谷歌最近发布了其新的生成式人工智能模型Gemini。这是谷歌研究团队以及其他团队的合作成果。详情请参考生成式人工智能概念。
这个模型被谷歌称为迄今为止最强大和通用的人工智能,它被设计成多模态的。这意味着Gemini可以理解各种数据类型,如文本、音频、图像、视频和代码。
在本文的剩余部分,我们将涵盖以下内容:
- 什么是Gemini?
- Gemini有哪些版本?
- 如何访问Gemini?
- 探索Gemini基准测试
- Gemini与GPT-4的比较
- Gemini的用例
什么是Google Gemini?
2023年12月6日,Google DeepMind宣布推出Gemini 1.0。Google将其描述为他们最先进的大型语言模型(LLMs),因此取代了在同一年5月发布的Pathways Langauge Model(PaLM 2)。
Gemini定义了一系列多模态LLM(语言与语言模型)的家族,能够理解文本、图片、视频和音频。据说它还能够执行复杂的数学和物理任务,并能够生成多种编程语言的高质量代码。
有趣的事实:谷歌的联合创始人Sergey Brin被认为是Gemini模型的贡献者之一。
直到最近,开发多模态模型的标准流程通常是训练各种模态的单独组件,然后将它们组合在一起以模拟某些功能。这样的模型有时在执行某些任务(如描述图像)方面表现出色,但在更复杂和复杂的推理方面存在困难。
Gemini被设计成本地多模态的;因此,它从一开始就进行了多模态的预训练。为了进一步提高其效果,Google使用额外的多模态数据对其进行了微调。
根据Google和Alphabet的CEO Sundar Pichai以及Google DeepMind的CEO兼联合创始人Demis Hassabis的说法,因此,Gemini在从根本上理解和推理各种输入方面比现有的多模态模型更具能力。他们还表示,Gemini的能力在几乎所有领域都是“最先进的”。
Google Gemini关键特点
Gemini模型的关键特点包括:
1. 理解文本、图像、音频和更多
多模态人工智能是一种新的人工智能范式,通过将不同的数据类型与多个算法相结合,实现更高的性能。Gemini利用这种范式,意味着它与各种数据类型很好地集成在一起。您可以输入图像、音频、文本和其他数据类型,从而实现更自然的人工智能交互。
2. 可靠性,可扩展性和效率
Gemini利用了Google的TPUv5芯片,据报道比GPT-4强大五倍。更快的处理速度使得Gemini能够相对轻松地处理复杂任务,并同时处理多个请求。
3. 复杂推理
Gemini是在大量的文本和代码数据集上进行训练的。这确保了模型可以获取最新的信息,并对您的查询提供准确可靠的回答。根据Google的说法,该模型在各种智力测试(例如MMLU基准测试)中胜过了OpenAI的GPT-4和“专家级”人类。
4. 高级编码
Gemini 1.0可以理解、解释和生成最广泛使用的编程语言(如Python、Java、C++和Go)中的高质量代码 – 这使其成为全球领先的编码基础模型之一。
该模型在多个编码基准测试中也表现出色,包括HumanEval,这是一个评估编码任务性能的业界标准;它在谷歌内部的保留数据集上也表现良好,该数据集利用的是作者生成的代码而不是来自网络的信息。
5. 责任和安全
为了考虑到Gemini的多模态能力,Google在其AI原则和政策中增加了新的保护措施。Google表示:“Gemini是迄今为止拥有最全面安全评估的Google AI模型,包括偏见和有害性评估。”他们还表示他们“进行了关于潜在风险领域的新颖研究,如网络攻击、说服力和自主性,并应用了Google Research最佳的对抗性测试技术,以帮助在Gemini部署之前提前识别关键的安全问题。”
‘
Gemini有哪些版本?
