‘
什么是dbt,为什么它很重要?
在过去的几年里,数据科学界逐渐接受了以数据为中心的范式。我们终于开始更加关注数据质量,而不是越来越复杂的机器学习模型。这导致了数据工程师的巨大流行。他们现在获得的薪水仅限于熟练的数据科学家或机器学习工程师。
‘
而一个显著改善数据工程师生活的工具是dbt(数据构建工具)。它的目的是将经过实战验证的软件工程最佳实践引入数据工程,并尽快轻松地产生数据价值。
这篇文章将介绍dbt的基础知识,适用于初级数据工程师,希望为他们的工具库增添一项不可或缺的工具。您还可以查看我们的dbt入门课程,了解更多关于这个强大工具的信息。
前提条件
本文仅需几个前提条件:
- 基础到中级的SQL:如果你知道如何使用WHERE和GROUP BY子句,那就没问题。
- 熟悉终端:对终端、虚拟环境和使用pip或homebrew等软件包管理器安装软件都要有一定的了解。
- 数据仓库基础知识:对数据工程的基本知识有很大的帮助。不一定要像了解Kimball的四步骤那样深入,但要足够理解一些关键术语。
如果你无法满足这些条件,但你的老板(或你自己)仍然要求你学习dbt,你可以使用以下资源:
这个dbt指南将涵盖什么内容?
开源社区喜欢dbt,所以他们设法将其与几乎所有与数据相关的工具集成在一起。结果呢?文档如此庞大,以至于即使是快速入门指南也比整个Python库的文档还要大。
所以,我在这篇文章中的目标是以适度的技术性介绍dbt的七个核心概念。完成教程后,你可以去dbt文档的任何页面,弄清楚正在发生的事情。
现在,让我们直接开始吧!
0. 数据仓库
第一个概念是数据仓库。仓库是存储属于某个公司的所有数据的地方。
公司建立仓库是因为它们可以进行分析和其他与数据相关的操作(咳咳,结构化数据)。它们将历史数据组织成表格,并且结构化以便进行快速查询和分析。
有许多工具可以实现数据仓库:
- PostgreSQL
- MySQL
- Snowflake
- BigQuery
- Redshift
等等。
dbt无法帮助您收集或加载数据到上述工具中,但可以在其中转换数据。换句话说,它执行ETL/ELT过程(提取、转换、加载)中的转换部分,这是所有数据仓库的核心。
1. dbt Core vs. dbt Cloud
dbt通过两个界面提供: dbt Core 和 dbt Cloud。
dbt Core是一个开源库,实现了大部分dbt的功能。它有一个命令行界面(你会喜欢上的dbt命令),你可以用它来管理项目中的数据转换。
dbt Cloud是一个面向团队的企业解决方案。除了CLI之外,dbt Cloud还提供了一个更用户友好的基于Web的IDE。通过它,您不必过多担心数据库连接和编辑YAML文件(正如您将在接下来的部分中看到的那样)。
dbt Cloud还提供了诸如作业调度、高级集成和高优先级支持等其他功能。
这是一个总结了dbt Core和dbt Cloud之间差异的表格:
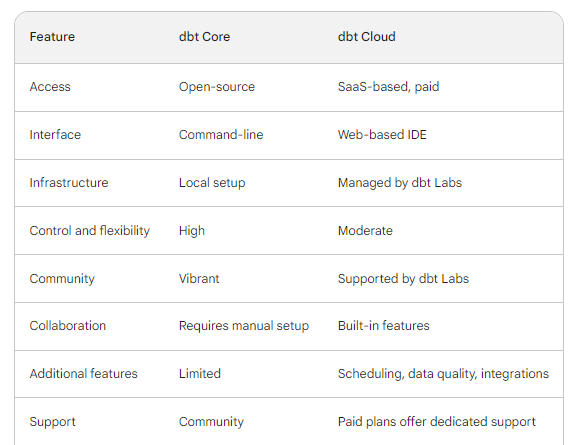
这段文字的中文翻译如下:尽管有额外的功能,我们将介绍dbt Core,因为它最适合本地项目、测试和学习。您可以在任何操作系统上使用pip进行安装(当然要在虚拟环境中)。
我将使用Conda环境:
$ conda create -n learn_dbt -y
$ pip install dbt-<adapter_name>
你应该将adapter_name替换为你想使用的数据库。dbt Labs(dbt背后的公司)已经集成了许多不同数据平台的适配器。
在本文中,我们将使用dbt-duckdb适配器连接到DuckDB数据库。但是您可以使用在dbt文档的此页面上列出的任何适配器。
$ pip install dbt-duckdb
这就是初始设置的全部内容!
2. dbt 项目
基本上,dbt 项目是您计算机上的一个目录,其中包含执行数据转换所需的所有内容。它包含许多 .sql 文件(称为模型)和 YAML 文件(用于配置)。
要创建一个dbt项目,您可以在CLI上使用dbt init <project_name>命令:
$ dbt init dbt_learn终端会要求您输入与您可用的数据平台适配器相对应的代码。由于您只有DuckDB,您可以按1键。
$ cd dbt_learn
在 dbt_learn 文件夹中,你有以下结构:
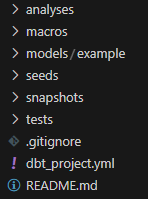
这段文字的中文翻译如下:
这就是数据工程师变成软件工程师的地方,因为dbt项目可以让你:
- 有组织和模块化:将数据转换组织和分离成可管理的单元,使您的代码更易于理解和维护。
- 版本控制:跟踪更改并恢复到模型的先前版本,确保数据的一致性和可重复性。
- 协作:添加多个用户,他们可以在同一个项目上以定义的角色和权限进行工作。
- 可测试:为您的模型编写测试,以确保它们按预期工作,并在部署到生产环境之前识别潜在问题。
- 可重复:在不同的数据源和环境中使用相同的项目进行一致的数据转换。
简而言之,dbt项目提供了一种强大的方式来管理和编排数据转换。它们将软件工程的期望益处带到了数据世界。
3. dbt项目配置文件
我们已经初始化了一个dbt项目,现在我们需要连接到一个现有的数据库(或者从头开始创建一个)。为了做到这一点,我们需要一种安全的方式将数据库凭据传递给dbt以建立连接。这就是我们将使用一个项目配置文件的地方。
项目配置文件是一个包含所选数据平台连接详细信息的YAML文件。该文件本身位于$HOME目录下的.dbt目录中,命名为profiles.yml。以下是当前的配置文件示例:

这段文字的中文翻译如下:
该文件列出了我们项目中名为dbt_learn的单个配置文件。它指定了两个输出:dev和prod。
Outputs是指定与数据仓库或数据库建立不同连接的个别配置。通过outputs,您可以管理与不同环境的连接:
- 开发
- 测试
- 生产等等。
在我们的配置文件中,默认的输出是dev,它在target字段中列出。您可以根据需要将其更改为任何其他输出。目前,我们将其保留为原样。
注意:只要在其他dbt文件中正确引用,您可以更改配置文件和输出名称。
path 字段指定了一个名为 dev.duckdb 的现有数据库的位置。如果该数据库不存在,dbt DuckDB 适配器将在我们的工作目录中(在 dbt_learn 项目内;path 字段指定了相对于项目目录的路径)创建它。由于我们没有一个名为 dev.duckdb 的数据库,我们将通过运行 dbt debug 让 dbt 来创建它。
$ dbt debug
`debug`子命令用于测试项目的许多方面,例如:
profiles.yml文件中的错误profiles.yml中的数据库连接详细信息- 数据库适配器
dbt_project.yml文件中的错误等等。
如果您收到了一个绿色的“所有测试通过”的消息,并且出现了一个新的dev.duckdb数据库,那么您可以继续进行。
4. dbt 模型
模型是 dbt 的核心,它们代表了 dbt 所著名的实际转换。
数据模型是表示一组数据的结构和关系的概念性想法。在dbt中,数据模型更简单、更具体。它们具有以下属性:
- 表示数据转换(如执行清理操作)
- 通常使用
.sql文件中的SQL编写(在较新版本的dbt中允许使用Python) - 通常由一个SELECT查询组成
我们的dbt_learn项目预先填充了两个虚拟模型,位于models/example中:
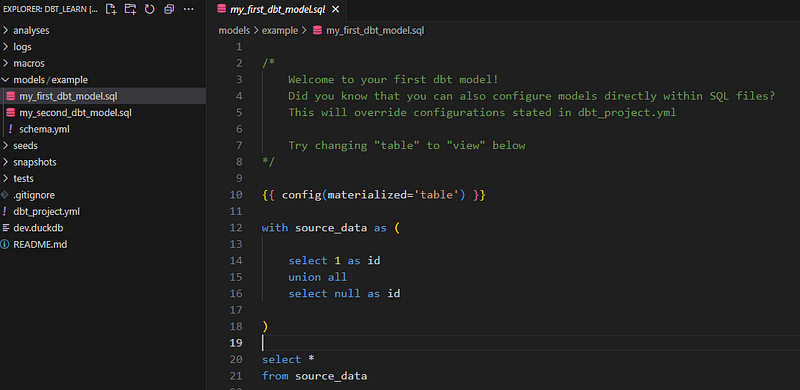
这段文字的中文翻译如下:
我们将删除它们并创建我们自己的:
$ rm -rf models/example
$ mkdir models/stats
$ touch models/stats/average_diamond_price_per_group.sql
在上面代码片段的最后一行,我们正在创建一个名为average_diamond_price_per_group的模型,放在stats目录中。在模型名称中保持描述性非常重要。
在模型(.sql文件)中,粘贴以下虚拟测试SQL查询:
SELECT 1 AS Id
并使用dbt run运行模型:
$ dbt run
你应该会收到一个绿色的“成功完成”消息。
