谷歌巴德面临着来自ChatGPT的日益激烈的竞争,但随着最新的Gemini AI模型的发布,他们希望重新在市场上站稳脚跟。为了改善用户体验,谷歌最近使用Gemini Pro模型对巴德AI助手进行了改进,使用户可以输入文本和图片以获得准确和自然的回复。在本教程中,我们将探索Google Gemini API,该API允许您创建高级基于人工智能的应用程序。通过利用其强大的功能,您可以轻松地将文本和图像输入结合起来,生成精确且与上下文相关的输出。Gemini Python API简化了与现有项目的集成,实现了先进人工智能功能的无缝实施。
什么是Gemini AI?
Gemini AI是由Google内部的各个团队(如Google Research和Google DeepMind)共同努力创建的一种先进的人工智能(AI)模型。Gemini AI被设计为多模态,可以理解和处理多种形式的数据,包括文本、代码、音频、图像和视频。
谷歌DeepMind追求人工智能的目标一直以来都是希望利用其能力造福人类。基于此,Gemini AI在创建新一代受人类感知和与世界互动启发的AI模型方面取得了重大进展。作为迄今为止由Google开发的最复杂、最大的AI模型,Gemini AI被设计为高度灵活,能够处理各种类型的信息。它的多功能性使其能够在各种系统上高效运行,从强大的数据中心服务器到移动设备。
这里有三个针对特定用例训练的Gemini模型版本:
- Gemini Ultra: 最先进的版本,能够处理复杂的任务。
- Gemini Pro: 一个平衡的选择,提供良好的性能和可扩展性。
- Gemini Nano: 针对移动设备进行优化,提供最大的效率。
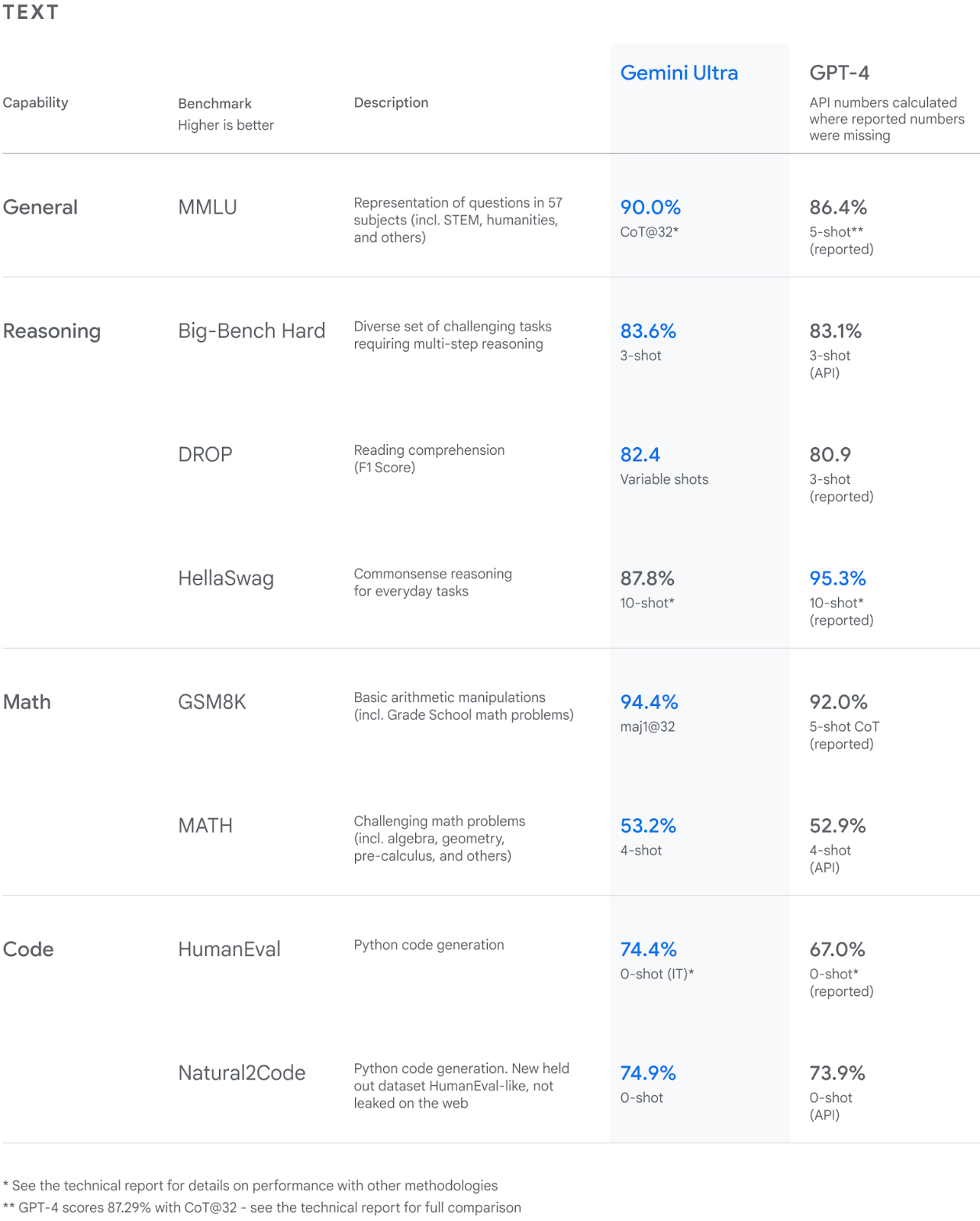
图片 来源
在这些变体中,Gemini Ultra表现出了出色的性能,超过了GPT-4在多个标准上。它是第一个在大规模多任务语言理解基准测试中超过人类专家的模型,该测试评估了57个学科领域的世界知识和问题解决能力。这一成就证明了Gemini Ultra的优越理解和问题解决能力。
