‘
什么是Snowflake?
如果有人让我用尽可能少的词来描述Snowflake,我会选择这些:
‘
- 数据仓库
- 大规模数据
- 多云
- 分离
- 可扩展
- 灵活
- 简单
如果他们想让我详细说明,我会像这样串联这些词:
Snowflake是一种非常受欢迎的基于云的数据仓库管理平台。它因其处理大规模数据和工作负载的能力更快速和高效而脱颖而出。其卓越的性能来自其独特的架构,它使用独立的存储和计算层,使其具有极高的灵活性和可扩展性。此外,它还原生集成了多个云提供商。尽管具有这些先进功能,它仍然简单易学且易于实施。
如果他们要求更多细节,那么我会写这个教程。如果你对这个主题完全不了解,DataCamp的《Snowflake入门》课程是一个很好的起点。
为什么使用Snowflake?
Snowflake在全球拥有超过8900个客户,并每天处理39亿个查询。这种使用统计数据绝非偶然。
以下是Snowflake最吸引人的最佳优势:
1. 基于云的架构
Snowflake在云中运行,允许公司根据需求调整资源的规模,而无需担心物理基础设施(硬件)。该平台还处理常规维护任务,如软件更新、硬件管理和性能调优。这减轻了维护开销的负担,使组织能够专注于从数据中获取价值。
2. 弹性和可扩展性
Snowflake将存储和计算层分离,使用户能够独立扩展计算资源,而不受存储需求的限制。这种弹性能够以最佳性能和无需额外成本的方式高效处理各种工作负载。
3. 并发性和性能
Snowflake轻松处理高并发性:多个用户可以在不降低性能的情况下访问和查询数据。
4. 数据共享
Snowflake的安全保障能够实现与其他组织、内部部门、外部合作伙伴、客户或其他利益相关方的数据共享。无需复杂的数据传输。
5. 时间旅行
Snowflake使用一个高级术语“时间旅行”来进行数据版本控制。每当对数据库进行更改时,Snowflake会拍摄一个快照。这使得用户可以在不同的时间点访问历史数据。
6. 成本效益
由于Snowflake具有动态扩展资源的能力,它提供按需付费模式。您只需支付您使用的部分费用。
所有这些优点的结合使得Snowflake成为一个非常理想的数据仓库管理工具。
现在,让我们来看一下解锁这些功能的Snowflake的底层架构。
什么是数据仓库?
在我们深入了解Snowflake的架构之前,让我们先回顾一下数据仓库,以确保我们都在同一个页面上。
数据仓库是一个集中存储公司来自各种来源的大量结构化和组织化数据的存储库。组织中的不同角色(员工)使用其中的数据来得出不同的见解。
例如,数据分析师与营销团队合作,可以使用销售表格来运行一项新的营销活动的A/B测试。人力资源专员可以查询员工信息以跟踪绩效。这些是全球公司如何利用数据仓库推动增长的一些示例。但是,如果没有像Snowflake这样的工具进行适当的实施和管理,数据仓库将仍然只是复杂的概念。
您可以通过我们的数据仓库课程了解更多关于这个主题的内容。
雪花架构
雪花独特的架构,旨在加快分析查询速度,源于其存储和计算层的分离。这种区分有助于前面提到的优势。
存储层
在Snowflake中,存储层是一个关键组件,以高效和可扩展的方式存储数据。以下是该层的一些关键特性:
- 基于云的:Snowflake与主要的云提供商(如AWS、GCP和Microsoft Azure)无缝集成。
- 列式存储格式:Snowflake以列式存储格式存储数据,针对分析查询进行了优化。与像Postgres这样的传统基于行的格式不同,列式存储格式非常适合数据聚合。在列式存储中,查询只访问所需的特定列,使其更高效。而基于行的格式则需要在内存中访问所有行,以进行诸如计算平均值之类的简单操作。
- 微分区:Snowflake使用一种称为微分区的技术,将表以小块存储在内存中。每个块通常是不可变的,大小只有几兆字节,这使得查询优化和执行速度更快。
- 零拷贝克隆:Snowflake具有一项独特的功能,可以创建数据的虚拟克隆。克隆是瞬时的,并且在对新副本进行更改之前不会消耗额外的内存。
- 可扩展性和弹性:存储层水平扩展,这意味着它可以通过添加更多服务器来处理不断增长的数据量。此外,这种扩展与计算资源无关,这在您希望存储大量数据但仅分析其中一小部分时非常理想。
现在,让我们来看看计算层。
计算层
顾名思义,计算层是执行查询的引擎。它与存储层配合工作,处理数据并执行各种计算任务。以下是关于该层如何操作的更多细节:
- 虚拟仓库:您可以将虚拟仓库视为处理查询处理的计算机团队(计算节点)。团队的每个成员处理查询的不同部分,使执行速度快且并行。Snowflake提供不同大小的虚拟仓库,因此价格也不同(大小包括XS、S、M、L、XL)。
- 多集群、多节点架构:计算层使用多个集群和多个节点进行高并发,允许多个用户同时访问和查询数据。
- 自动查询优化:Snowflake的系统分析所有查询并识别模式,使用历史数据进行优化。常见的优化包括修剪不必要的数据、使用元数据和选择最高效的执行路径。
- 结果缓存:计算层包括一个缓存,用于存储频繁执行的查询结果。当再次运行相同的查询时,结果几乎立即返回。
这些计算层的设计原则都有助于Snowflake在云中处理不同和要求高的工作负载。
云服务层
最后一层是云服务层。由于这一层与Snowflake架构的每个组件都集成在一起,因此其操作细节非常多。除了与其他层相关的功能外,它还具有以下额外的责任:
- 安全性和访问控制:该层实施安全措施,包括身份验证、授权和加密。管理员使用基于角色的访问控制(RBAC)来定义和管理用户角色和权限。
- 数据共享:该层实现了安全的数据共享协议,可以在不同的账户甚至第三方组织之间进行数据共享。数据消费者可以访问数据而无需进行数据移动,促进协作和数据变现。
- 半结构化数据支持:Snowflake的另一个独特优势是其能够处理半结构化数据,如JSON和Parquet,尽管它是一个数据仓库管理平台。它可以轻松查询半结构化数据,并将结果与现有表集成。这种灵活性在其他关系型数据库管理系统工具中是不常见的。
现在我们对Snowflake的架构有了一个高层次的了解,让我们在平台上编写一些SQL语句。
设置SnowflakeSQL
Snowflake有自己的SQL版本,称为SnowflakeSQL。它与其他SQL方言的区别类似于英语口音之间的区别。
在像PostgreSQL这样的方言中执行的许多分析查询不会改变,但是在DDL(数据定义语言)命令中存在一些差异。
Snowflake提供两种运行SnowSQL的接口:
- Snowsight: 一个用于与平台交互的Web界面。
- SnowSQL: 用于管理和查询数据库的CLI(命令行界面)客户端。
我们将看到如何设置并运行一些查询!
Snowsight: Web界面
首先,进入Snowflake主页,然后选择“免费开始”。输入个人信息并选择任何列出的云服务提供商。选择并不重要,因为免费试用包括价值400美元的积分,可以用于任何选项(您不需要自己设置云凭据)。
验证您的电子邮件后,您将被重定向到工作表页面。工作表是交互式的、实时编码环境,您可以在其中编写、执行和查看SQL查询的结果。
这段文字的中文翻译如下:
为了运行一些查询,我们需要一个数据库和一个表(我们不会使用Snowsight中的示例数据)。下面的GIF演示了如何使用本地CSV文件创建一个名为“test_db”的新数据库和一个名为“diamonds”的表。您可以通过在终端中运行此GitHub gist中的代码来下载CSV文件。
这段文字的中文翻译如下:
在这个GIF中,Snowsight告诉我们其中一个列名存在问题。由于单词“table”是一个保留关键字,我将其用双引号括起来。
之后,您将被引导到一个新的工作表,您可以在其中运行任何SQL查询。如GIF所示,工作表界面非常简单直观且功能强大。请花几分钟时间熟悉面板、按钮及其相应位置。
SnowSQL: CLI
没有什么比从终端管理和查询一个完整的数据库更令人兴奋了。这就是为什么有了SnowSQL!
然而,要使其运行起来,我们需要遵循一些步骤,这通常比开始使用Snowsight的过程要慢一些。
作为第一步,从Snowflake开发者下载页面下载SnowSQL安装程序。下载相关文件。由于我使用的是WSL2,我将选择Linux版本:
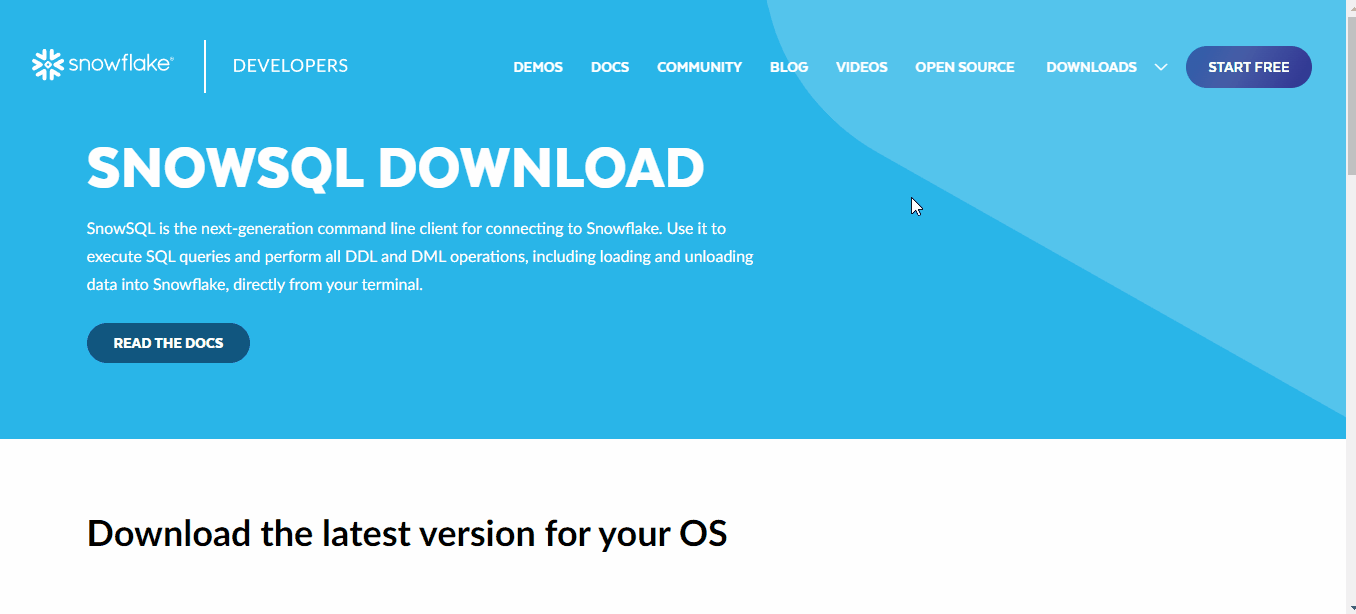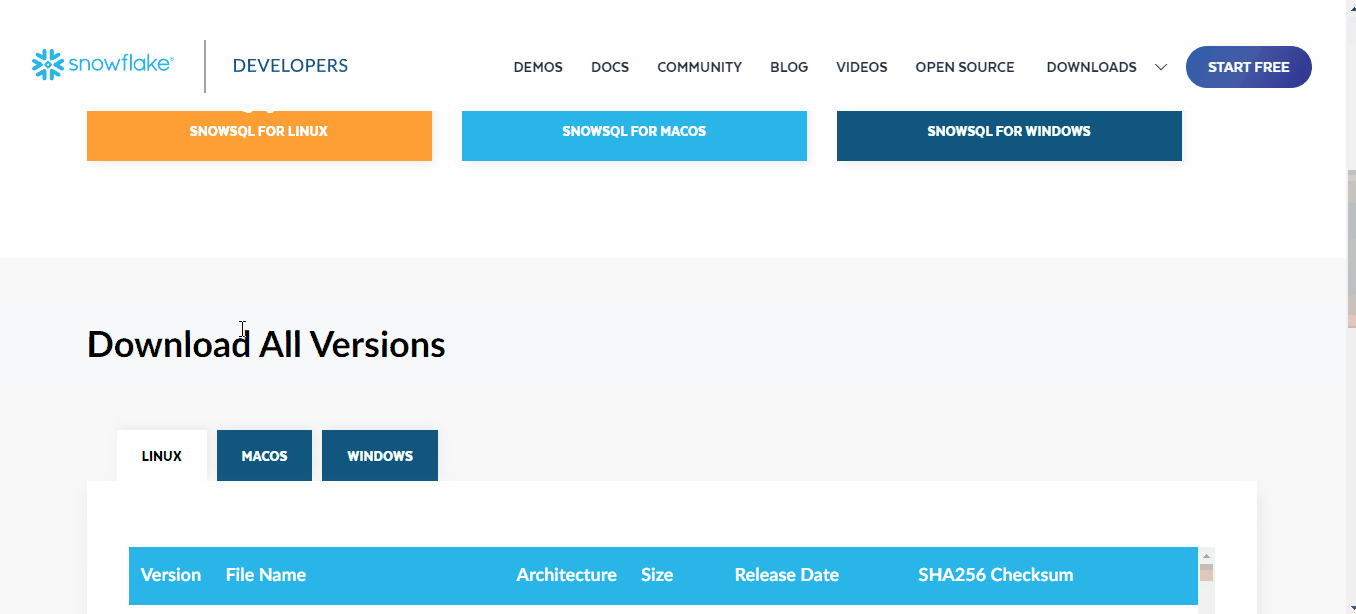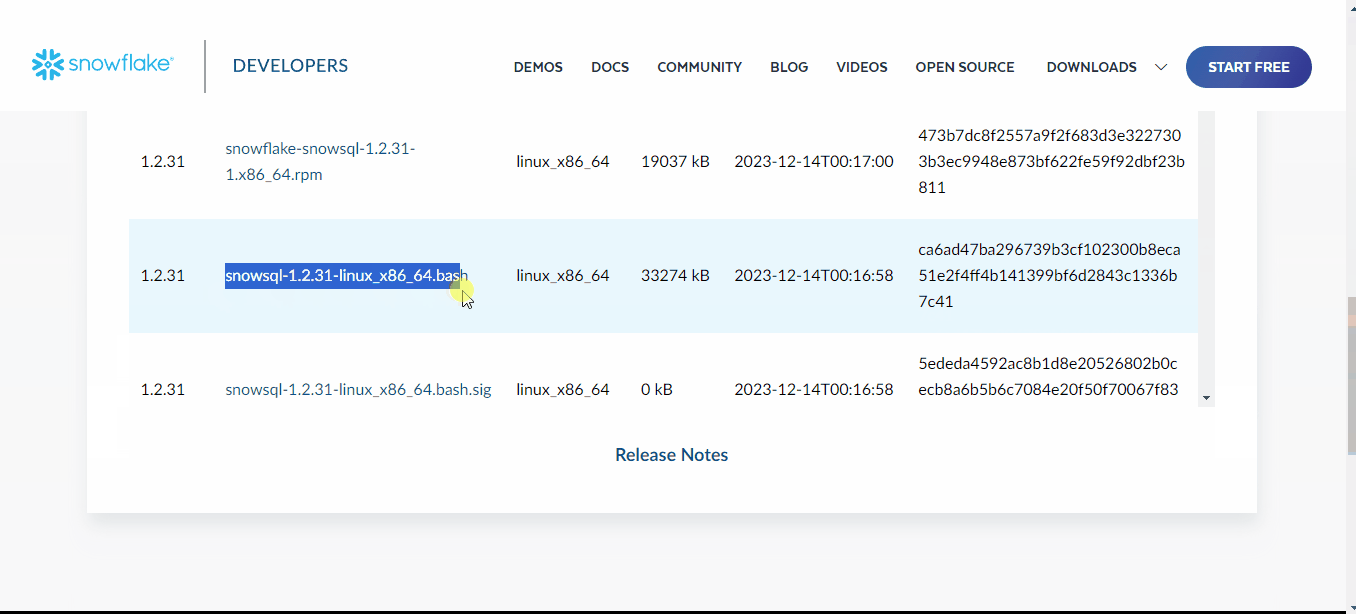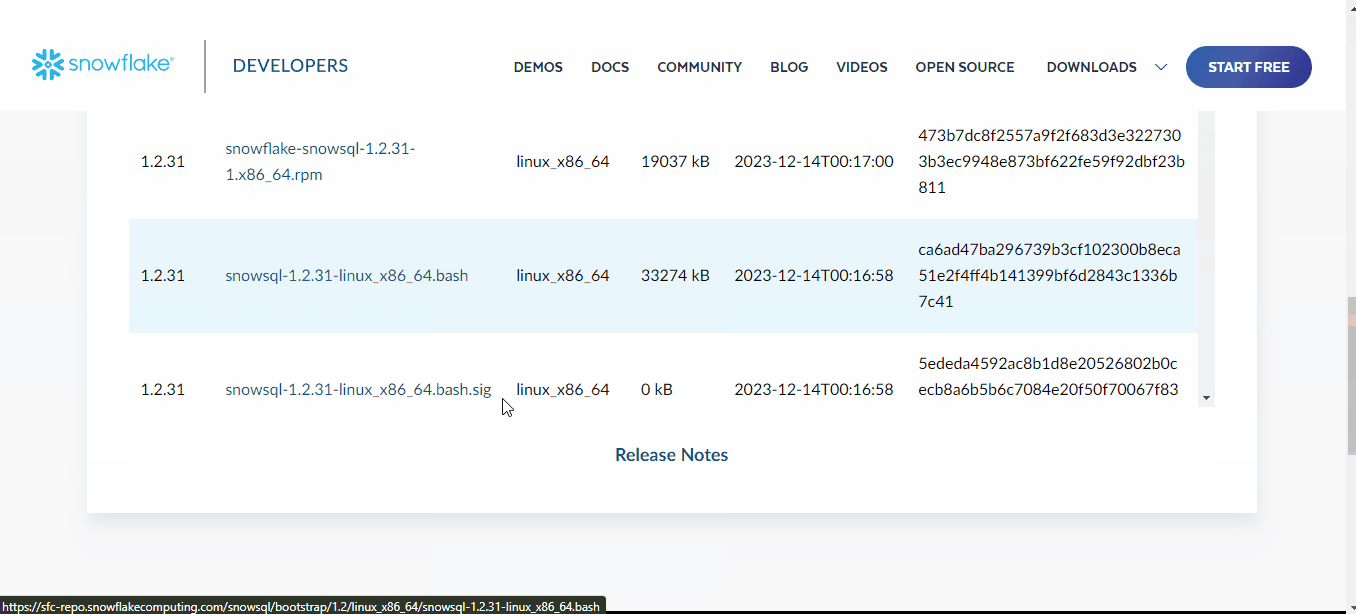
这段文字的中文翻译如下:在终端中,我使用复制的链接下载文件,并使用bash执行它:
$ curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.31-linux_x86_64.bash
$ bash snowsql-1.2.31-linux_x86_64.bash
对于其他平台,您可以按照Snowflake文档的此页面上的安装步骤进行操作。
安装成功后,您应该会收到以下消息:
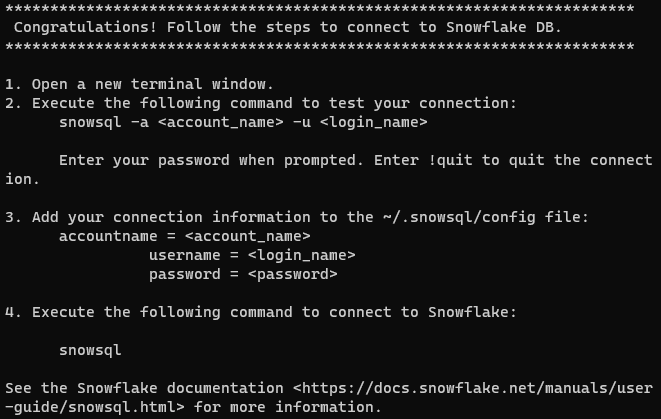
这段文字的中文翻译如下:
注意:在类Unix系统上,确保在所有终端会话中都可以使用snowsql命令非常重要。为了实现这一点,您应该将/home/username/bin目录添加到您的$PATH变量中。您可以通过将以下行追加到您的.bashrc、.bash_profile或.zshrc文件中来实现这一点:export PATH=/home/yourusername/bin:$PATH。请记得将yourusername替换为您的实际用户名。
这条消息提示我们配置帐户设置以连接到Snowflake。有两种方法可以做到这一点:
- 在终端中以交互方式传递帐户详细信息。
- 在全局Snowflake配置文件中配置凭据。
由于第二个选项更加永久和安全,我们将继续进行。有关特定平台的说明,请阅读通过SnowSQL连接文档页面。以下说明适用于类Unix系统。
首先,打开您的电子邮件地址,找到来自Snowflake的欢迎邮件。邮件中包含登录链接中的账户名:account-name.snowflakecomputing.com。请复制它。
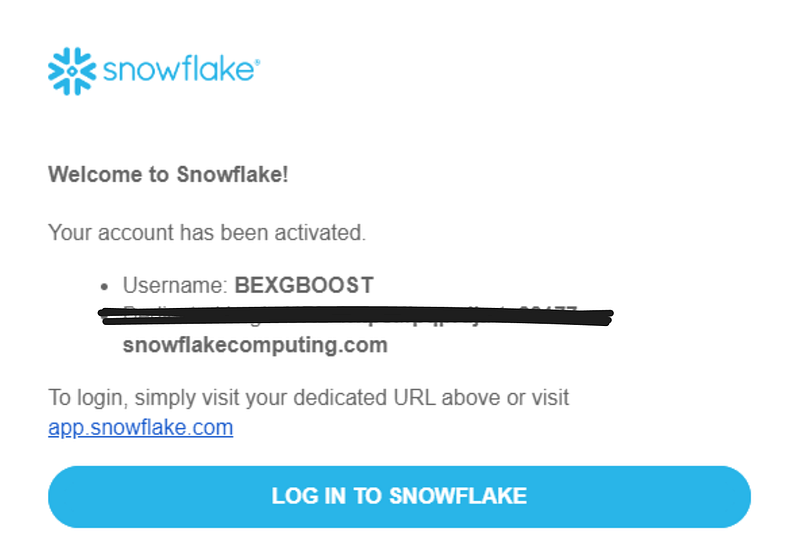
这段文字的中文翻译如下:
接下来,使用VIM或VSCode等文本编辑器打开~/.snowsql/config文件。在connections部分下,取消注释以下三个字段:
- 账户名
- 用户名
- 密码
用你复制的账户名以及注册时提供的用户名和密码替换默认值。完成后,保存并关闭文件。
然后,返回终端并输入 snowsql。客户端应自动连接并提供一个包含代码高亮和标签补全等功能的 SQL 编辑器。下面是它应该看起来的样子:
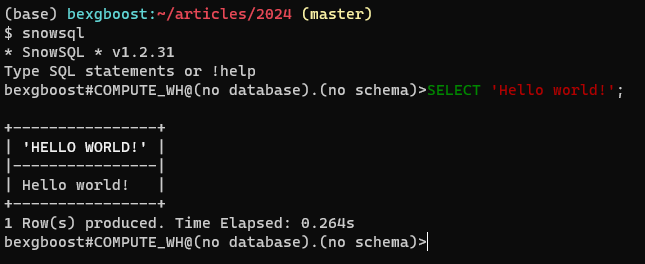
这段文字的中文翻译如下:
在SnowSQL中连接到现有数据库
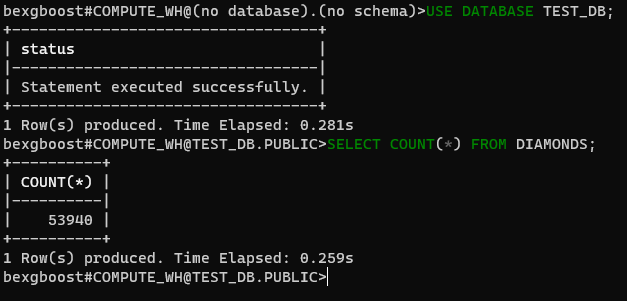
目前,我们没有连接到任何数据库。让我们通过连接到我们用Snowsight创建的test_db数据库来解决这个问题。首先,使用SHOW DATABASES命令检查可用的数据库:
$ SHOW DATABASES
$ USE DATABASE TEST_DB
接下来,指定你将从现在开始使用大小写不敏感的test_db数据库。然后,你可以在连接的数据库的表上运行任何SQL查询。
$ SELECT COUNT(*) FROM DIAMONDS
在SnowSQL中创建新数据库和表
如果您是一个大型组织的一员,可能会有一些情况需要您负责创建数据库并将其填充到现有数据中。为了练习这种情况,让我们尝试将Diamonds数据集作为一个表上传到SnowSQL中的一个新数据库中。您可以按照以下步骤进行操作:
1. 创建一个新的数据库:
CREATE DATABASE IF NOT EXISTS new_db;2. 使用数据库:
USE DATABASE new_db;3. 为CSV创建一个文件格式:
CREATE OR REPLACE FILE FORMAT my_csv_format -- 可以任意命名
TYPE = CSV
FIELD_DELIMITER = ','
SKIP_HEADER = 1; -- 假设第一行是标题
我们必须手动定义一个文件格式并命名,因为Snowflake无法推断出诸如CSV、JSON或XML等数据文件的模式和结构。我们上面定义的文件格式适用于我们拥有的diamonds.csv文件(它是逗号分隔的并包含标题)。
4. 创建一个内部阶段:
CREATE OR REPLACE STAGE my_local_files;
在Snowflake中,stage是一个存储区域,您可以在其中上传本地文件。这些文件可以是结构化和半结构化数据文件。上面的代码是创建了一个名为my_local_files的stage。
5. 将CSV文件放入舞台:
PUT file:///home/bexgboost/diamonds.csv @my_local_files;
6. 创建表:
CREATE TABLE diamonds (
carat FLOAT,
cut VARCHAR(255),
color VARCHAR(255),
clarity VARCHAR(255),
depth FLOAT,
table FLOAT,
price INTEGER,
x FLOAT,
y FLOAT,
z FLOAT
);
7. 从舞台加载数据到表中:
COPY INTO diamonds
FROM @my_local_files/diamonds.csv
FILE_FORMAT = my_csv_format;
8. 验证:
SELECT COUNT(*) FROM diamonds;
以下步骤将创建一个新的Snowflake数据库,定义一个CSV文件格式,创建一个用于存储本地文件的stage,将CSV文件上传到stage,创建一个新表,将CSV数据加载到表中,最后通过计算表中行数来验证操作。
如果结果返回行数,恭喜您成功创建了一个数据库,并使用SnowSQL将本地数据加载到其中。现在,您可以按照自己的喜好查询表格。
结论和进一步学习
哇!我们从一些简单的概念开始,但到最后,我们真的深入了复杂的细节。嗯,这就是我对一个不错的教程的理解。
你可能已经猜到了,Snowflake比我们所介绍的要复杂得多。事实上,Snowflake的文档包括了一些实际上有128分钟长的快速入门指南!但在你开始阅读那些之前,我建议你先尝试一些其他资源。比如这些:
- Snowflake入门课程
- 使用Snowflake进行销售分析现代化的网络研讨会
- 使用Python和SQL在Snowflake中进行数据分析的代码示例
- Snowflake官方用户指南
- Snowflake开发者资源
感谢阅读!
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”