谷歌表示,Gemini是继LaMDA和PaLM 2之后的继任者,是他们“迄今为止最灵活的模型 – 能够高效运行在从数据中心到移动设备的各种平台上。”他们还相信Gemini的先进能力将改善开发人员和商业客户在人工智能方面的构建和扩展。
Gemini的第一个版本,毫不意外地被命名为Gemini 1.0,发布了三种不同尺寸:
- Gemini Nano — Gemini Nano是用于在设备上执行高效AI处理任务而无需连接到外部服务器的最高效模型。换句话说,它专为在智能手机上运行而设计,特别是Google Pixel 8。
- Gemini Pro — Gemini Pro是用于扩展各种任务的最佳模型。它专为驱动Google最新的AI聊天机器人Bard而设计,因此它能够理解复杂的查询并快速响应。
- Gemini Ultra — Gemini Ultra是用于复杂任务的最大和最强大的模型,在大型语言模型(LLM)研究和开发的32个常用基准中,超过了当前最先进的结果中的30个。
如何访问Gemini?
自2023年12月13日起,开发人员和企业客户可以通过Google AI Studio或Google Cloud Vertex AI中的Gemini API访问Gemini Pro。
注意,Google AI Studio是一个免费提供的基于浏览器的IDE,开发人员可以使用它来原型化生成模型,并使用API密钥轻松启动应用程序。另一方面,Google Cloud Vertex是一个完全托管的AI平台,提供了构建和使用生成AI所需的所有工具。根据Google的说法,“Vertex AI允许自定义Gemini,并具有完全的数据控制,并从企业安全性、安全性、隐私和数据治理以及合规性的其他Google Cloud功能中受益。”
通过AICore,一个在Android 14中的新系统功能,Android开发者可以从Pixel 8 Pro设备开始,使用Gemini Nano构建最高效的本地任务模型。
探索Gemini基准测试