如果你对人工智能还不熟悉,可以探索AI Fundamentals技能路径。它涵盖了ChatGPT、大型语言模型和生成式人工智能等热门AI主题。
环境设置
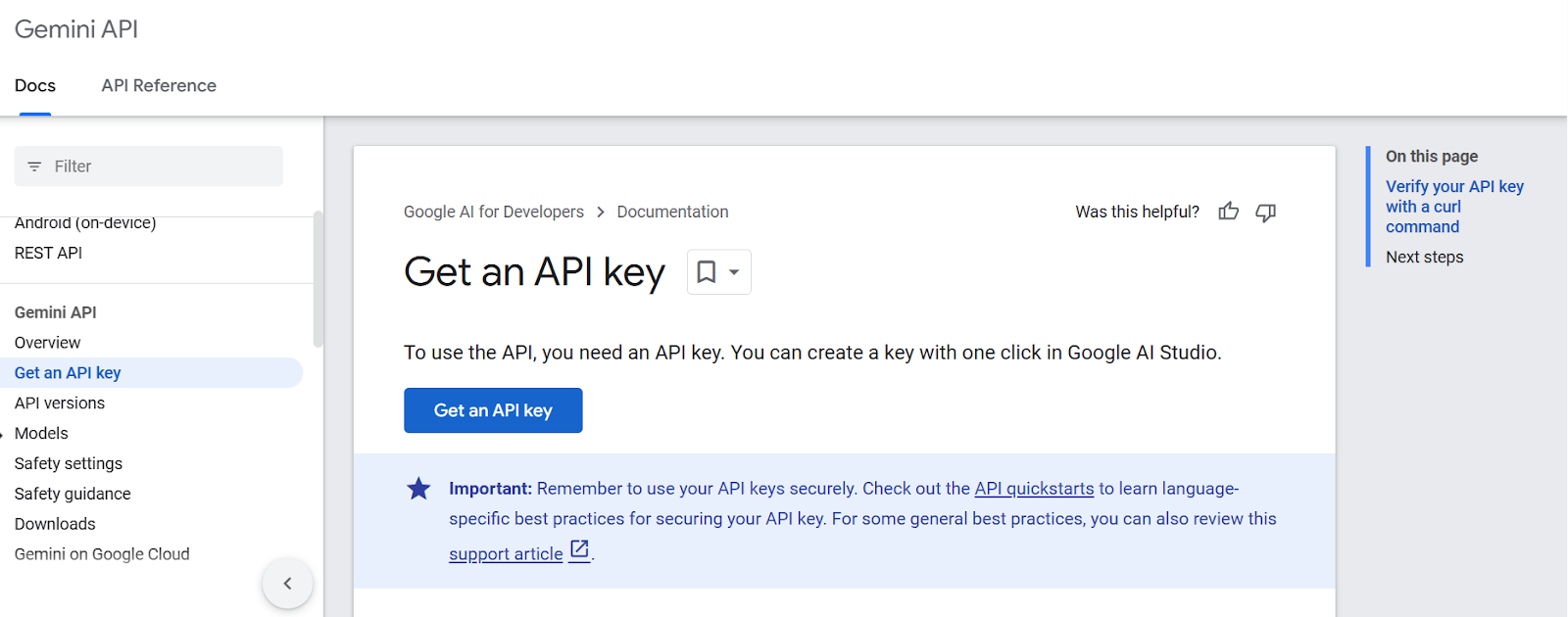
在我们开始使用API之前,我们需要从Google AI for Developers获取API密钥。
1. 点击“获取API密钥”按钮。
这段文字的中文翻译如下:
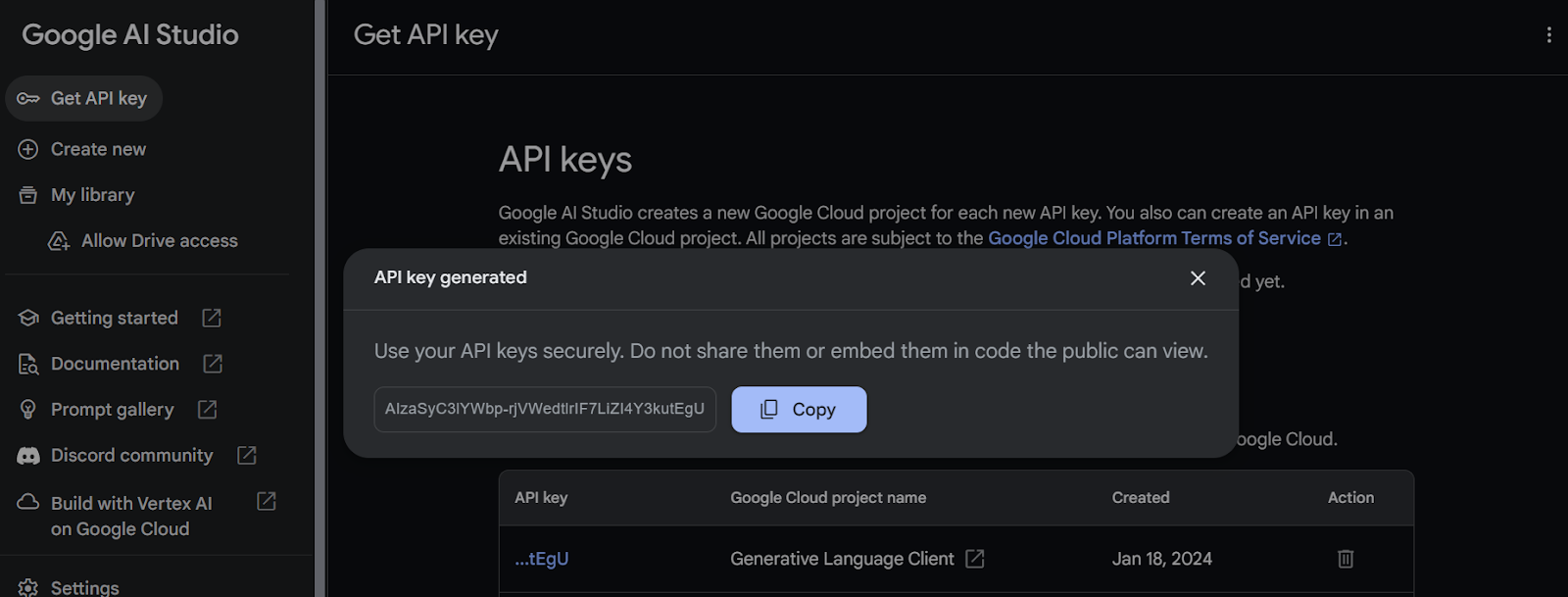
2. 在此之后,创建项目并生成 API 密钥。
这段文字的中文翻译如下:
3. 复制API密钥并在您的系统中添加一个名为”Gemini_API_KEY”的环境变量。为了在Kaggle上创建一个安全的环境变量,转到”Add-ons”并选择”Secrets”。然后,点击”Add a new secret”按钮以添加一个标签及其对应的值,并保存。
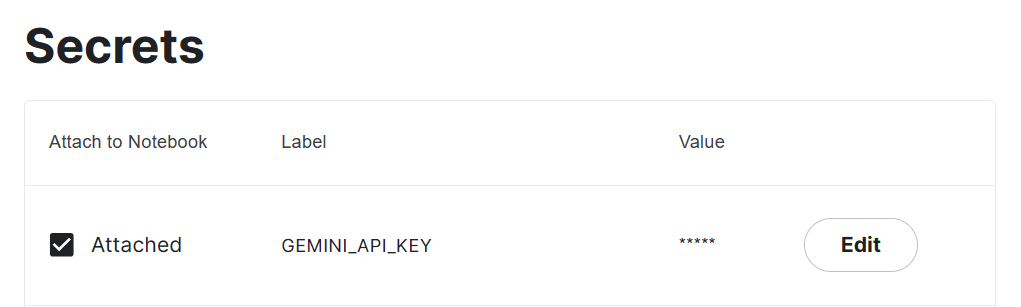
这段文字的中文翻译如下:
4. 使用pip安装Gemini Python API包。
%pip install google-generativeai5. 通过添加 API 密钥来配置 Gemini API。要访问密钥,您必须创建 UserSecretsClient 对象,然后为其提供标签。
import google.generativeai as genai
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
gemini_key = user_secrets.get_secret("GEMINI_API_KEY")
genai.configure(api_key = gemini_key)生成回复
在这一部分中,我们将学习如何使用Gemini Pro模型生成回复。如果您在自己的代码运行过程中遇到问题,您可以参考Gemini API Kaggle Notebook。
