自从2022年11月发布ChatGPT以来,LLM Chatbots已成为许多不同用例中突出的功能。
聊天机器人的概念并不新鲜。我们都见过到处都是无用的聊天机器人,它们需要进行深度配置,几乎是按照if-else规则编写的脚本。维护它们变成了一场噩梦,而且它们并没有帮助最终用户;事实上,它们恰恰相反,让最终用户感到沮丧。
但是现在,2024年,由于大型语言模型(LLMs)的出现,聊天机器人又回来了。在这篇博客中,你将学到:
- 检索增强生成技术是什么
- 大型语言模型是什么
- 如何使用OpenAI GPT和其他API
- 什么是向量数据库,为什么我们需要它?
- 使用Pinecone和OpenAI在Python中构建自己的聊天机器人
您还可以查看我们的代码教程使用OpenAI API和Pinecone构建聊天机器人以了解更多信息。
大型语言模型(LLM)
大型语言模型(LLMs)如GPT-4是先进的机器学习算法,利用深度学习技术,特别是transformer架构,来理解和生成自然语言。
它们是在包含来自互联网上各种文本的数万亿个单词的大规模数据集上进行训练的,例如书籍、文章、网站和编码存储库。这种广泛的训练使它们能够执行与语言处理相关的各种复杂任务。
LLMs的一个关键特点是它们能够在几乎任何主题上生成文本。这种能力涵盖了各种风格和格式,从创意写作到技术文档。
LLMs在诸如摘要等任务中表现出色,他们可以将冗长的文档提炼成简洁的摘要,并且在对话式人工智能方面也非常擅长,使他们能够与用户进行自然流畅的对话。他们还擅长跨语言翻译文本,甚至能捕捉俚语和地方方言等细微差别。
然而,LLM也面临着一些挑战。一个重要的问题是LLM可能会“产生幻觉”或生成看似正确但实际上是错误或无意义的信息,特别是在处理训练数据之外的查询或模糊的提示时。另一个关键问题是大型语言模型(LLM)输出中存在的偏见问题,这可能源于训练数据中存在的偏见或在模型开发过程中引入的偏见。
LLMs代表了人工智能的重大进步,在各个领域提供了巨大的创新和效率潜力,但也需要谨慎管理以减轻偏见和错误信息等风险。
什么是检索增强生成(RAG)?
虽然LLMs非常强大,但它们也有一定的局限性。如果查询超出了它们的训练数据范围,它们可能会提供过时、通用甚至错误的信息。
它们还可能创建事实上不正确或荒谬的信息,而模型将其呈现为真实或逻辑的。这种现象被称为幻觉。
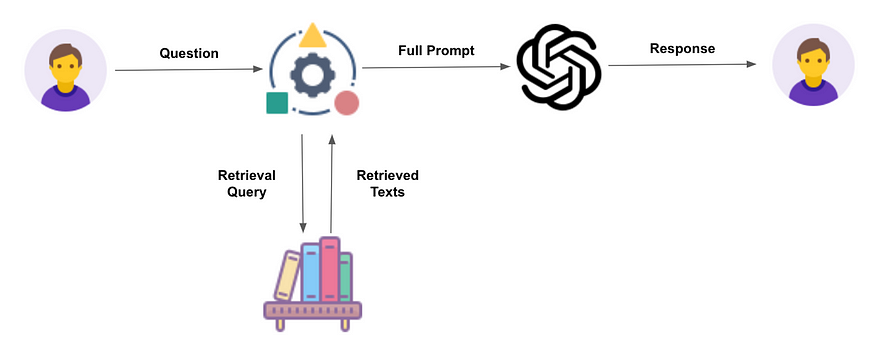
RAG旨在通过引导LLMs从预定的来源中检索相关信息来缓解这些问题。这种方法增强了用户的信任,因为模型的输出更准确,并且可以归因于可靠的来源。
它还为开发人员提供了对LLM生成的响应更多的控制,提高了系统的整体质量和适用性。
RAG过程
您可以在我们的独立教程中了解更多关于检索增强生成的信息。然而,在下面,我们概述了该过程的主要步骤。
