当数据从业者谈论数据存储时,大部分时间他们指的是数据存储的位置,无论是本地文件、SQL或NoSQL数据库,还是云端。然而,与数据存储相关的另一个重要方面是数据的存储方式。
数据存储的“如何”通常发生在更低的层次上,即编程语言的核心。它与数据从业者使用的工具的设计有关,而不是如何使用这些工具。然而,了解数据的存储方式对于数据专业人员来说至关重要,以便理解使他们的工作成为可能的基本机制。此外,这种知识可以帮助他们做出更好的决策,以提高计算性能。
在这篇文章中,我们将讨论哈希映射。哈希映射是一种利用哈希技术以关联方式存储数据的数据结构。哈希映射是优化的数据结构,可以实现更快的数据操作,包括插入、删除和搜索。许多现代编程语言,如Python、Java和C++,都支持哈希映射。在Python中,哈希映射通过字典实现,这是一种广泛使用的数据结构,你可能已经了解。在接下来的章节中,我们将介绍字典的基础知识,它们的工作原理,以及如何使用不同的Python包来实现它们。
什么是哈希映射?
要定义一个哈希映射,我们首先需要了解哈希是什么。哈希是将任何给定的键或字符串转换为另一个值的过程。结果通常是一个较短的固定长度值,使得与原始键相比,计算上更容易处理。
哈希映射,也被称为哈希表,是哈希算法最常见的一种实现方式之一。哈希映射将键值对(例如员工ID和员工姓名)存储在一个列表中,并通过索引进行访问。
哈希映射的理念是将条目(键/值对)分布在一个桶数组中。给定一个键,哈希函数将计算出一个独特的索引,指示条目的位置。使用索引而不是原始键使得哈希映射特别适用于多个数据操作,包括数据插入、删除和搜索。
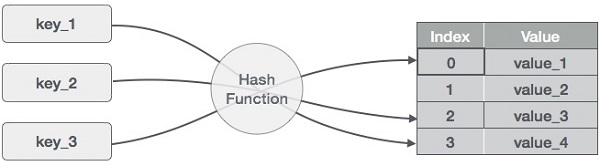
哈希映射的工作原理。
为了计算哈希值,或者简称为哈希,哈希函数根据数学哈希算法生成新的值。由于键值对在理论上是无限的,哈希函数将根据给定的表大小映射键。
有多种可用的哈希函数,每个函数都有其优缺点。哈希函数的主要目标是对于相同的输入始终返回相同的值。
最常见的有以下几种:
- 除法法则。这是计算哈希值最简单和最快的方法。通过将键除以表的大小,然后使用余数作为哈希值。
- 中间平方法。它会找到给定键的平方,然后取中间的数字作为元素的索引。
- 乘法法则。它通过将键乘以一个大实数的小数部分来设置哈希索引。
- 折叠法则。首先将键分成相等大小的片段,然后将结果相加,并将结果除以表的大小。哈希值是余数。
Python中的哈希映射
Python通过内置的字典数据类型实现哈希映射。像哈希映射一样,字典以{键:值}对的形式存储数据。一旦创建了字典(参见下一节),Python将在幕后应用方便的哈希函数来计算每个键的哈希值。
Python字典具有以下特点:
- 字典是可变的。这意味着我们可以在创建字典之后更改、添加或删除项目。
- 元素是有序的。在Python 3.6及更早版本中,字典是无序的,这意味着项目没有定义的顺序。然而,在Python 3.7发布后,字典变得保持顺序。现在,当你创建一个Python字典时,键将按照源代码中列出的顺序排列。要了解更多关于这个变化背后的原因,请阅读Python核心开发者之一Raymond Hettinger的这篇说明。
- 键是不可变的。这意味着键始终是不可更改的数据类型。换句话说,字典只允许可哈希的数据类型,如字符串、数字和元组。相反,键永远不能是可变数据类型,比如列表。
- 键是唯一的。键在字典中是唯一的,不能在字典内部重复。如果使用多次,后续的条目将覆盖先前的值。
所以,如果你曾经想知道哈希映射和字典之间的区别,答案很简单。字典只是Python对哈希映射的本地实现。而哈希映射是一种可以使用多种哈希技术创建的数据结构,字典是一种特定的、基于Python的哈希映射,其设计和行为在Python的dict类中指定。
如何使用Python字典
让我们看一些最常见的字典操作。要了解更多关于如何使用字典的信息,请查看我们的Python字典教程。
创建字典
在Python中创建字典非常简单。您只需要使用花括号,并通过逗号分隔插入键值对。或者,您可以使用内置的dict()函数。让我们创建一个将首都映射到国家的字典:
# 创建字典
dictionary_capitals = {'Madrid': '西班牙', 'Lisboa': '葡萄牙', 'London': '英国'}打印字典的内容:
print(dictionary_capitals){'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}重要的是要记住字典中的键必须是唯一的;不允许重复。然而,如果出现重复的键,Python不会报错,而是将最后一个键的实例视为有效,并简单地忽略第一个键值对。自己看一下:
dictionary_capitals = {'Madrid': '中国', 'Lisboa': '葡萄牙',