我们现在将使用免费的API来检查可用的模型访问。为此,请运行下面的代码。它将使用list_models函数显示支持的生成模型。
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)看起来我们只能访问到两个模型,”gemini-pro” 和 “gemini-pro-vision”。
models/gemini-pro
models/gemini-pro-vision让我们访问“Gemini Pro”模型,并通过提供一个简单的提示来生成一个回应。
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("请提供世界上最有影响力的人物名单。")
print(response.text)我们只需要几行代码就能生成一个非常准确的回答。

这段文字的中文翻译如下:
Gemini AI可以为提示生成多个称为候选项的响应,让您选择最合适的一个。然而,免费版本的API只提供一个候选项。
response.candidates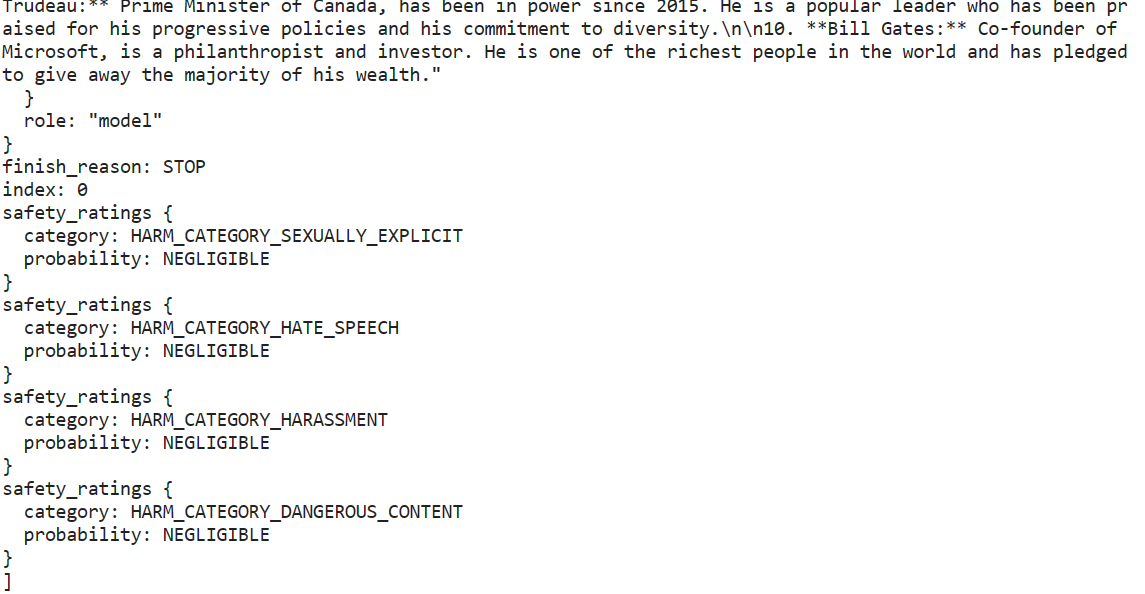
我们的输出是以Markdown格式呈现的。让我们使用IPython Markdown工具来修复它。现在我们将要求Gemini生成Python代码。
from IPython.display import Markdown
response = model.generate_content("构建一个简单的Python Web应用程序。")
Markdown(response.text)这个模型做得很好。它生成了一个逐步指南,解释了如何使用Flask构建和运行一个简单的Web应用程序。
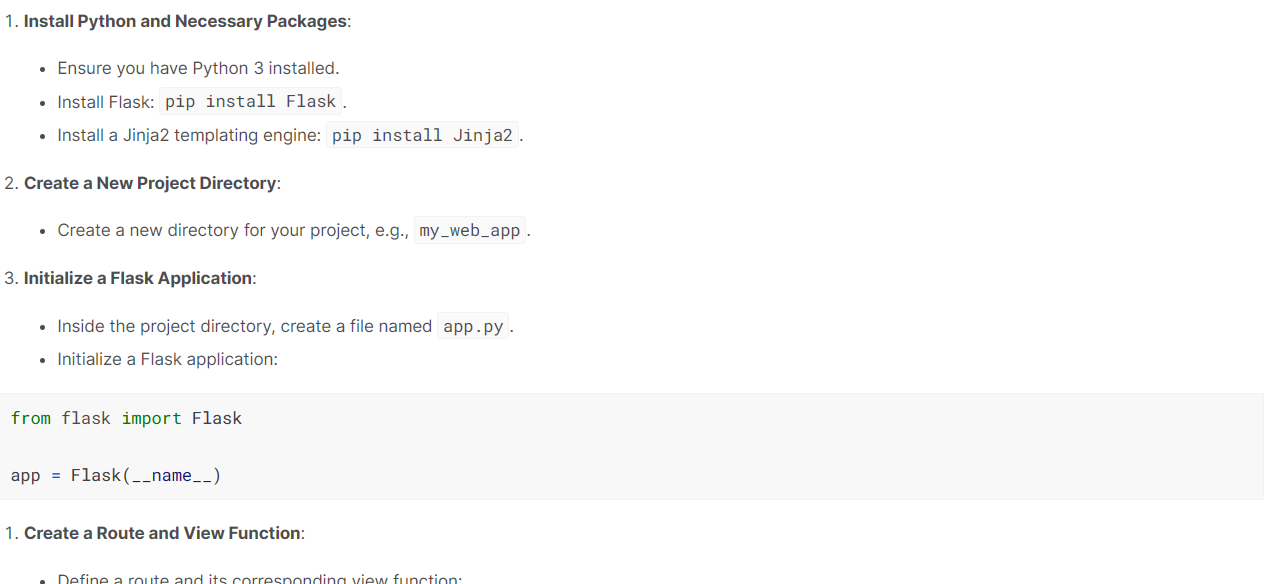
这段文字的中文翻译如下:
流式传输
使用流式传输来提高应用程序的感知速度非常重要。通过打开’stream’参数,响应将在可用时立即生成和显示。我们的输出将以块的形式生成,因此我们必须迭代响应。
from IPython.display import display