- 外部数据的创建:RAG从准备外部数据源开始,这些数据源位于LLM的原始训练数据集之外。这些数据可能包括最新的研究、新闻或统计数据,它们被转换成LLM可以理解和利用的格式(嵌入向量)。
- 嵌入向量的存储:一旦原始文本数据使用模型转换成嵌入向量,它们就会被存储在一种称为向量数据库的数据库中。这种数据库被设计用于高效地存储和检索向量数据,并且非常适合RAG应用的目的。其中最流行的向量数据库之一是Pinecone。
- 检索相关信息:然后,模型通过查询向量数据库执行语义搜索。当用户输入查询时,它会被转换成向量表示,并与向量化的外部数据进行匹配。这个过程确保检索到最相关和最新的信息。
- 增强LLM提示:检索到的数据以及用户的原始查询被用来增强给LLM的提示。这样丰富的提示能够使模型生成更准确和上下文相关的回答。
- 外部数据的持续更新:为了保持信息的相关性和准确性,外部数据源会定期更新,确保LLM能够获取最新的信息。
向量数据库

向量数据库是专门设计用于处理高维向量的数据库类型,这些向量是数据属性或特征的数学表示。这些向量的维度可以从几十到几千维不等,具体取决于数据的复杂性和粒度。
这种类型的数据库特别擅长基于向量距离或相似性进行快速准确的相似性搜索和检索,从而实现更语义化或上下文数据查询的方法,而不是依赖于传统的精确匹配或预定义的标准。
从实际角度来看,向量数据库可以用于各种目的。例如,它们可以根据视觉内容和风格找到与给定图像相似的图像,根据主题和情感定位与特定文档相似的文档,或者根据特征和评级识别与某个产品相似的产品。
在向量数据库中的查询过程涉及使用表示所需信息或条件的查询向量,并应用相似度度量来确定向量在向量空间中的接近程度。这个过程会产生一个按照与查询向量具有高相似度得分的向量进行排名的列表,从而允许访问与每个向量相关联的原始数据。
向量数据库由各种算法驱动,例如k最近邻(k-NN)索引,并使用层次可导航小世界(HNSW)和倒排文件索引(IVF)算法构建。
向量数据库是检索增强生成(RAG)应用程序的重要组成部分。它们提供高效的相似性搜索、内容扩展、多样性和动态多模态数据检索。这种能力在生成式人工智能中至关重要,因为访问大规模、多样化的数据集对于减少人工智能模型中的偏见和幻觉是必不可少的。
Pinecone是一个受欢迎的向量数据库,以其高效性和易用性而脱颖而出,特别适用于处理大规模数据场景。它专为开发人员和数据科学家设计,旨在在各种应用程序中实现向量搜索功能。
Pinecone采用了先进的索引技术,如产品量化和局部敏感哈希,可以在高维向量空间中进行高效准确的相似性搜索。这使得它在RAG应用中特别有用。您可以在我们的独立教程中了解更多关于使用Pinecone掌握向量数据库的信息。
在本教程中,我们将使用Pinecone作为我们的向量数据库。
OpenAI API
OpenAI的API平台提供了对OpenAI训练的所有对公众开放的模型的访问权限。这包括GPT、DALL-E、Whisper和其他模型。
