你可能听说过或者甚至使用过关系型数据库。行-表格格式是存储信息最流行和直观的结构。但不幸的是,你不能将所有数据都以行和表格的形式存储。事实上,现实世界中有很多问题需要非关系型数据库来解决。那么,有没有替代方案呢?答案是肯定的!有四种类型的数据库没有任何行或表。它们被称为NoSQL数据库,因为您不能使用SQL查询它们。它们包括:
- 键值数据库
- 文档数据库
- 列族数据库
- 图数据库
本文重点介绍文档数据库以及如何使用名为MongoDB的服务器与其一起工作。但在我们深入技术细节之前,让我们先看一下文档数据库的用例。您可以查看我们关于图数据库的单独指南,以获取更多相关信息。
何时使用文档数据库?
选择文档数据库的主要用例之一是当您有数据无法整齐地适应预定义的模式(如表格)时。许多行业中的流程或应用程序存储这些类型的数据。以下是一些示例:
- Web and mobile apps: 用户配置文件、偏好设置、内容和互动
- 内容管理系统: 存储更广泛的媒体,如文本、图片、视频、GIF等
- 电子商务平台: 产品目录、客户信息、订单历史、库存等
- 游戏: 存储玩家配置文件、排行榜排名
- 日志和数据收集: 大量的日志、事件和指标用于分析等
花点时间思考一下从这些行业收集的数据如何适应表格。例如,电子商务平台在将产品目录存储到预定义的模式中可能会遇到困难。不同的产品具有不同的属性,甚至更糟糕的是,属性的数量也不同。你是需要10列来存储100个不同品牌的无人机的10个物理属性,还是只需要5-6列来存储图书信息?
基于表的数据库无法在这种情况下帮助您。通过使用诸如MongoDB之类的文档数据库,您可以获得以下好处:
- 无需预先开发成本来设计模式
- 文档(数据)可以随时间变化(包括数据类型、属性数量等)
- 文档数据库避免了连接操作,从而实现更快的查询
- 对开发人员来说直观易懂,因为文档数据库主要是大型JSON文件,基本上就是Pythonista们的巨大字典。
- 文档数据库可以水平扩展,这意味着随着数据库的增长,它们不需要越来越多的计算资源。
现在,让我们来看看关于文档数据库和MongoDB的核心概念。
MongoDB的核心概念
到目前为止,我一直在说文档数据库,但它们实际上是什么?以下是主要的概念:
- 文档:数据存储在称为文档的对象中。简单来说,文档类似于JSON的键值对象。一个文档相当于表中的一行。如果你是Python程序员,你可以将文档看作是一个字典,这样就可以了。只要记住,文档可以有嵌套文档,这是文档数据库的主要特点之一。
- 集合:集合类似于关系数据库中的表,但不是包含行,而是包含,你猜对了,文档。集合是庞大的数据结构,可能包含数千或数百万个字典。
- 无模式:这里就变得有趣了。一个集合可以包含大小不同的文档。例如,文档1可以有10个键值对,而文档2可以有15个(只要信息属于相同的类别/主题,如集合中的产品,才能有意义)。
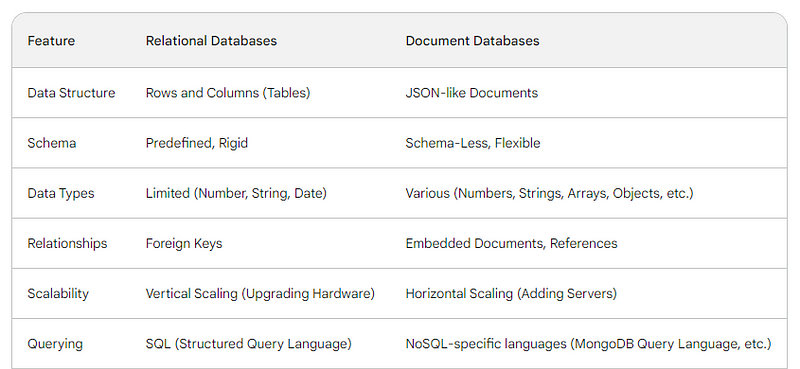
下面是一张总结关系数据库和文档数据库之间差异的表格:
这段文字的中文翻译如下:
让我们实际开始使用文档数据库。
MongoDB设置:连接到数据源
要查询文档数据库,我们需要安装MongoDB服务器。以下是特定于平台的说明:
- 对于Windows系统,请按照链接上的说明进行操作。
- 对于类Unix系统,您可以通过终端安装MongoDB:
$ sudo apt-get install -y mongodb
然后,在虚拟环境中安装pymongo和requests库。 pymongo是MongoDB服务器的官方Python适配器。我们将需要requests库来从API中获取数据。
$ pip install pymongo
$ pip install requests
然后,从终端使用以下命令启动MongoDB服务器:
$ sudo service mongodb start
现在,我们已经准备好将一些数据加载到文档数据库中了。在这样做时,有两种情况:
- 您在本地有一些适当格式的数据,如JSON、BSON、YAML或XML。
- 您需要从外部来源(通常是API)获取数据。
我们将涵盖这两个方面。首先,让我们从本地加载一个名为drone_races.json的集合。以下是执行此操作的代码片段:
import json
from pymongo import MongoClient
# 建立与MongoDB的连接
client = MongoClient("localhost", 27017)
# 创建名为"drones"的数据库
drones = client["drones"]
# 创建名为"races"的集合
races = drones["races"]
# 将数据集加载到MongoDB中
with open("data/drone_races.json", "r") as file:
data = json.load(file)
races.insert_many(data)
> 专业提示:在DataCamp Workspace中使用“解释代码”按钮,以逐行解释代码。
对我们来说,最重要的两个对象是 drones(一个数据库)和 races(一个集合)。大部分的函数和方法都与集合相关。数据库对象主要用于管理集合。