model = genai.GenerativeModel("gemini-pro")
response = model.generate_content(
"如何制作正宗的意大利面?", stream=True
)
for chunk in response:
display(Markdown(chunk.text))
display(Markdown("_" * 80))每个块都由虚线分隔。如下所示,我们的内容是以块的形式生成的。Gemini API的流式传输与OpenAI和Anthropic API类似。

这段文字的中文翻译如下:
微调回应
我们可以调整生成的回应以满足我们的要求。
在下面的示例中,我们生成一个最大长度为1000个标记,温度为0.7的候选项。此外,我们设置了一个停止序列,当生成的文本中出现单词”time”时,生成过程会自动停止。
response = model.generate_content(
'如何在疲劳期保持高效。',
generation_config=genai.types.GenerationConfig(
candidate_count=1,
stop_sequences=['time'],
max_output_tokens=1000,
temperature=0.7)
)
Markdown(response.text)
尝试使用Gemini Pro Vision
在这个部分,我们将使用Gemini Pro Vision来访问Gemini AI的多模态功能。
我们将使用curl工具从pexel.com下载Mayumi Maciel拍摄的照片。
!curl -o landscape.jpg "https://images.pexels.com/photos/18776367/pexels-photo-18776367/free-photo-of-colorful-houses-line-the-canal-in-burano-italy.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2"