在发布之前,Gemini模型经过了广泛的测试,以评估其在各种任务中的性能。谷歌表示,其Gemini Ultra模型在32个常用的大型语言模型(LLM)研究和开发学术基准测试中,有30个超过了现有的最先进结果。请注意,这些任务涵盖了自然图像、音频和视频理解以及数学推理等多个领域。
在一篇谷歌的Gemini介绍博文中,谷歌声称Gemini Ultra是第一个在大规模多任务语言理解(MMLU)上超越人类专家的模型,得分为90.0%。请注意,MMLU包括57个不同的主题,包括数学、物理、历史、法律、医学和伦理学,以评估一个人解决问题的能力和对世界的一般理解。
新的MMLU基准方法使Gemini能够在回答具有挑战性的问题之前,通过使用其推理能力更加深入地思考,从而取得显著的改进,而不仅仅是利用其第一印象。
以下是Gemini在文本任务上的表现:
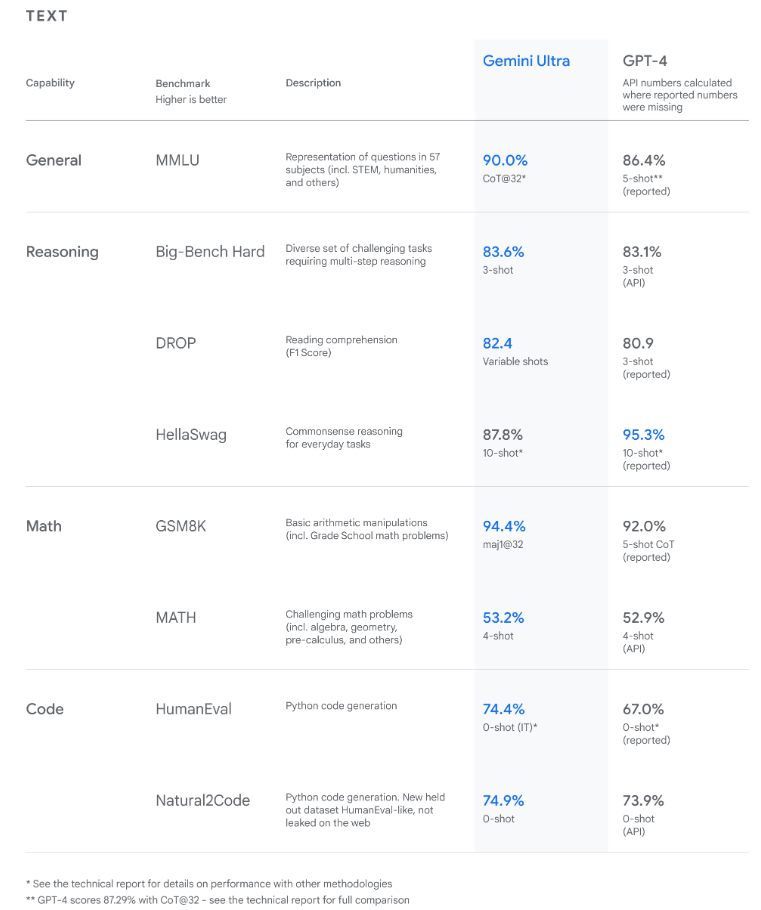
研究结果显示,Gemini在包括文本和编码在内的各种基准测试中超越了最先进的性能。[来源]
Gemini Ultra模型在新的Massive Multidiscipline Multimodal Understanding (MMMU)基准测试中也取得了最先进的成绩,达到了59.4%。该评估包括跨多个领域的多模态任务,需要有意识的推理。
谷歌表示:“通过我们进行的图像基准测试,Gemini Ultra在没有光学字符识别(OCR)系统的帮助下,就能超越以往的最先进模型,这些模型需要从图像中提取文本进行进一步处理。”
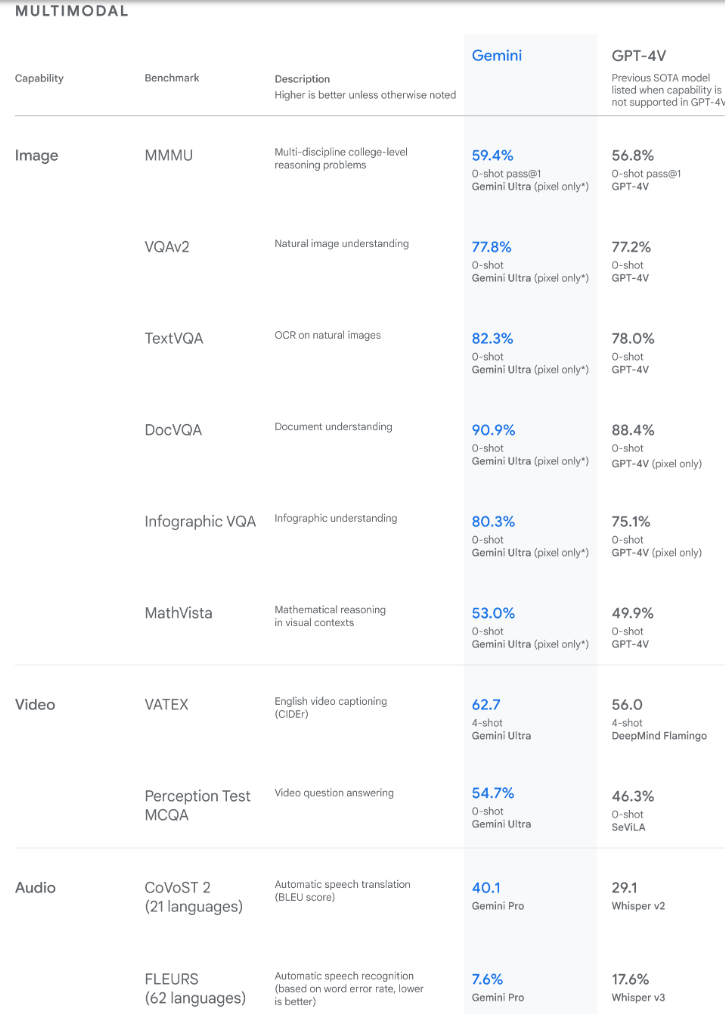
研究结果显示,Gemini在广泛的多模态基准测试中也超越了最先进的性能。[来源]
Gemini所设定的基准测试展示了该模型固有的多模态性,并显示出其更复杂推理能力的早期证据。
Gemini vs. GPT-4
接下来通常会出现的一个明显问题是,“Gemini与GPT-4相比如何?”
