而,在生产环境中以编程方式运行此过程以维护该维度则需要一些思考。诸如Apache Airflow之类的工具非常适合编排这些过程,并提供了一层监控和警报,以确保正常性能。通过将用于更新维度表的逻辑参数化,Airflow可以用于在数据平台上按计划启动进程,取代数据从业者的手动努力。
除了Airflow之外,还可以使用Mage、Prefect或Dagster等工具来编排实现慢变维度。如果这些工具不容易获得,也可以使用自制的编排工具。
结论
掌握慢变维度(SCD)是一项非常有用的技能,尤其是在创建自己的数据模型时。
在本文中,我们介绍了星型模式的基础知识,以及SCD的定义和基础知识。我们探讨了SCD类型1、2和3,用于维护历史数据并捕捉当前状态的快照。在Snowflake的帮助下,我们使用零售示例实施了上述每种SCD技术。之后,我们概述了实施SCD可能带来的一些更具技术性的挑战,以及如何解决这些挑战。为了不断提升您的数据建模技能,请参加DataCamp提供的《数据库设计》、《数据工程简介》和《数据仓库简介》课程。祝您好运,编码愉快!抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”