为了在Kaggle Notebook中加载和查看图像,我们将使用Pillow Python包。
import PIL.Image
img = PIL.Image.open('landscape.jpg')
display(img)
为了理解这个图片的内容,我们首先需要加载“gemini-pro-vision”模型,并为其提供一个图像对象。
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)它准确地识别了图像中的位置并提供了描述。
在意大利布拉诺,这是一个美丽的日子。五彩斑斓的房屋和宁静的水域使这个地方成为放松和欣赏风景的理想之地。
让我们将提示文本和图像对象输入到我们的生成函数中,向我们的模型提问关于这张图片的问题。
response = model.generate_content(
["你能提供具体的坐标位置吗?", img]
)
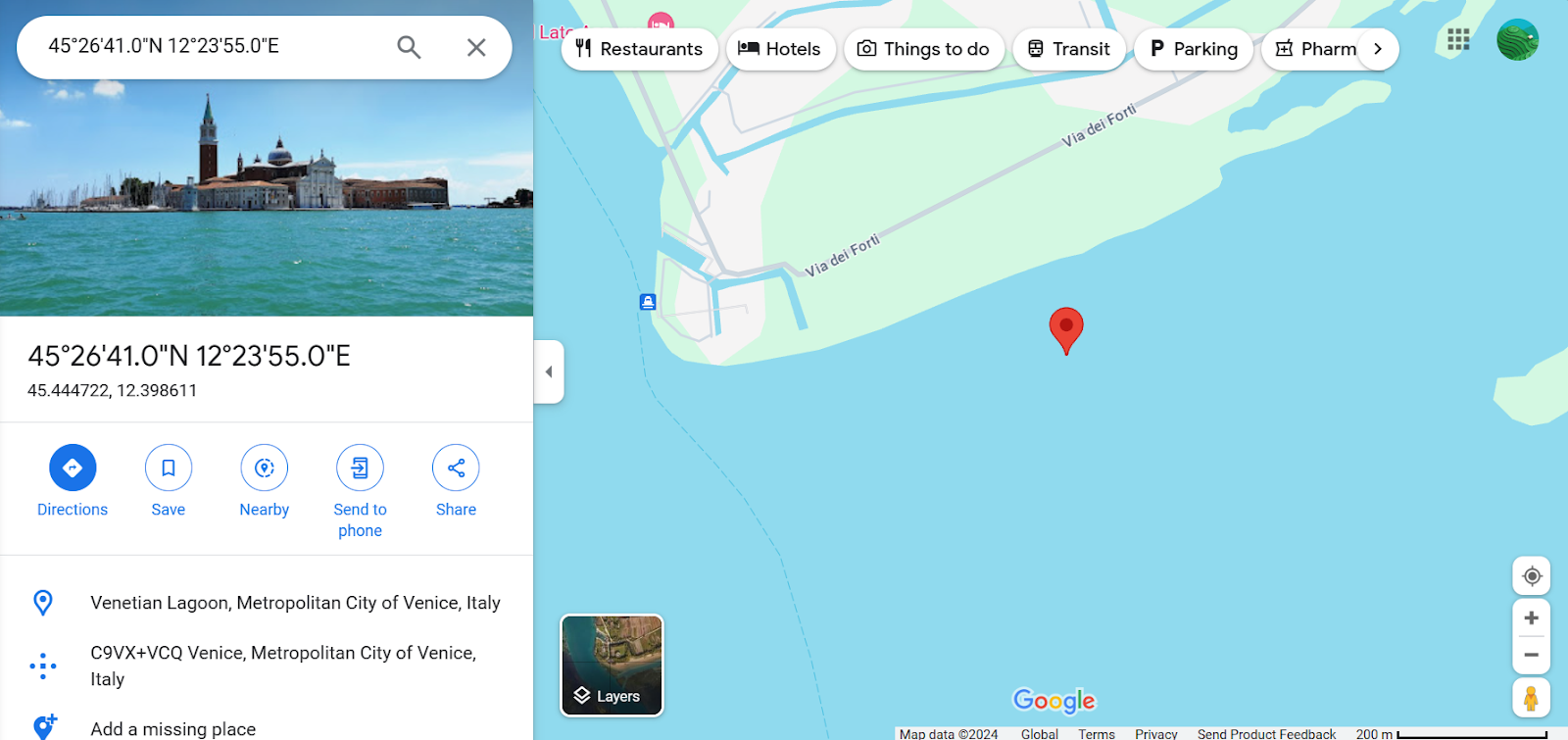
Markdown(response.text)45.4408° N, 12.3150° E它准确地提供了该地点的坐标,并且我们还通过将坐标添加到谷歌地图进行了验证。
这段文字的中文翻译如下:
聊天对话
可以与AI模型进行对话,保留聊天的上下文,使用之前对话的历史记录。这样,模型可以记住对话的内容,并根据之前的互动提供适当的回应。
我们只需要使用model.start_chat创建一个聊天对象,并提供第一条消息。
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
chat.send_message("谁创作了《蒙娜丽莎》?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))
让我们提出另一个问题,并以聊天格式显示回答。
chat.send_message("他还创造了什么?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))该模型记住了上下文并提供了适当的回答。