现在,让我们看看如何使用API加载相同的数据。我已经将信息存储为一个API,使用了一个叫做Mockaroo的服务。以下是代码片段:
import requests
from pymongo import MongoClient
# 从API获取数据
api_url = (
“https://my.api.mockaroo.com/drone_race_matches.json?key=6f5a6b50”
)
response = requests.get(api_url)
if response.status_code == 200:
data = response.json() # 从API获取JSON数据
# 建立与MongoDB的连接
client = MongoClient()
# 访问或创建特定的数据库
drones = client[“drones”]
# 访问或创建数据库中的特定集合
races = drones[“races”]
# 将获取的数据插入MongoDB集合中
races.insert_many(data)
else:
print(“无法从API获取数据。”)
我们已经将一些数据加载到了”drones”文档数据库的”races”集合中,或者说我们是这样做的吗?让我们通过使用查询来检查一下!
MongoDB基础查询
在MongoDB中计算文档数量
要确定集合中是否存在数据,我们需要计算文档的数量。我们将使用count_documents方法来实现:
>>> races.count_documents({})
9040
注意传递给count_documents的空字典。在MongoDB中,该字典被称为过滤器。在本教程中,我们将学习如何填充字典以创建不同类型的过滤器。现在,我们没有过滤器。上面的代码与SQL中的SELECT COUNT(*) FROM table_name相同。
我们有9040个文档 – 哎呀!现在,让我们来看一些数据。
从MongoDB中提取一个文档
使用pymongo查看一个文档,我们可以使用find_one方法:
from pprint import pprint
>>> pprint(races.find_one())
{'_id': ObjectId('659d31e9255ec0cf4bab529d'),
'laps': 3,
'league': 'F1 Drones',
'location': {'city': 'Ford',
'country': 'United Kingdom',
'date': 'error: invalid date "2024-10-25"',
'venue': 'Manhattan Seas'},
'name': 'Honorable',
'pilots': {'drone': 'DJI3-old',
'finishing_position': 66,
'name': 'Kariotta Cow',
'qualification_time': 27.39,
'team': 'Sky Crusaders',
'telemetry': {'altitude': 34.3,
'battery_voltage': 12.1,
'speed': 68.3,
'timestamp': 'error: invalid date '
'"2024-10-25T14:09:26Z"'}},
'sponsors': ['Fat Shark', 'DJI', 'Etisalat'],
'weather_conditions': 'snowy'}
请注意此文档的字段(键)。它存储有关单个无人机比赛的信息,包括以下信息:
- 圈数
- 比赛时的天气条件
- 比赛期间的飞行员(不是所有的飞行员)
- 比赛赞助商等等。
该文档还有一个必需的_id字段,它是一个唯一的哈希值。
在MongoDB中选择所有文档
count_documents总是返回一个数字,但有时候我们想查看查询匹配的数据。为了做到这一点,我们可以使用find_one的大哥,即find:
from pprint import pprint
for race in races.find():
pprint(race)
break
{'_id': ObjectId('659d31e9255ec0cf4bab529d'),
'laps': 3,
'league': 'F1 Drones',
'location': {'city': 'Ford',
'country': 'United Kingdom',
'date': 'error: invalid date "2024-10-25"',
'venue': 'Manhattan Seas'},
'name': 'Honorable',
'pilots': {'drone': 'DJI3-old',
'finishing_position': 66,
'name': 'Kariotta Cow',
'qualification_time': 27.39,
'team': 'Sky Crusaders',
'telemetry': {'altitude': 34.3,
'battery_voltage': 12.1,
'speed': 68.3,
'timestamp': 'error: invalid date '
'"2024-10-25T14:09:26Z"'}},