这两个模型具有相似的功能集,可以与文本、图像、视频、音频和代码数据进行交互和解释,使用户能够将它们应用于各种任务。
这两个工具的用户都可以进行事实核查,但它们提供这种功能的方式不同。OpenAI的GPT-4在提出主张时提供源链接,而Gemini则允许用户通过点击按钮进行谷歌搜索以确认回答。
还可以通过添加额外的扩展来增强这两个模型,尽管在撰写本文时,谷歌的Gemini模型的功能更加有限。
例如,可以利用Google工具,如航班、地图、YouTube和他们的一系列Workspace应用程序与Gemini一起使用。相比之下,OpenAI的GPT-4有更多的插件和扩展可供选择,其中大部分是由第三方创建的。使用GPT-4还可以实现即时图像创建;Gemini被设计成具备这种功能,但在撰写本文时尚不具备该功能。
另一方面,Gemini的响应时间比GPT-4更快,因为平台上的用户数量庞大,GPT-4有时会变慢或完全中断。
Gemini的应用场景
谷歌的Gemini模型可以在文本、音频、图像和视频理解等多种模态下执行各种任务。
由于Gemini的多模态特性,结合不同的模态来理解和生成输出也是可能的。
Gemini的使用案例示例包括:
文本摘要
Gemini模型可以从各种数据类型中摘要内容。根据一篇名为《GEMINI: Controlling The Sentence-Level Summary Style in Abstractive Text Summarization》的研究论文,Gemini模型“整合了重写和生成器,以分别模拟句子重写和摘要技术。”
换句话说,Gemini会自适应地选择是重写特定文档的句子还是完全从头生成摘要句子。实验结果显示,Gemini所采用的方法在三个基准数据集上表现优于纯抽象和重写基准线,取得了在WikiHow上的最佳结果。
文本生成
Gemini可以根据用户提示生成基于文本的输入 – 这段文本也可以由问答式聊天机器人界面驱动。因此,Gemini可以部署来处理客户咨询并以自然而有吸引力的方式提供帮助,从而使人工代理人能够更多地应用于复杂任务,并提高客户满意度。
它还可以用于创意写作,例如共同创作一部小说,以不同风格写诗,或为电影和戏剧生成剧本。这可以显著提高创意作家的生产力,并减少写作困境带来的紧张感。
文本翻译和音频处理
凭借其广泛的多语言能力,Gemini模型可以理解和翻译超过100种不同的语言。根据谷歌的说法,Gemini在一系列多模态基准测试中超越了Chat GPT-4V的最先进性能,例如自动语音识别(ASR)和自动语音翻译。
图像和视频处理
Gemini可以理解和解释图像,适用于图像标题和视觉问答等用例。该模型还可以解析复杂的视觉内容,包括图表、图形和图表,而无需外部OCR工具。
代码分析和生成
开发人员可以使用Gemini来解决复杂的编码任务并调试他们的代码。该模型能够理解、解释和生成最常用的编程语言,如Python、Java、C++和Go。
结论
谷歌的新一代多模态大型语言模型(LLMs),Gemini,是LaMDA和PaLM 2的继任者。他们将其描述为他们最先进的LLMs集合,能够理解文本、图片、视频、音频以及数学和物理等复杂任务。Gemini还能够生成许多最流行的编程语言中的高质量代码。
这个模型在各种任务中取得了最先进的能力,许多谷歌员工认为它代表了人工智能如何帮助改善我们日常生活的重大进步。
继续学习,可以参考以下资源: