首先,有数据仓库。它们以行和列的形式存储数据,因为当时的互联网和计算机只能处理简单的文本信息。很久以后出现了数据湖 – 它们可以存储几乎任何类型的数据。它们非常适合社交媒体和YouTube时代。
代码块: ‘
First, there were data warehouses. They stored data in rows and columns because all the Internet and computers of the time were capable of distributing was simple text information. Much later came data lakes — they could store nearly any type of data you could collect. They were great for the social media and YouTube age.
‘
但是它们都有缺点 – 数据仓库昂贵且不适合现代数据科学,而数据湖杂乱无章,经常变成数据沼泽。因此,公司开始拥有两个独立的技术堆栈 – 用于商业智能和分析的仓库,以及用于机器学习的湖泊。
然而,管理两种不同的数据架构非常麻烦,导致公司通常结果不佳。这个问题催生了“湖屋架构”,这正是Databricks所闻名的。
Databricks是一个基于云的平台,允许用户在统一环境中从数据仓库和数据湖中获取价值。本文将概述该平台,展示其最重要的特性以及如何使用它们。
本Databricks教程将涵盖的内容
Databricks是一个庞大的平台,其文档本身可以成为一本书。因此,本文的目标是为您提供一个概念层次结构 – Databricks功能的线性排序解释,将使您从初学者成为一个合格的Databricks从业者。如果您是一个完全的新手,您可能还想查看我们的Databricks入门课程。
让我们开始吧!
1. 什么是Databricks?
当你听到Databricks这个词时,你应该立刻将其视为一个平台,而不是某个框架或Python库。通常,平台提供各种各样的功能,Databricks也不例外。它是为任何数据专业人员提供的少数几个平台之一,从数据工程师到现代机器学习工程师(或者媒体今天称之为AI程序员)。
Databricks具有以下核心组件:
- 工作空间: Databricks提供了一个集中的环境,团队可以在其中进行协作,无需任何麻烦。该环境可以通过用户友好的Web界面访问。
- 笔记本: Databricks具有专为协作和灵活性而设计的Jupyter笔记本版本。
- Apache Spark: Databricks热爱Apache Spark。它是支持处理海量数据集的所有并行处理的引擎,非常适合大数据分析。
- Delta Lake: 通过提供ACID事务来增强数据湖。Delta Lake确保数据的可靠性和一致性,解决了与数据湖相关的传统挑战。
- 可扩展性: 该平台水平扩展而不是垂直扩展,非常适合处理不断增长的数据需求的组织。
Databricks的好处
这些组件的组合可以带来广泛的好处:
- 跨团队协作:工程师、分析师、科学家和机器学习工程师可以在同一平台上无缝协作。
- 一致性:使用笔记本,用户可以在不需要切换上下文的情况下切换任务和编程语言。
- 高效工作流程:用户可以以一种协调一致的方式执行数据清洗、转换和机器学习等任务。
- 集成数据管理:用户可以从多个来源将数据导入平台,创建表格并运行SQL。
- 实时协作:共享笔记本和协作编辑功能实现实时协作。多个团队成员可以同时在同一笔记本上工作。
如果我已经让您相信了Databricks在数据世界中的重要性,让我们开始使用这个平台吧。
2. 账户设置
要设置您的账户,请访问 https://www.databricks.com/try-databricks 并注册 Community Edition。
这段文字的中文翻译如下:
Community Edition(社区版)比企业版功能较少,但不需要云服务提供商的设置,非常适合像教程这样的小型用例。
如果您在电子邮件验证后看到此页面,那么您可以继续进行:
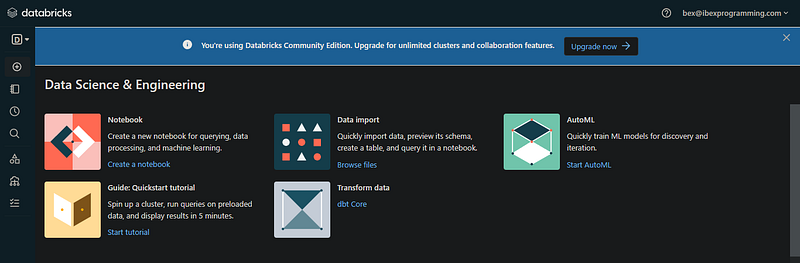
这段文字的中文翻译如下:
3. Databricks工作区
您发现的界面是您的电子邮件地址的工作区(可以轻松找到社区版工作区)。在实践中,通常是您公司的账户管理员创建一个Databricks账户,并管理对工作区的访问权限。
现在,让我们了解一下平台的用户界面。在左侧面板上,我们有不同组件Databricks提供的菜单。企业版将有更多的按钮:
这段文字的中文翻译如下:
菜单中的第一个选项是工作区类型,默认设置为数据科学和工程。如果您可以将其更改为机器学习,将会出现一个新的实验选项:

这段文字的中文翻译如下:
表面上看起来它可能没有太多功能,但一旦您升级您的账户并开始调试,您将会注意到该平台的一些很棒的特性:
- 资源的中央枢纽:笔记本、集群、表格、库和仪表板
- 多种语言的笔记本
- 集群管理:管理工作区的计算资源以执行代码
- 表格管理
- 仪表板创建:数据库用户可以将可视化内容收集到工作区的仪表板中
- 协作实时编辑笔记本
- 笔记本的版本控制
- 作业调度(强大的功能):用户可以按指定的时间间隔执行笔记本和脚本
等等。
现在,让我们更仔细地看一些这些组件。
4. Databricks Clusters
Databricks中的集群是用于执行数据处理任务的计算资源。通常,在帐户设置期间,您可以选择云提供商来提供集群。
社区版集群的RAM和CPU功率有限,不包括GPU。然而,高级用户通常可以以简单的方式执行以下任务:
- 数据处理:使用Spark的并行处理能力,集群用于处理和转换大量数据。
- 机器学习:您可以使用Python(或任何其他语言)及其库进行模型训练和推断。
- ETL工作流程:集群还通过高效处理和转换数据从源到目的地来支持提取、转换和加载工作流程。
要创建一个集群,您可以使用“创建”按钮或菜单中的“计算”选项:
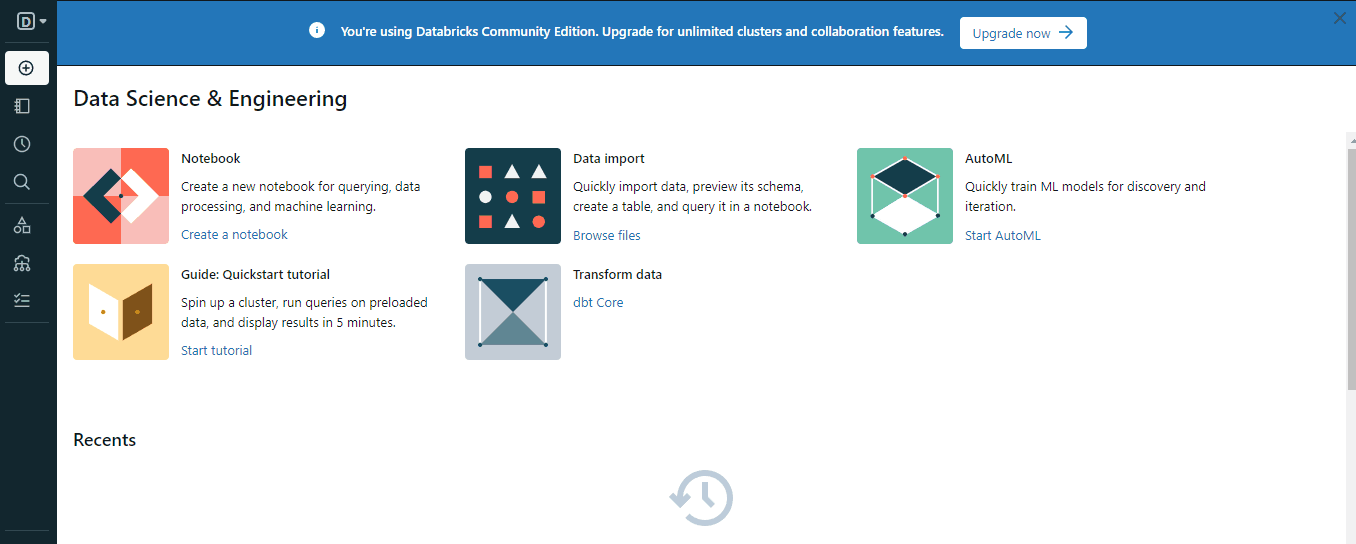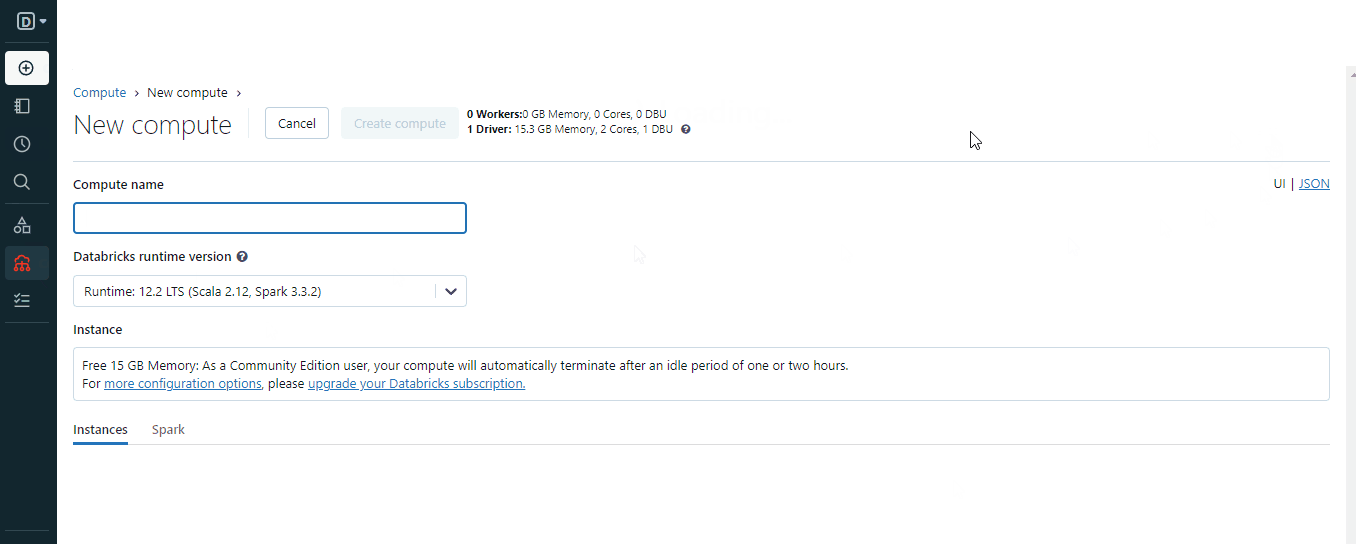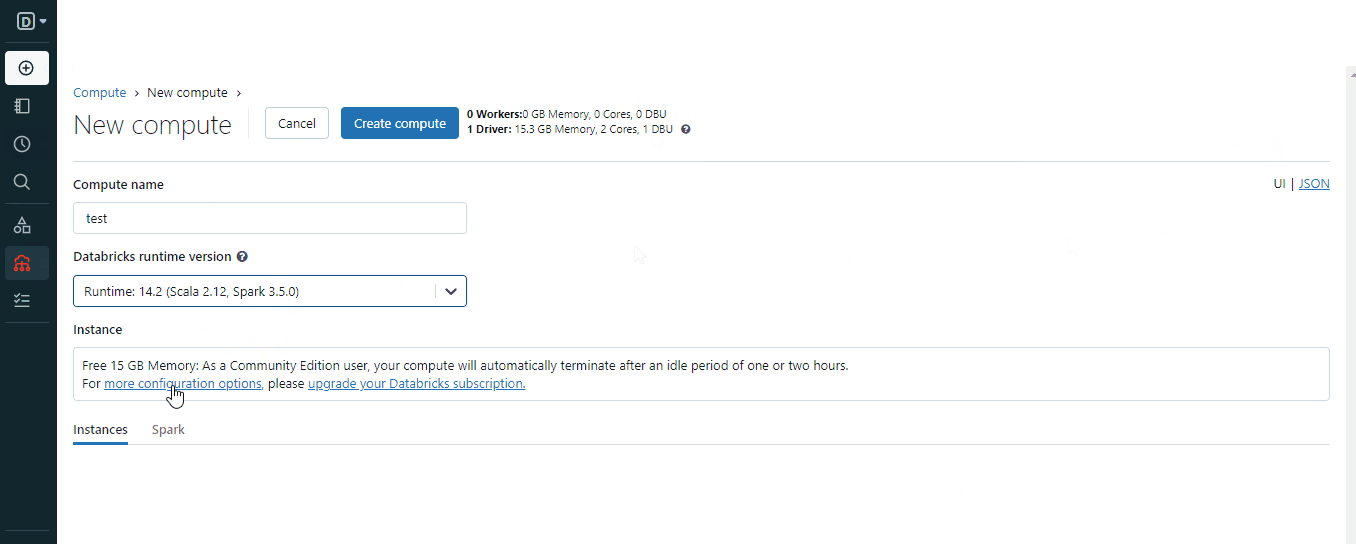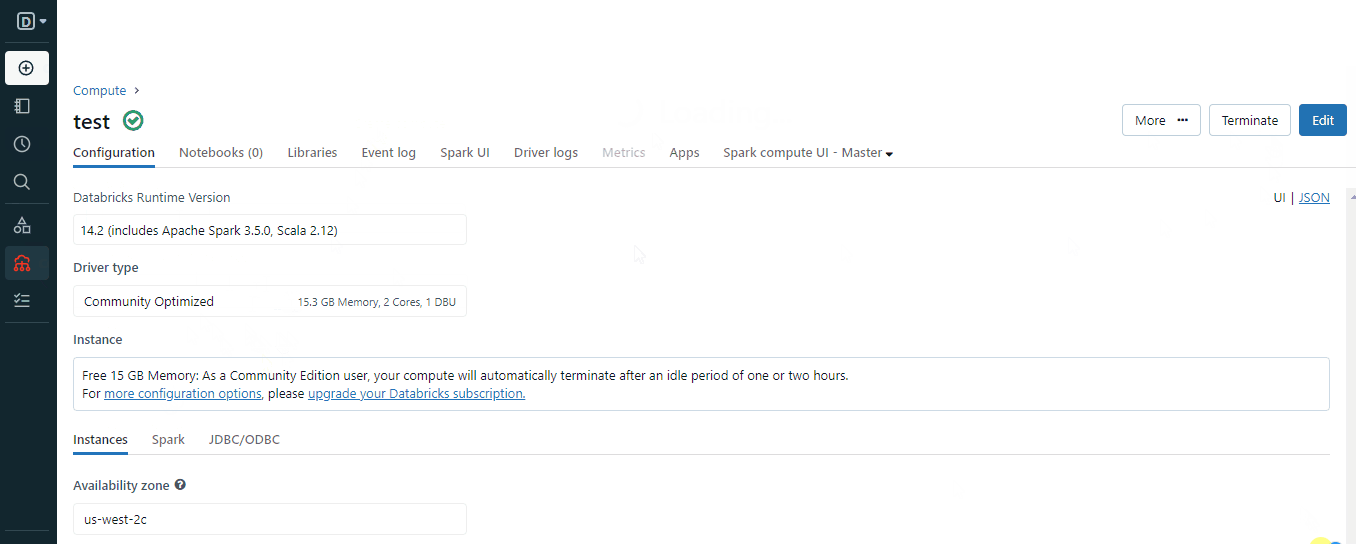
这段文字的中文翻译如下:
在创建集群时,请选择适合您环境的合适的Spark版本,并等待几分钟使其正常运行。
5. Databricks笔记本
一旦您有一个运行中的集群,您就可以开始创建笔记本。如果您曾经使用过Jupyter、Colab或DataCamp工作区,这将会很熟悉:
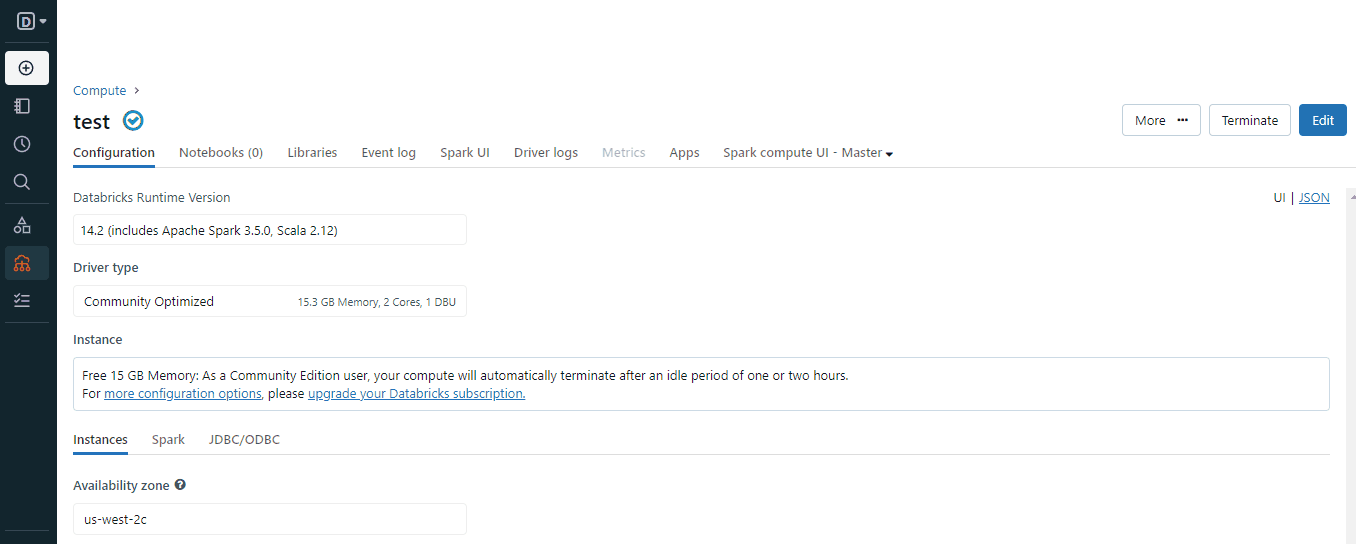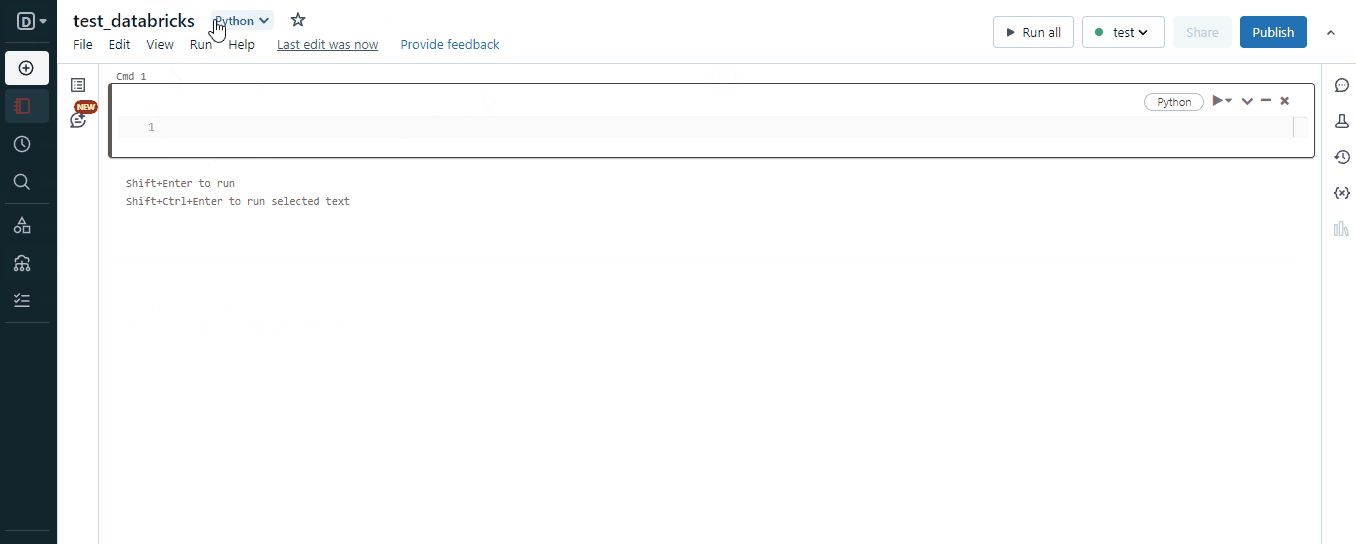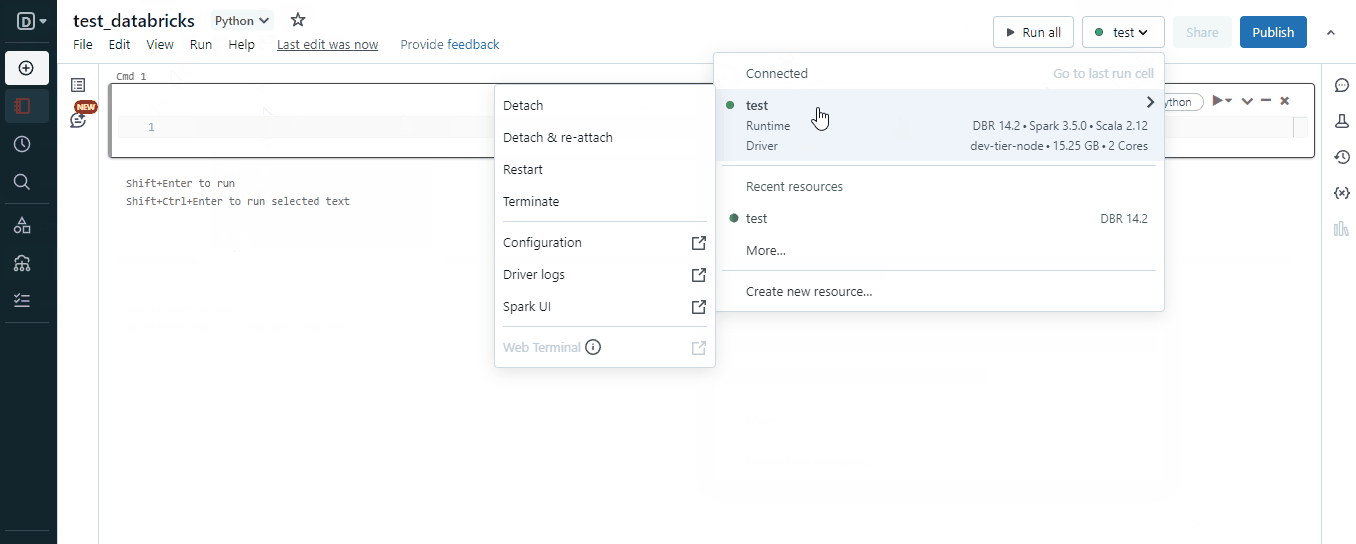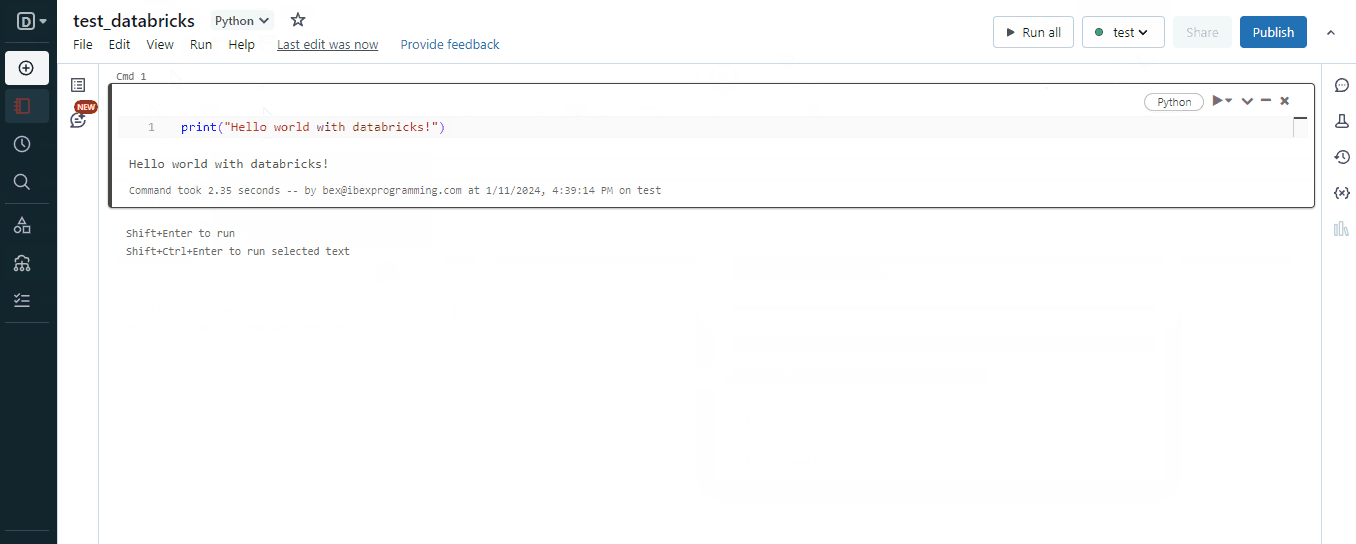
这段文字的中文翻译如下:在一个真正存在Jupyter的世界中,为什么要选择“类似于Jupyter”的东西呢?嗯,Databricks笔记本相比Jupyter笔记本具有以下优势:
- 协作:内置的协作功能允许多个用户同时在同一个笔记本上工作。更改会实时跟踪。
- 执行环境:大多数Jupyter环境提供者或本地实例依赖于预定义硬件的单台机器。用户必须自行安装外部库和依赖项。相比之下,Databricks笔记本由集群提供支持,可以自动处理资源和工作负载的扩展。它们还带有预填充的环境。
- 与大数据技术的集成:Jupyter可以与Apache Spark一起使用,但用户需要手动管理Spark会话和依赖项。由于Databricks是由Spark的创建者创立的,它原生支持该框架。Spark会话和集群由Databricks平台自动管理。
Databricks笔记本相比Jupyter还有许多其他优势,因此这里是一个总结差异的表格:
|
特点 |
Jupyter Notebooks ‘ |
Databricks笔记本 |
|
平台 |
开源,可以在本地或云平台上运行 |
独家提供给Databricks平台 |
|
合作与分享 |
有限的协作功能,手动共享 |
内置协作,实时并发编辑 |
|
执行 |
依赖本地或外部服务器 |
在Databricks集群上执行 |
|
与大数据的集成 |
可以与Spark集成,需要额外的配置 |
与Apache Spark原生集成,针对大数据进行优化 |
|
内置功能 |
版本控制、协作和可视化的外部工具/扩展 |
与Delta Lake等Databricks特定功能集成,内置协作和分析工具支持 |
|
成本和扩展性 |
本地安装通常是免费的,云端解决方案可能会有费用 |
付费服务,费用根据使用情况而定,与Databricks集群无缝扩展 |
|
使用便捷性 |
在数据科学界广为人知和广泛使用 |
专为大数据分析而定制,对于Databricks特定功能可能有较陡的学习曲线 |
|
数据可视化 |
有限的内置数据可视化支持 |
在笔记本环境中内置了对数据可视化的支持 |
|
集群管理 |
用户需要手动管理Spark会话和依赖关系 |
Databricks平台自动处理集群管理和扩展 |
|
使用案例 |
适用于各种数据科学任务 |
专为Databricks平台内的协作大数据分析而设计 |
最终,Databricks笔记本的上述优势在特定的使用情况下发挥作用。如果你想在笔记本电脑上使用Pandas玩弄一个CSV数据集,Jupyter更好。
但是,对于企业级应用程序来说,作为一个平台的Databricks可能是一个更好的选择。
6. 将数据导入Databricks
数据导入是指从各种来源导入数据的过程。Databricks支持从多种来源进行数据导入,包括:
- AWS S3
- Azure Blob Storage
- Google Cloud Storage
- 关系型数据库(MySQL,PostgreSQL等)
- 数据湖(Delta Lake,Parquet,Avro等)
- 流媒体平台(Apache Kafka)
- Google BigQuery
- 您拥有的本地CSV文件
等等。
现在,让我们实际看看如何将特定类型的数据加载到Databricks中。我们将从本地文件开始:
这段文字的中文翻译如下:
一旦你按照GIF中的步骤操作,你将在工作空间中存储一个文件。以下是如何使用Spark加载它的方法:
# 导入必要的库
from pyspark.sql import SparkSession
# 创建一个Spark会话
spark = SparkSession.builder.appName(“S3ImportExample”).getOrCreate()
# 定义数据的CSV路径
path = “dbfs:/FileStore/tables/diamonds.csv”
# 从S3中读取数据到DataFrame中
data_from_s3 = spark.read.csv(path, header=True, inferSchema=True)
# 显示导入的数据
data_from_s3.show()
请注意`dbfs:`前缀。所有工作空间文件必须包含它,以便Spark正确加载文件。DBFS代表Databricks文件系统。
从S3存储桶导入数据与企业账户类似:
# 导入必要的库
from pyspark.sql import SparkSession
# 创建一个Spark会话
spark = SparkSession.builder.appName(“S3ImportExample”).getOrCreate()
# 定义数据在S3中的路径
s3_path = “s3://your-bucket/your-data.csv”
# 从S3中读取数据到DataFrame中
data_from_s3 = spark.read.csv(s3_path, header=True, inferSchema=True)
# 显示导入的数据
data_from_s3.show()
对于其他类型的数据,您可以查看Databricks文档中的数据工程和连接到数据源部分。
7. 在Databricks中运行SQL
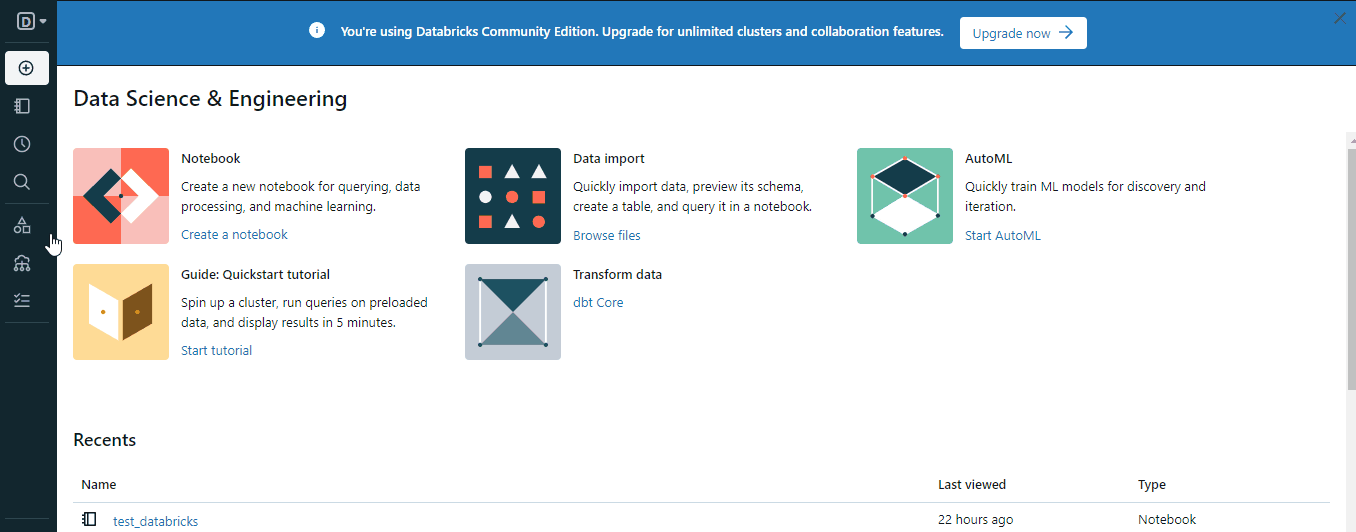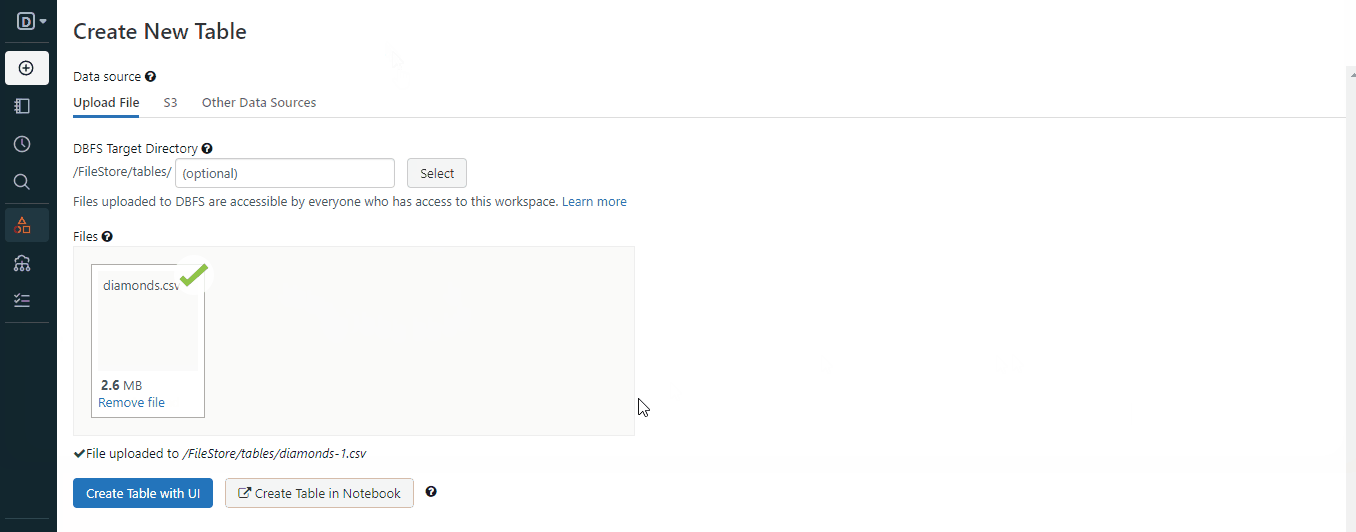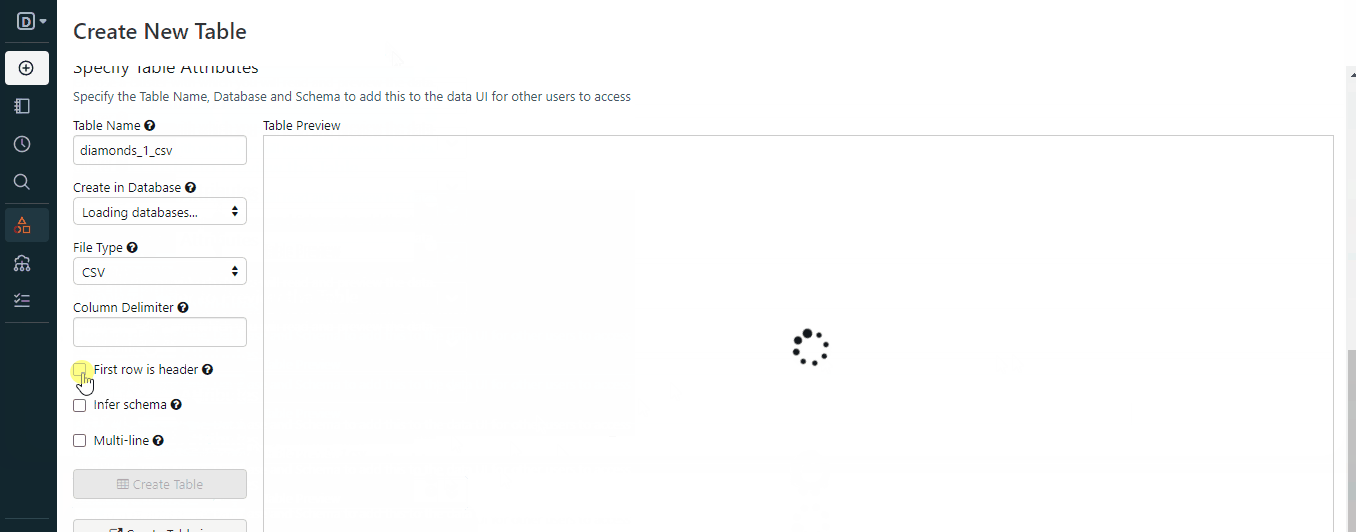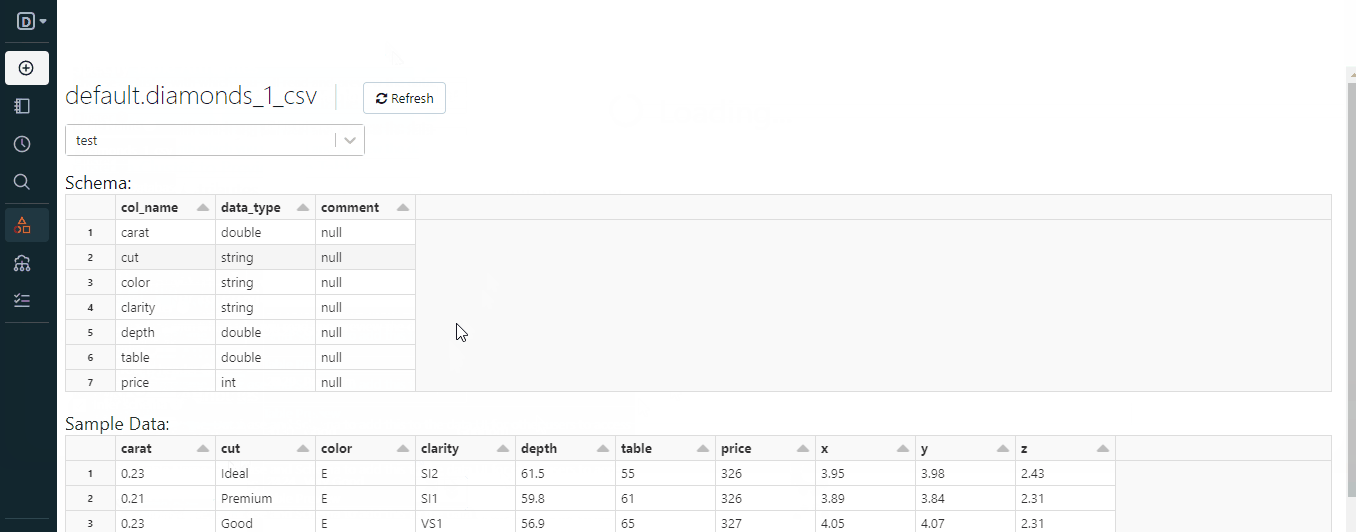
当我们上传了diamonds.csv文件后,它成为了一个名为default的数据库中的Databricks表:
这段文字的中文翻译如下:
当我们尝试加载结构化文件而没有先创建数据库时,会创建这个名为default的数据库。
如果我们有一个数据库,那意味着我们可以使用SQL来查询它,而不仅仅是使用Spark。要这样做,创建一个新的笔记本或将当前笔记本的语言更改为SQL。然后,尝试以下代码片段:
SELECT * FROM default.diamonds_1_csv
LIMIT 5;
它必须返回钻石表的前五行:
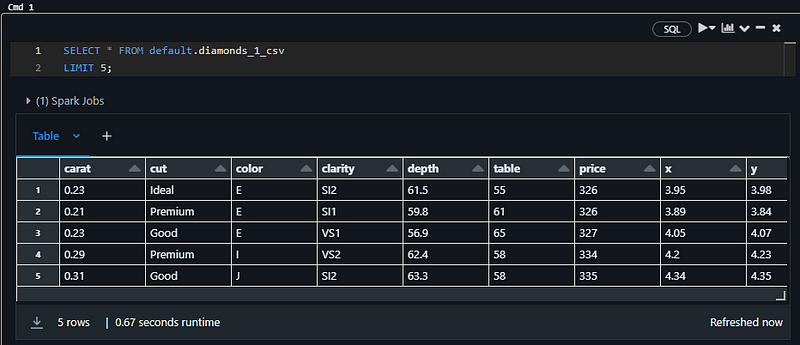
这段文字的中文翻译如下:
注意:我在上面的代码片段中使用了一个SQL笔记本
你也可以在Pandas中加载这个表格。在同一个笔记本中,粘贴以下代码块:
%python
# 导入必要的库
import pandas as pd
# 假设'default'是数据库名称,'diamonds'是表名称
# 使用spark.sql函数查询表并检索数据
table_df = spark.sql("SELECT * FROM default.diamonds_1_csv")
# 将Spark DataFrame转换为Pandas DataFrame
pandas_df = table_df.toPandas()
# 显示Pandas DataFrame的头部
pandas_df.head()
它应该打印出表的头部:
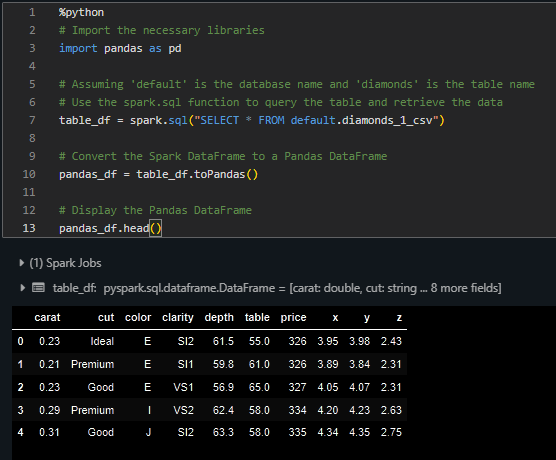
这段文字的中文翻译如下:
现在,您可以使用SQL和Pandas在表格上执行任何典型的数据分析任务。
结论和进一步步骤
我们已经成功地使用我们的基本版Databricks社区账户学习和实践了很多内容。要继续学习这个平台,第一步是使用Databricks提供的为高级账户提供的两周免费试用期。
然后,您可以充分享受DataCamp提供的Introduction to Databricks课程的学习。除了设置账户外,您还将学习和实践使用DataCamp的以下核心功能:
- 管理Databricks工作区
- 读写外部数据库
- 数据转换
- 数据编排,也称为作业调度
- Databricks SQL的全面概述
- 使用Lakehouse AI进行大规模机器学习。