这段文字的中文翻译如下:
嵌入
API提供了对嵌入模型的访问,这是一种用于上下文感知应用的流行工具。通过简单的Python函数,用户可以将他们的提示或内容转换为嵌入,从而能够将单词、句子或整个文档表示为编码语义含义的密集向量。
我们将为embed_content函数提供模型名称、内容、任务类型和标题。
result = genai.embed_content(
model="models/embedding-001",
content="谁创造了《蒙娜丽莎》?",
task_type="retrieval_document",
title="蒙娜丽莎研究")
print(result['embedding'][:10])[0.086675204, -0.027617611, -0.015689207, -0.00445945, 0.07286186, 0.00017529335, 0.07243656, -0.018299067, 0.018799499, 0.028495966]要将多个内容转换为嵌入向量,您需要将字符串列表提供给 ‘content’ 参数。
result = genai.embed_content(
model="models/embedding-001",
content=[
"谁创造了《蒙娜丽莎》?",
"他还创造了什么?",
"他什么时候去世的?"
],
task_type="retrieval_document",
title="蒙娜丽莎研究2")
for emb in result['embedding']:
print(emb[:10],"\n")[0.07942627, -0.032543894, -0.010346633, -0.0039942865, 0.071596086, -0.0016670177, 0.07821064, -0.011955016, 0.019478166, 0.03784406]