API通过HTTP请求进行访问,因此您可以将其与支持进行HTTP请求的任何编程语言集成。但是,对于Python,有一个名为openai的库,您可以使用pip install openai进行安装,这将使与这些API更加容易。
使用Python和openai库工作OpenAI API只需要几行代码。
Python示例:
import os
os.environ["OPENAI_API_KEY"] = " "
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are expert in Machine Learning."},
{"role": "user", "content": "Explain how does random forest works?."}
]
)
print(completion.choices[0].message)LangChain
LangChain是一个由语言模型驱动的应用程序开发框架。它提供了一定程度的抽象,使得快速开发原型以及从原型快速进入生产变得容易和快速。从他们的Github页面上的星号数量可以看出该框架的增长和受欢迎程度。
这是一个令人惊叹的框架。然而,目前有一个警告,就是它仍然不稳定。API不断变化,而且有可能在您阅读下一节代码时,它已经不再起作用了。这是预期的,因为该库仍处于“预发布”状态。撰写本博客时,Langchain的最新版本是0.1.4。
Python中的端到端示例:使用OpenAI GPT-4 API和Pinecone向量存储构建LLM聊天机器人应用的逐步指南
为了能够实现RAG后端,我们需要外部数据的嵌入。如果我们从原始数据开始,我们将需要使用OpenAI嵌入API或任何其他开源嵌入来进行嵌入。
嵌入原始数据非常简单。然而,如果您使用OpenAI API,您将按标记计费。
为了本教程的目的,我从官方的Pinecone LangChain指南中复制了本节中的大部分代码。Pinecone文档非常好,并且始终保持最新。
1. 注册OpenAI和Pinecone
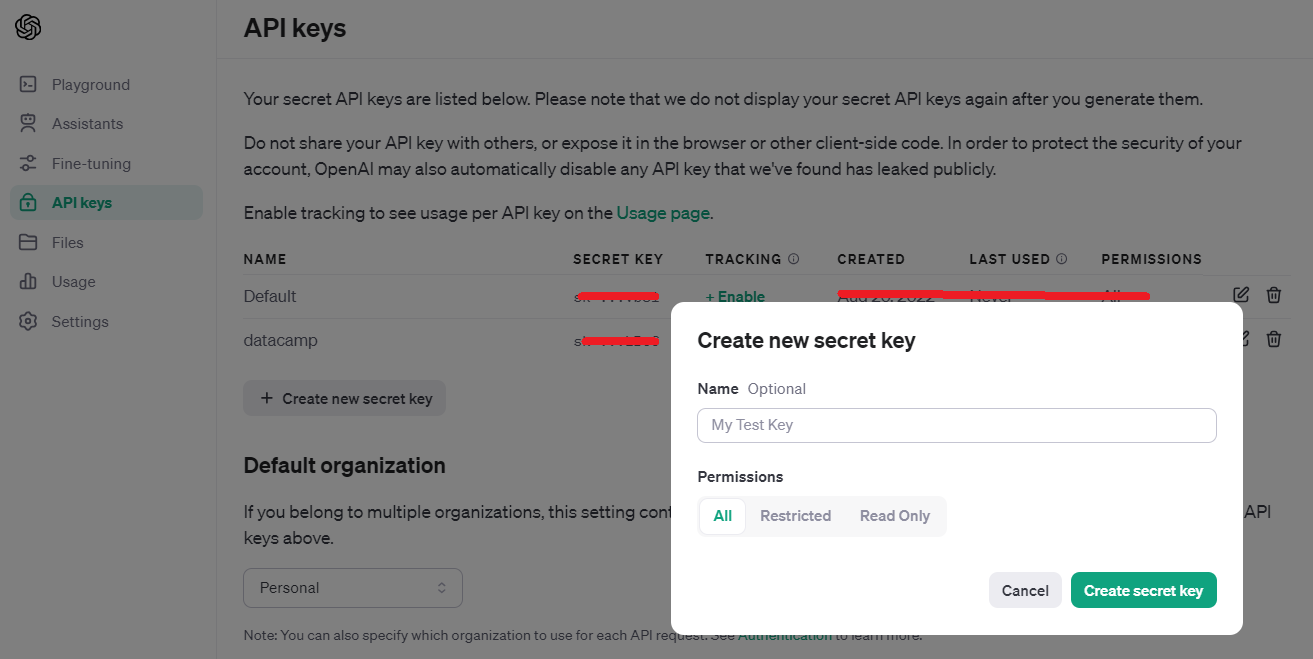
在注册OpenAI账户后,直接访问https://platform.openai.com/api-keys
当您生成密钥时,必须复制该密钥,因为您之后没有任何查看或复制密钥的选项。
这段文字的中文翻译如下:
对于Pinecone,登录到您的账户并点击API密钥。您可以点击右上角的`点击API密钥`按钮。
与OpenAI不同,使用Pinecone时,您不一定需要在生成API密钥时复制它,因为在操作列下面有一个复制图标,您可以随时使用。
这段文字的中文翻译如下:
一旦你从OpenAI和Pinecone获得了API密钥,将它们设置为Notebook中的变量。或者,你也可以使用Python中的`os`模块,并将这些密钥设置为环境变量。如果你选择这样做,你需要相应地在下面的代码中进行更改。
OPENAI_API_KEY = '...'