'London': '英国','Madrid':'西班牙'}print(dictionary_capitals){'Madrid': '西班牙', 'Lisboa': '葡萄牙', 'London': '英国'}在字典中搜索
要在字典中搜索信息,我们需要在方括号中指定键,Python将返回相应的值,如下所示:
# 搜索数据
dictionary_capitals['Madrid']'Spain'如果你尝试访问字典中不存在的键,Python会抛出一个错误。为了防止这种情况,你可以使用.get()方法来访问键。如果键不存在,它将返回一个None值:
‘
print(dictionary_capitals.get('Prague'))None在字典中添加和删除值
让我们添加一个新的首都-国家对:
# 创建一个新的键值对
dictionary_capitals['Berlin'] = 'Italy'相同的语法可以用来更新与键关联的值。让我们修复与柏林关联的值:
# 更新键的值
dictionary_capitals['Berlin'] = 'Germany'现在让我们删除字典中的一个键值对
# 删除键值对
del dictionary_capitals['Lisboa']print(dictionary_capitals){'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}或者,如果你想删除字典中的所有键值对,你可以使用.clear()方法:
dictionary_capitals.clear()遍历字典
如果你想要获取所有的键值对,使用.items()方法,Python会返回一个可迭代的元组列表:
dictionary_capitals.items()dict_items([('Madrid', 'Spain'), ('London', 'United Kingdom'), ('Berlin', 'Germany')])# 遍历键值对
for key, value in dictionary_capitals.items():
print('{}的首都是{}'.format(value, key))Spain的首都是Madrid
United Kingdom的首都是London
Germany的首都是Berlin同样,如果你想要获取一个包含键和值的可迭代列表,你可以分别使用.keys()和.values()方法:
dictionary_capitals.keys()dict_keys(['Madrid', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())MADRID
LONDON
BERLINdictionary_capitals.values()dict_values(['Spain', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())SPAIN
UNITED KINGDOM
GERMANY哈希映射的实际应用
哈希映射是强大的数据结构,在数字世界的几乎每个地方都被使用。下面是哈希映射的一些实际应用:
- 数据库索引。哈希映射经常用于索引和搜索大量数据。常见的网络浏览器使用哈希映射来存储索引的网页。
- 缓存管理。现代操作系统使用哈希映射来组织缓存内存,以便快速访问经常使用的信息。
- 密码学。哈希映射在密码学领域起着关键作用。密码算法利用哈希映射实现数据完整性、数据验证和网络安全交易。
- 区块链。哈希映射是区块链的核心。每当网络中发生一笔交易,该交易的数据被作为哈希函数的输入,然后产生一个唯一的输出。区块链中的每个区块都携带着前一个区块的哈希,形成一个区块链。
哈希映射的最佳实践和常见错误
哈希映射是非常多用途和高效的数据结构。然而,它们也存在问题和限制。为了解决与哈希映射相关的常见挑战,重要的是记住一些考虑因素和良好实践。
键必须是不可变的
这是有道理的:如果键的内容发生变化,哈希函数将返回不同的哈希值,因此Python将无法找到与该键关联的值。
解决哈希映射冲突
只有当每个项都映射到哈希表中的唯一位置时,哈希才能正常工作。但有时,哈希函数可能会对不同的输入返回相同的输出。例如,如果使用除法哈希函数,不同的整数可能具有相同的哈希函数(在应用模除时可能返回相同的余数),从而创建了一个称为冲突的问题。必须解决冲突,并存在多种技术来解决。幸运的是,在字典的情况下,Python在内部处理潜在的冲突。
理解负载因子
负载因子被定义为表中元素数量与桶总数的比率。它是一种估计数据分布情况的指标。一般来说,数据分布越均匀,发生碰撞的可能性就越小。同样,在字典的情况下,Python会自动调整表的大小以适应新的键值对插入或删除。
注意性能
一个好的哈希函数应该尽量减少碰撞的次数,计算简单,并且能够均匀地分布在哈希表中。这可以通过增加表的大小或者增加哈希函数的复杂度来实现。虽然对于少量的项目来说这是可行的,但是当可能的项目数量很大时,这样做会导致内存消耗大,哈希映射效率低下。
字典是你需要的吗?