[0.027897138, -0.030693276, -0.0012639443, 0.0018902065, 0.07171923, -0.011544562, 0.04235154, -0.024570161, 0.013215181, 0.03026724]
[0.04341321, 0.013262799, -0.0152797215, -0.009688456, 0.07342798, 0.0033503908, 0.05274988, -0.010907041, 0.05933596, 0.019402765]参加OpenAI API嵌入式介绍课程,了解嵌入式模型在语义搜索和推荐引擎等高级AI应用中的应用。
高级用例
为了充分发挥 Gemini API 的潜力,开发人员可能需要深入了解高级功能,如安全设置和低级 API。
- 安全设置允许用户配置内容阻止和允许在提示和响应中,确保符合社区准则。
- 低级API提供了越来越多的自定义灵活性。
- 多轮对话可以使用
GenaiChatSession类进行扩展,增强对话体验。
使用高级功能使开发人员能够创建更高效的应用程序,并为用户交互开启新的可能性。
结论
Gemini API为开发人员提供了令人兴奋的可能性,可以通过使用文本和视觉输入来构建先进的AI应用程序。其先进的模型,如Gemini Ultra,推动了AI系统在理解和生成方面的边界。
谷歌通过Python API提供的便捷访问,使将人工智能集成到应用程序中变得更加无缝。Gemini API提供了一系列功能,如内容生成、嵌入和多轮对话,使得人工智能更易于使用。Gemini AI标志着多模态理解的重大进展。
如果您对了解更多信息感兴趣,请通过参加短期的使用OpenAI API开发AI应用课程开始您的旅程。了解流行的AI应用程序(如ChatGPT和DataCamp Workspace)背后的功能。
如果您是一名专业人士,不需要实践课程,您可以使用我们的速查表来探索Python中的OpenAI API。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“将这段文字翻译成中文,不要去除视频和图片标签,保留代码块: ‘
‘”