PINECONE_API_KEY = '...'2. 安装Python库
为了实现本教程,您需要使用pip安装以下库。
!pip install -qU \
langchain==0.1.1 \
langchain-community==0.0.13 \
openai==0.27.7 \
tiktoken==0.4.0 \
pinecone-client==3.0.0 \
pinecone-datasets==0.7.03. 示例数据集
pinecone-datasets库提供了一些已经使用OpenAI的embedding-ada-002模型嵌入的示例数据集。我们将使用其中一个示例数据集,名为wikipedia-simple-text-embedding-ada-002-100K。
如字面意思所示,这里有100,000个文档。然而,在本教程中,我们只会对前30,000条记录进行抽样。尽管由于嵌入向量已经提供了所有100,000个文档的信息,所以没有任何成本影响,但抽样只是为了加快处理速度。
import pinecone_datasets
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002-100K')
# 删除元数据列并将blob重命名为metadata
dataset.documents.drop(['metadata'], axis=1, inplace=True)
dataset.documents.rename(columns={'blob': 'metadata'}, inplace=True)
# 随机抽样30k个文档
dataset.documents.drop(dataset.documents.index[30_000:], inplace=True)4. 设置Pinecone索引
from pinecone import Pinecone, ServerlessSpec
# 配置客户端
pc = Pinecone(api_key=PINECONE_API_KEY)
# 配置无服务器规范
spec = ServerlessSpec(cloud='aws', region='us-west-2')
# 检查并删除已存在的索引
index_name = 'langchain-retrieval-augmentation-fast'
if index_name in pc.list_indexes().names():
pc.delete_index(index_name)
# 创建一个新的索引
pc.create_index(
index_name,
dimension=1536, # 文本嵌入维度为1536
metric='dotproduct',
spec=spec
)
连接到索引并检查索引的统计信息:
index = pc.Index(index_name)
index.describe_index_stats()
这将是输出结果:
{'dimension': 1536,
'index_fullness': 0.0,
'namespaces': {},
'total_vector_count': 0}
1536是来自ada-002模型的嵌入的形状。你可以看到向量计数为零,因为我们还没有摄入任何数据(向量)。
5. 插入数据
将数据插入到这个索引langchain-retrieval-augmentation-fast中非常简单:
for batch in dataset.iter_documents(batch_size=100):
index.upsert(batch)
这个命令将需要几分钟才能完成。
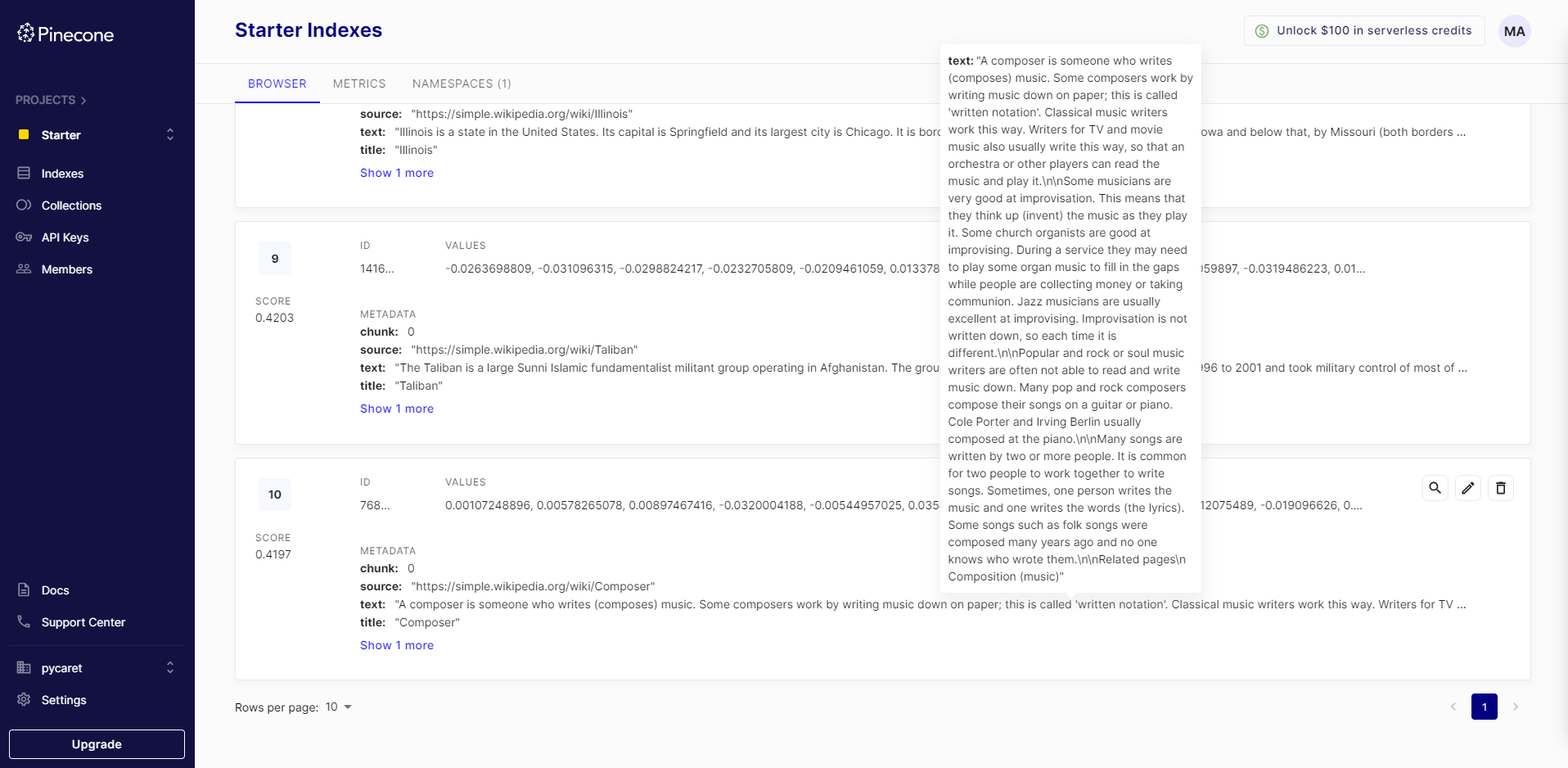
在插入数据后,您还可以在Pinecone UI上看到它:
这段文字的中文翻译如下:
6. LangChain
现在我们已经创建了一个索引并使用Pinecone API将数据插入到索引中,我们将转向使用LangChain。下一步是使用LangChain初始化一个LangChain向量存储,并利用我们已经创建的相同索引。
from langchain.embeddings.openai import OpenAIEmbeddings
model_name = 'text-embedding-ada-002'
embed = OpenAIEmbeddings(model=model_name, openai_api_key=OPENAI_API_KEY)
初始化向量存储:
from langchain.vectorstores import Pinecone
vectorstore = Pinecone(index, embed.embed_query, "text")
7. 查询向量存储
您现在可以使用vectorstore对象来查询数据并查看前N个结果:
query = "什么是精神分裂症?"
vectorstore.similarity_search(query, k=3)输出是一个文档对象,你可以轻松解析字符串,但基本上,它显示了根据我们在第4步选择的度量标准(在本例中为dotmatrix)匹配的前3个文档。

这段文字的中文翻译如下:
8. 最后一步 – 添加一个LLM🚀
这是我们应用程序的最后一步。我们现在想要将LLM包装在其中。为了做到这一点,您将从Langchain导入ChatOpenAI和RetrievalQA类。
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# completion llm
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-4',
temperature=0.0
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
qa.run(query)
qa.run(query)的输出是语言模型的响应。
精神分裂症是一种精神疾病,患者可能会看到、听到或相信一些并不存在的事物。它通常首次出现在青少年时期,是一种慢性病症… 这个答案来自于`dataset`中的一个文档。如果你还想获取源代码(在RAG应用中通常需要),你需要对上面的代码进行一个小的修改。
from langchain.chains import RetrievalQAWithSourcesChain
qa_with_sources = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
qa_with_sources(query)
输出:
{'question': '什么是精神分裂症?',
'answer': '精神分裂症是一种精神疾病,患者可能会看到、听到或相信一些并不存在的事物。这是一种相对常见的疾病...',
'sources': 'https://simple.wikipedia.org/wiki/Schizophrenia'}请注意,这次的输出是一个字典,其中包含了`source`。
结论
在这篇博客中,我们探讨了LLM最流行的应用——检索增强生成(RAG)技术,深入介绍了它如何基于像GPT-4这样的大型语言模型提高聊天机器人回复的可靠性和相关性。
从简单的基于规则的系统到复杂的基于人工智能的对话代理,聊天机器人的演变标志着技术进步的重大飞跃。LLMs为聊天机器人带来了新的多功能和智能水平,能够进行更加自然、具有上下文意识的对话。
我们还探讨了向量数据库的作用,重点关注Pinecone在存储和检索高维数据向量方面的应用。这些数据库在实施RAG中起着关键作用。
通过代码示例,利用OpenAI和Pinecone API以及Python中的LangChain框架,展示了这些概念的实际实现。这些工具简化了开发过程,使开发人员能够快速高效地创建适用于各种应用的基于人工智能的聊天机器人。
要了解有关使用OpenAI API的工作的更多信息,请查看我们的课程,该课程可以帮助您利用OpenAI的各种模型的强大功能。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”