字典很好,但其他数据结构可能更适合你的特定数据和需求。最终,字典不支持常见的操作,如索引、切片和连接,使它们在某些情况下更不灵活、更难处理。
Python哈希映射的替代实现
如前所述,Python通过内置的字典实现了哈希映射。然而,值得注意的是,还有其他原生的Python工具以及第三方库可以利用哈希映射的强大功能。
让我们来看一些最受欢迎的例子。
Defaultdict
每当你尝试访问字典中不存在的键时,Python会返回一个KeyError。防止这种情况的一种方法是使用.get()方法来搜索信息。然而,一种更优化的方法是使用Defaultdict,它在collections模块中可用。Defaultdict和普通字典几乎是相同的。唯一的区别是Defaultdict不会因为不存在的键而引发错误,因为它为不存在的键提供了默认值。
from collections import defaultdict
# 定义字典
capitals = defaultdict(lambda: "该键不存在")
capitals['Madrid'] = '西班牙'
capitals['Lisboa'] = '葡萄牙'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara']) 西班牙
葡萄牙
该键不存在 Counter
Counter是Python字典的子类,专门用于计数可哈希对象。它是一个字典,其中元素被存储为键,它们的计数被存储为值。
有几种初始化计数器的方法:
- 通过一系列的项目。
- 通过字典中的键和计数。
- 使用名称:值映射。
from collections import Counter
# 从可迭代对象创建一个新的计数器
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# 从映射创建一个新的计数器
c2 = Counter({'red': 4, 'blue': 2})
# 从关键字参数创建一个新的计数器
c3 = Counter(cats=4, dogs=8)
# 打印结果
print(c1)
print(c2)
print(c3)Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
Counter({'red': 4, 'blue': 2})
Counter({'dogs': 8, 'cats': 4})计数器类带有一系列方便的方法,用于进行常见的计算。
print('计数器的键:', c3.keys())
print('计数器的值:', c3.values())
print('包含所有元素的列表:', list(c3.elements()))
print('元素的数量:', c3.total()) # 元素的数量
print('出现次数最多的2个元素:', c3.most_common(2)) # 出现次数最多的2个元素 dict_keys(['cats', 'dogs'])
dict_values([4, 8])
['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
12
[('dogs', 8), ('cats', 4)]Scikit-learn哈希方法
Scikit-learn,也被称为sklearn,是一个开源的、强大的Python机器学习库。它的目的是简化在Python中实现机器学习和统计模型的过程。
Sklearn提供了各种哈希方法,对于特征工程过程非常有用。
其中最常见的方法之一是CountVectorizer方法。它用于根据每个单词在整个文本中出现的频率将给定的文本转换为向量。CountVectorizer在文本分析环境中特别有帮助。
from sklearn.feature_extraction.text import CountVectorizer
documents = ["欢迎来到这个新的DataCamp Python课程",
"欢迎来到这个新的DataCamp R技能培训",
"欢迎来到这个新的DataCamp数据分析师职业培训"]
# 创建一个向量化器对象
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# 打印唯一值
print('唯一单词: ', vectorizer.get_feature_names_out())
# 打印稀疏矩阵和单词频率
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())唯一单词: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill' 'this' 'to' 'track' 'welcome']
在sklearn中还有其他的哈希方法,包括FeatureHasher和DictVectorizer。我们的Python机器学习学习案例:学校预算是一个很好的例子,你可以在其中学习它们在实践中的应用。
结论
恭喜您完成了关于哈希映射的教程。我们希望您现在对哈希映射和Python字典有了更好的理解。如果您想进一步了解字典以及如何在实际场景中使用它们,我们强烈推荐您阅读我们专门的Python字典教程,以及我们的Python字典推导教程。
最后,如果你刚开始学习Python并且想要学到更多知识,可以参加DataCamp的Python数据科学入门课程,并查看我们的Python初学者教程。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”