在一切都设置好之后,我们可以将一些数据加载到我们的dev.duckdb数据库中。我们将使用parquet文件来实现,因为DuckDB原生支持它们。
SELECT AVG(price), cut
FROM "diamonds.parquet"
GROUP BY cut
查询应返回相同的成功消息。
对于这个教程,我已经准备好了钻石数据集作为一个parquet文件。在这个GitHub gist中,你可以找到下载到你的工作空间的代码片段。我们刚刚看到了如何通过使用返回有关数据集的一些摘要统计信息的SELECT语句来创建我们的第一个dbt模型。在实践中,您的模型将取决于您的业务需求以及不同员工如何使用您的数据库。因此,我们不会重点关注dbt模型的实际逻辑,而是关注如何正确实现它们。
5. 在dbt中的DAGs
在一个真实的项目中,你的模型很可能会相互依赖,形成某种层次结构。在数据世界中,这种层次结构被称为有向无环图(DAG)或血统图。
一个DAG可以完成1000字的文档工作。看看这个来自dbt DAGs页面的例子:
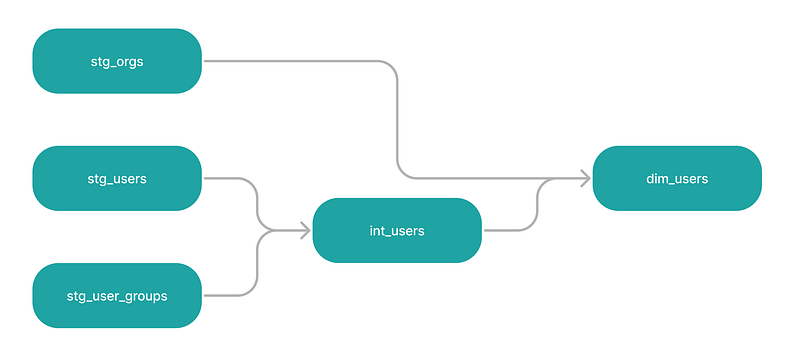
这段文字的中文翻译如下:在这个图中有四个模型,所有模型都与下游模型线性连接。 stg_users 和 stg_user_groups 是 int_users 的父模型,而 int_users 又与 dim_users 和 stg_orgs 模型上游一起是 dim_users 的父模型。
注意:单词upstream和downstream经常用来指代DAG中每个模型的相对位置。
DAGs的一个关键方面是没有闭环。这意味着下游模型(即早期模型的结果)不能与上游模型连接。这就是”acyclic”一词的含义。
除了DAG的视觉丰富性外,它们的目的是根据它们的依赖关系让dbt构建/更新模型。如果我们不为上述四个模型定义DAG,dbt将按字母顺序构建它们。这将导致各种红色消息和错误。
在dbt中定义DAG,我们将使用Jinja模板。
6. 在dbt中使用Jinja模板
在上述的DAG中,int_users模型是stg_users和stg_user_groups的产物。我们需要在项目中指定这种关系,否则dbt run会按照字母顺序执行所有模型,这意味着int_users会先执行。这将导致错误,因为它的依赖关系尚未实现。
现在,int_users模型可能是这样的:
SELECT some_column
FROM stg_users as su
JOIN stg_user_groups as sug
ON su.a = sug.a
现在,我们将使用Jinja将这三个模型链接成一个DAG的节点:
SELECT some_column
FROM {{ ref("stg_users") }} as su
JOIN {{ ref("stg_user_groups" )}} as sug
ON su.a = sug.a
不直接写入模型名称,而是将它们放在一个名为ref的Jinja函数中。语法是{{ ref("column_name") }}(注意空格和引号)。当我们的查询被编译时,Jinja函数会被实际的模型名称替换。
请注意,stg_users和stg_user_groups应该作为.sql文件存在于您的dbt项目中。
现在,当我们执行dbt run时,它会查找每个模型的依赖关系,连接它们并相应地执行它们。
Jinja中的ref函数并不是我们在dbt中唯一可以使用的函数。实际上,通过使用Jinja的其他函数和特性,您可以显著扩展SQL语句的功能。以下是一些示例:
- 使用Jinja在模型文件中创建变量:
{% set status = 'active' %} -- 定义一个变量
SELECT *
FROM customers
WHERE status = {{ status }};
- 使用config对象在模型配置文件中定义变量。
如果我们有一个models/model_properties.yml文件,并且它具有以下字段:
# models/model_properties.yml
version: 2
models:
- name: my_model
config:
target_schema: analytics
我们可以在任何.sql文件中使用Jinja访问其字段:
{% set target_schema = config.target_schema %}
CREATE TABLE {{ target_schema }}.{{ target_table }} AS
...
- 使用条件和循环(这真是个惊喜!):
条件:
{% if some_condition %}
SELECT * FROM test_data
{% else %}
SELECT * FROM production_data
{% endif %}
循环:
SELECT
order_id,
{% for payment_method in ["bank_transfer", "credit_card", "gift_card"] %}
SUM(CASE WHEN payment_method = '{{ payment_method }}' THEN amount END) AS {{ payment_method }}_amount,
{% endfor %}
SUM(amount) AS total_amount
FROM {{ ref('raw_payments') }}
GROUP BY 1;
- 通过Jinja在SQL中创建函数(宏)(不,我不是在开玩笑):
这是宏:
{% macro create_table(table_name, columns) %}
CREATE TABLE {{ table_name }} (
{% for column in columns %}
{{ column.name }} {{ column.type }},
{% endfor %}
);
{% endmacro %}
以下是如何在模型中使用它:
{% call create_table('my_customer_table', [
{'name': 'id', 'type': 'integer'},
{'name': 'name', 'type': 'varchar(255)'},
{'name': 'email', 'type': 'varchar(255)'},
]) %}
INSERT INTO {{ my_customer_table }} (id, name, email)
SELECT customer_id, customer_name, customer_email
FROM raw_customers;
如果你想了解更多关于在dbt中使用Jinja和SQL的内容,请查看dbt文档的这个页面。
7. dbt 测试
现在,一个优秀的软件开发人员知道他们需要不断地测试代码以查找错误和漏洞。由于 dbt 将数据工程师转变为软件开发人员,它为他们提供了一个简单的工作流程来使用内置和自定义的测试。
目前,dbt提供以下四个内置测试:
unique– 验证所有值都是唯一的not_null– 检查是否缺失accepted_values– 验证所有值是否在指定列表内,有一个values参数relationships– 验证与特定表或列的连接,有to和field参数
要指定在哪些列上使用哪些测试,我们使用一个名为model_properties.yml的YAML文件,放在models目录中。
注意:model_properties.yml不是模型运行的必需文件,它可以被命名为任何名称。但是,如果您想通过测试来验证数据输入模型,那么这个文件是必须的。
让我们看看如何使用not_null测试来检查钻石表中cut列中的缺失值。首先,在models文件夹中创建一个model_properties.yml文件:
$ touch models/model_properties.yml
在其中,粘贴以下内容:
version: 2
models:
- name: average_diamond_price_per_group
columns:
- name: cut
tests:
- not_null
在models下的- name字段中,我们指定了我们正在定义属性的模型。然后,我们指定列及其名称。最后,我们在tests字段下编写not_null测试。
现在,您可以在运行dbt run之前使用此测试来进行数据验证。命令是dbt test:
$ dbt test
如果收到错误消息,意味着测试失败,您需要检查表中的问题,并在必要时进行修复。
要在dbt中实现自定义测试,甚至更好的是实现可重用的自定义测试,请查看DataCamp上的Introduction to dbt课程中的这一章节。
一个你可以遵循的典型的dbt工作流程
为了在你的项目中成功使用dbt,你可以使用以下推荐的工作流程:
1. 项目初始化
- 安装
dbt并使用dbt init创建一个新项目
2. 配置
- 为您的项目选择一个数据库平台
- 在您的主目录中的
profiles.yml文件中配置数据库凭据。 - 调整项目设置:修改
dbt_project.yml以进行项目级设置(例如版本、依赖项)。
3. 开发
- 编写模型的SQL代码:在
models目录中创建.sql文件来定义模型。 - 编写模型测试:在
tests目录中创建.yml文件来定义测试。 - 增量测试:在开发过程中经常使用
dbt test运行测试。 - 调试问题:使用
dbt debug进行故障排除。
4. 本地验证(我们没有涵盖的主题)
- 构建项目:使用dbt build编译模型和测试。
- 运行全面测试:使用dbt test执行所有测试。
其他最佳实践:
- 版本控制:使用Git进行协作和版本控制(这是必须的)。
- 文档:在模型和测试中编写可读的人类注释。您可以使用
dbt docs generate在Web服务器上呈现模型的文档(是的,这是可能的)。 - 性能分析:利用dbt的性能分析能力来捕捉和修复性能瓶颈。
- 持续集成(CI):将dbt与CI/CD流水线集成,实现自动化测试和部署。
结论和进一步资源
在本教程中,我们涵盖了许多基础知识,但正如我在开始时提到的,dbt是一个功能强大的工具,具有许多功能。要掌握它并在生产环境中舒适地使用它,需要一段时间。为什么不利用这些资源帮助您更快地实现这个目标呢?