'sponsors': ['Fat Shark', 'DJI', 'Etisalat'],
'weather_conditions': 'snowy'}
find使用空查询(无参数)逐个返回文档,但这不是我们想要的!我们想要执行查询以便能够回答有关数据的有趣问题。这就是过滤文档将会派上用场的地方。
在MongoDB中基于条件进行选择
让我们从最简单的过滤器开始 – 匹配某个字段等于某个值的文档。这与以下代码相同:
SELECT *
FROM table_name
WHERE field = value
让我们在MongoDB中来做:
上面的代码是选择以Fat Shark作为赞助商的比赛。语法很简单,只是一个将”sponsors”字段映射到”Fat Shark”的字典。
如果MongoDB查询语言没有一些常见的不等式运算符,那它就不会是一种语言。下面是如何使用“小于”运算符:
criteria = {"pilots.qualification_time": {"$lt": 10}}
quick_races = races.count_documents(criteria)
quick_races
3061
上述查询介绍了MongoDB查询语言(MQL)的四个新特性:
- 您可以使用点表示法访问子字段。
pilots.qualification_time提取了 pilots 字段中嵌套的资格时间。 - MQL 中几乎所有的运算符都以美元符号开头。
- 运算符在嵌套文档中使用,就像上面的例子。
$lt是“小于”运算符。
因此,此查询的结果告诉我们,有 3061 次比赛中有一名飞行员的资格时间少于 10 秒。这个查询是通过 $lt 运算符实现的。以下是它的兄弟姐妹:
$lte: 小于等于$gt: 大于$gte: 大于等于
它们的语法与$lt相同。
在MongoDB中使用逻辑条件运算符进行选择
MQL还包括逻辑条件运算符,如$and和$or。让我们从后者开始。
我们将检索以英国为地点或以Etisalat为赞助商的比赛:
criteria = {
"$or": [
{"location.country": "United Kingdom"},
{"sponsors": "Etisalat"},
]
}
>>> races.count_documents(criteria)
6223
再次,点击Explain code按钮以获取详细解释。
有6223个文档符合我们的条件。要对同一字段的多个值使用“或”逻辑,我们可以使用$in运算符。
例如,我们可以通过以下方式检查恶劣天气条件:
criteria = {
"weather_conditions": {"$in": ["rainy", "snowy", "cloudy"]}
}
>>> races.count_documents(criteria)
5508
使用$or运算符编写这个查询将会很麻烦。现在,我们来看看$and。
这次,我们想要找到以澳大利亚为地点并且以Fat Shark为赞助商的比赛。下面是我们可以使用$and来实现的方法:
criteria = {
"$and": [
{"location.country": "Australia"},
{"sponsors": "Fat Shark"},
]
}
>>> races.count_documents(criteria)
193
但在实际应用中,你很少会使用$and,因为它可以用更简单的方式实现:
criteria = {
"location.country": "Australia",
"sponsors": "Fat Shark",
}
races.count_documents(criteria)
193
只需向筛选文档添加更多键值对即可实现AND逻辑运算符。
最后,还有一个$nin运算符,用于检查非成员。例如,我们可以返回所有不在美国、英国或澳大利亚举行的比赛:
criteria = {
"location.country": {
"$nin": ["美国", "英国", "澳大利亚"]
}
}
>>> races.count_documents(criteria)
126
这样只剩下阿拉伯联合酋长国作为国家,所以上述查询实际上可以写成:
criteria = {"location.country": "United Arab Emirates"}
>>> races.count_documents(criteria)
126
但是,你明白了。
在MongoDB中查询null或缺失值
在所有数据分析任务中,检查null或缺失值是一项通用操作。因此,在MongoDB中有一个操作符$exists用于此目的。以下是两个示例,用于检查特定字段是否存在:
criteria = {"location.district": {"$exists": True}}
>>> races.count_documents(criteria)
0
嗯,看起来在任何文档中都不存在district字段。但是laps字段 – 这个字段必须在所有文档中存在,因为它是关于比赛的一个重要信息。
criteria = {"laps": {"$exists": True}}
races.count_documents(criteria)
9040
正如预期的那样,所有文档都有laps字段。但是那些存在但值为null的字段呢?我们也可以检查一下:
criteria = {"pilots.finishing_position": None}
races.count_documents(criteria)
0
通过在Python中使用内置的None对象,我们可以检查任何字段的值是否缺失。
有一些高级场景需要进行空值或存在性检查。例如,您可能希望检查某些庞大嵌套数组的特定元素是否存在。
要做到这一点,我们可以在MQL中使用数组索引语法。例如,要找到只有一个赞助商的比赛,我们需要检查sponsors数组的第二个元素是否存在:
# 计数从0开始,一如既往
criteria = {"sponsors.1": {"$exists": False}}
races.count_documents(criteria)
2929
只需将元素的索引号附加到键上即可。因此,在我们的集合中,近3000场比赛只有一个赞助商。
这种数组索引语法不仅适用于$exists,还适用于许多其他运算符。
投影(限制字段)
在本教程中,我们要介绍的最后一件事是投影。到目前为止,我们的查询结果包含每个文档中的每个字段。当您的文档有数百个字段时,这并不理想。想象一下打印它们时的眼花缭乱!
因此,要选择我们想要返回的字段,我们可以使用投影。以下是方法:
criteria = {"pilots.telemetry.speed": {"$gte": 20}}
projection = {
"sponsors": 1,
"location.country": 1,
"pilots.telemetry.speed": 1,
"pilots.name": 1,
}
fast_pilots = races.find(criteria, projection)
for pilot in fast_pilots:
pprint(pilot)
break
在上述情况下,我们像往常一样编写过滤条件,但这次我们定义了另一个文档,其中四个字段设置为1。如果我们将这个projection文档作为第二个参数传递给find或count_documents,我们将只在输出中得到设置为1的字段。
{'_id': ObjectId('659d31e9255ec0cf4bab529d'),
'location': {'country': 'United Kingdom'},
'pilots': {'name': 'Kariotta Cow', 'telemetry': {'speed': 68.3}},
'sponsors': ['Fat Shark', 'DJI', 'Etisalat']}
尽管我们只选择了四个字段,但是讨厌的_id字段还是以某种方式被压缩了进去。为了抑制这种行为,在projection字典中将其设置为0:
criteria = {"pilots.telemetry.speed": {"$gte": 20}}
projection = {
"sponsors": 1,
"location.country": 1,
"pilots.telemetry.speed": 1,
"pilots.name": 1,
"_id": 0,
}
fast_pilots = races.find(criteria, projection)
for pilot in fast_pilots:
pprint(pilot)
break
{'location': {'country': 'United Kingdom'},
'pilots': {'name': 'Kariotta Cow', 'telemetry': {'speed': 68.3}},
'sponsors': ['Fat Shark', 'DJI', 'Etisalat']}
现在,这看起来更漂亮了。
最后,要返回除了几个字段之外的所有字段,我们可以将它们的字段设置为0:
projection = {"_id": 0, "league": 0, "pilots": 0}
# 这次为空的查询条件
races.find_one({}, projection)
{'name': 'Honorable',
'location': {'venue': '曼哈顿海',
'city': '福特',
'country': '英国',
'date': '错误:无效日期 "2024-10-25"'},
'sponsors': ['Fat Shark', 'DJI', 'Etisalat'],
'laps': 3,
'weather_conditions': '下雪'}
正如你所看到的,这次我们有所有字段,除了_id、league和pilots。
结论
这个教程并不能完全展示MongoDB作为数据库管理工具的庞大规模。今天,我们只涵盖了GET查询(用于检索信息的查询),但MongoDB还允许数据专家在文档数据库中插入、更新或删除信息。我们还省略了一整类查询 – 聚合查询。
所有这些主题超出了本文的范围,需要额外的资源来学习它们。为什么不去看看这些:
- 使用Python进行数据科学中的MongoDB入门课程 – 一门全面的课程,还涵盖了聚合等高级查询
- Python中的MongoDB入门 – 另一门涵盖了pymongo的CRUD(创建、读取、更新和删除)操作的MongoDB教程。
- NoSQL概念课程 – 如果您对NoSQL数据库感兴趣,这门课程适合您。除了文档数据库,它还涵盖了其他非关系型数据库。