‘
数据可视化是解读复杂数据集的关键组成部分。
‘在Python编程领域中,Seaborn是一个强大的库,用于创建视觉上吸引人且信息丰富的统计图形,如直方图和线图。
Seaborn在Matplotlib的基础上进行了扩展,增强了其界面,并提供了更多用于可视化数据的选项,尤其适用于统计分析。Seaborn与Pandas DataFrames的无缝集成使其成为数据科学家和分析师的首选。
在这个详细的指南中,我们将重点介绍Seaborn中最常用的图表之一——直方图。
sns.histplot函数概述
Seaborn中的sns.histplot函数用于绘制直方图,直方图对于检查连续数据的分布非常重要。该函数非常灵活,允许进行广泛的自定义,从而更容易从数据中得出有意义的洞察。
这个函数是Seaborn库中众多可用函数之一。请查看下面的速查表,以快速了解。
这段文字的中文翻译如下:
数据科学中的Seaborn备忘单 – 来源
设置环境
导入必要的库
在进行数据可视化之前,我们需要设置环境。这包括导入必要的库,其中Seaborn是主要关注的对象。为了方便起见,通常将Seaborn导入为sns。
除了Seaborn之外,其他重要的库通常包括NumPy用于数值操作,pandas用于数据处理,以及Matplotlib用于额外的自定义选项。
这些都是在Python中创建和操作数据可视化所需的必要工具的基本库。它们是数据分析师和数据科学家最常用的库。如果你刚开始学习Python,我建议你尝试我们的Python入门课程。如果想进一步学习pandas、NumPy和Matplotlib,可以参加我们的pandas数据处理课程、NumPy入门课程和Matplotlib数据可视化入门课程。
准备数据
我们将使用波士顿房价数据集,该数据集可以从Scikit-Learn库中加载。该数据集提供了波士顿不同地区的房屋价值以及诸如犯罪率、平均房间数等多个属性。
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
拥有适合的数据是制作直方图的关键。在这个例子中,我们使用了一个连续变量,即波士顿的自住房屋的中位数价值(MEDV)。
由于直方图通常显示单个变量的分布,我们将从DataFrame中选择一列。
刚接触Scikit-Learn?可以尝试一下我们的Python机器学习教程。如果您想了解更多信息,我们的Scikit-Learn监督学习课程将帮助您掌握基础知识。
构建你的第一个Seaborn直方图
在开始之前,这里有一些构建Seaborn直方图的基本先决条件:
- 至少有一列连续数据
- 对数据集有基本的理解
- 熟悉Pandas DataFrame操作
- 对Seaborn语法和函数有基本的了解
我们将首先介绍`sns.histplot`函数的一些常见语法和参数。
语法和参数
使用`sns.histplot`创建直方图的基本语法很简单。
关键参数包括:
data:数据集,通常是一个Pandas DataFrame。x:绘制直方图的变量。color:指定条形图的颜色。alpha:条形图的透明度。bins:要使用的条形组(柱子)的数量。binwidth:每个柱子的宽度。kde:一个布尔值,用于添加核密度估计图。hue:根据另一个变量区分数据子集。
该函数接受许多参数和参数,但我们将重点关注我们数据集所需的参数。
创建一个简单的直方图
让我们创建一个基本的直方图来可视化房屋价格中位数(MEDV)的分布。
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV')
plt.title('波士顿房价中位数分布')
plt.xlabel('自住房屋的中位价值(单位:千美元)')
plt.ylabel('频率')
plt.grid(True)
plt.show()
这个命令将显示MEDV列的直方图。
这是从这段代码生成的图表:
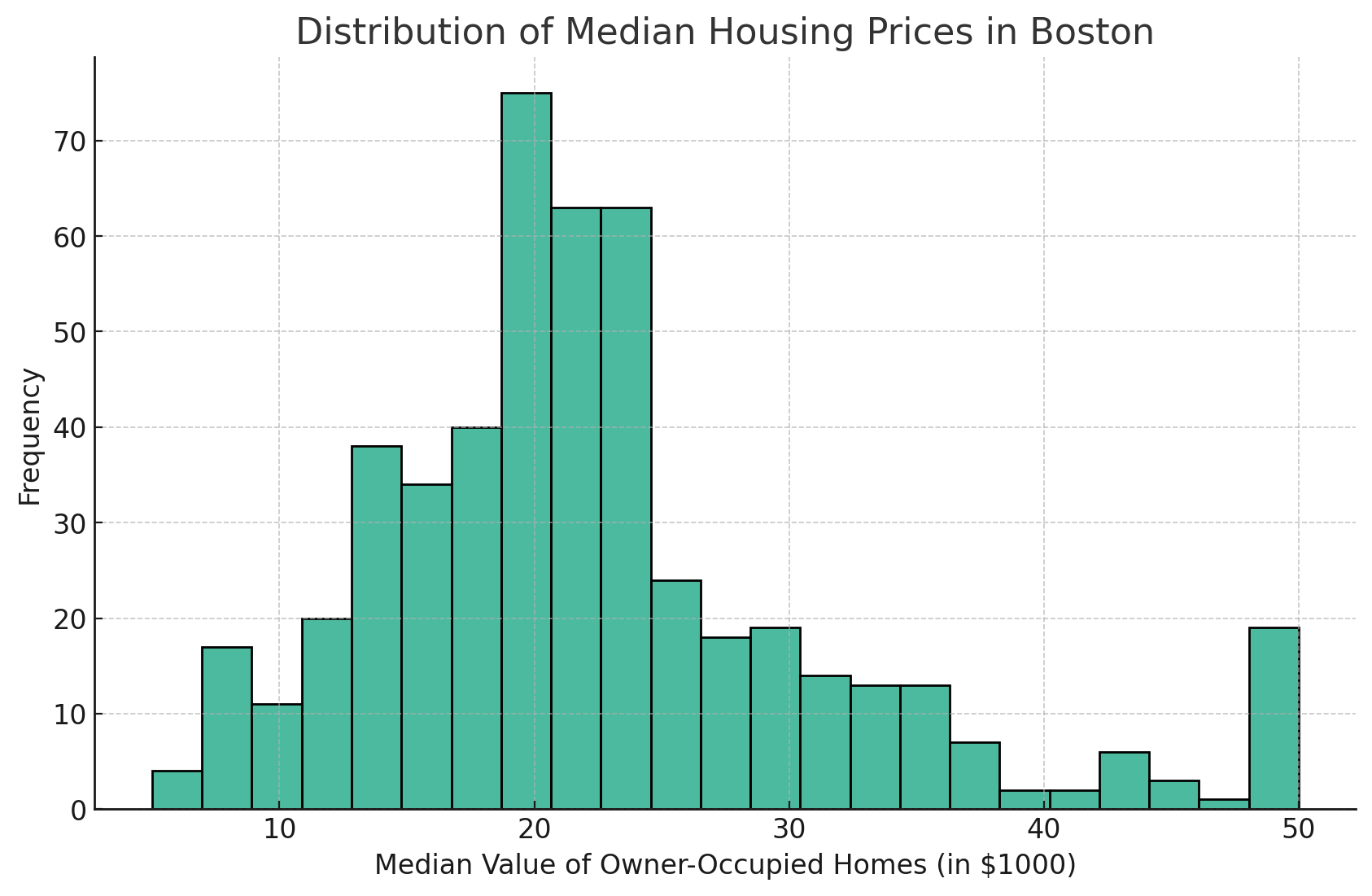
这是一个直方图,显示了波士顿数据集中房屋中位数价格(MEDV)的分布情况。直方图提供了对自住房屋中位数值的频率分布的可视化表示。
增强您的Seaborn直方图
调整箱子大小和计数
调整箱子的数量可以帮助更好地理解分布情况。更多的箱子数量可以揭示更多细节,而较少的数量则简化了可视化。
要增加箱子的数量,您可以修改bins参数。
这是一个例子:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', bins=30)
plt.title('波士顿房价中位数分布')
plt.xlabel('自住房屋的中位数价值(以千美元计)')
plt.ylabel('频率')
plt.grid(True)
plt.show()
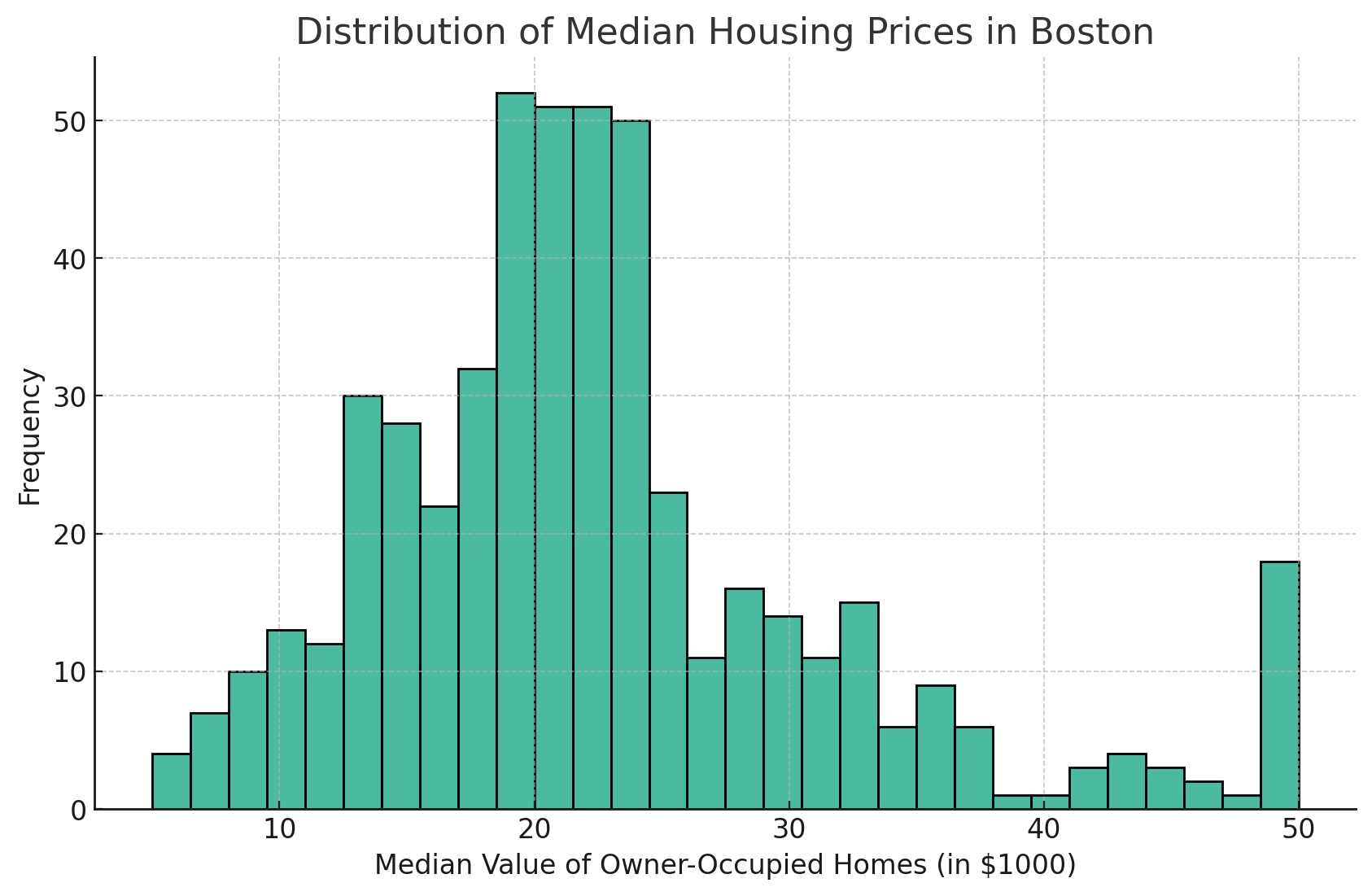
从上面的Seaborn直方图可以看出,柱状图的数量已增加到我设置的数量,这里是30个。这是一种深入了解数据细节的好方法,可以获得更精细的数据。
修改美学
自定义美学,如更改条形颜色和透明度,可以使直方图更具信息性和视觉吸引力。
在下面的示例中,我使用紫色重新创建了我们原来的直方图,而不是使用默认颜色。
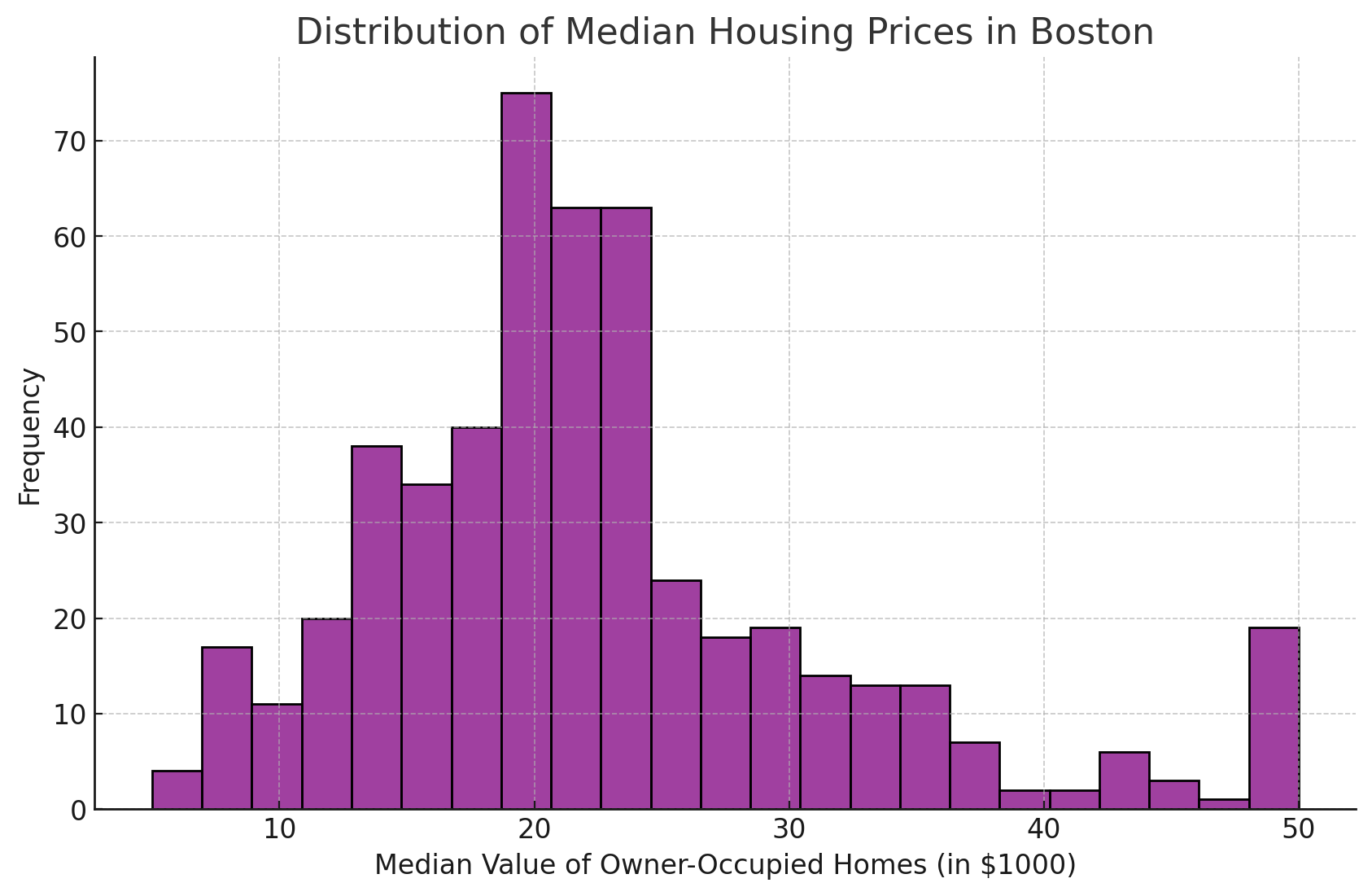
这段文字的中文翻译如下:
这是我用来创建上面图表的代码。
“`python
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x=’MEDV’, color=’purple’)
plt.title(‘波士顿房价中位数分布’)
plt.xlabel(‘自住房屋的中位价值(单位:千美元)’)
plt.ylabel(‘频率’)
plt.grid(True)
plt.show()
“`
添加核密度估计(KDE)
KDE提供了数据分布的平滑估计。它对于识别数据中的模式特别有用。
“`
这将创建一个平滑的曲线,可以帮助可视化整体趋势。
为了实现这一点,我们在这个函数中使用kde参数:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', kde=True)
plt.title('波士顿房价中位数分布')
plt.xlabel('自住房屋的中位价值(以千美元计)')
plt.ylabel('频率')
plt.grid(True)
plt.show()
这将产生一个漂亮的直方图曲线,如下所示。
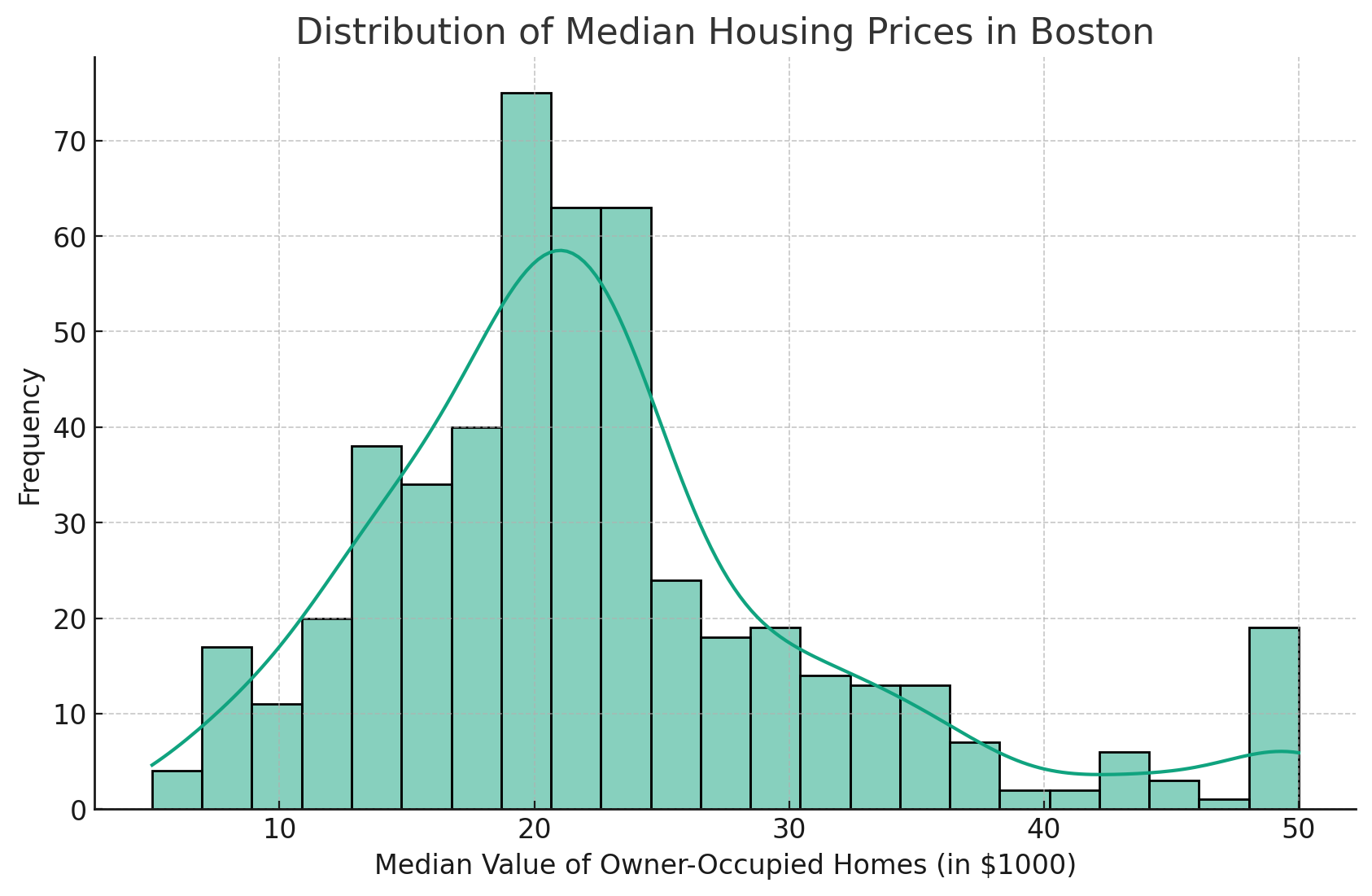
这段文字的中文翻译如下:
核密度估计(KDE)线的添加提供了对分布的更平滑的估计。
高级直方图技术
多变量直方图
色调参数允许在直方图中比较不同的类别。
该参数允许我们在同一个直方图中区分不同的类别,从而提供分布的视觉比较。
简单来说,它从DataFrame中获取一个分类列,并使用不同的颜色区分数据。
例如,如果我们的DataFrame中有一个名为’CHAS’的列,该列指示房屋是否位于查尔斯河边(1)或不是(0),我们可以使用’hue’参数来比较靠近河边和不靠近河边的房屋的中位房价分布。
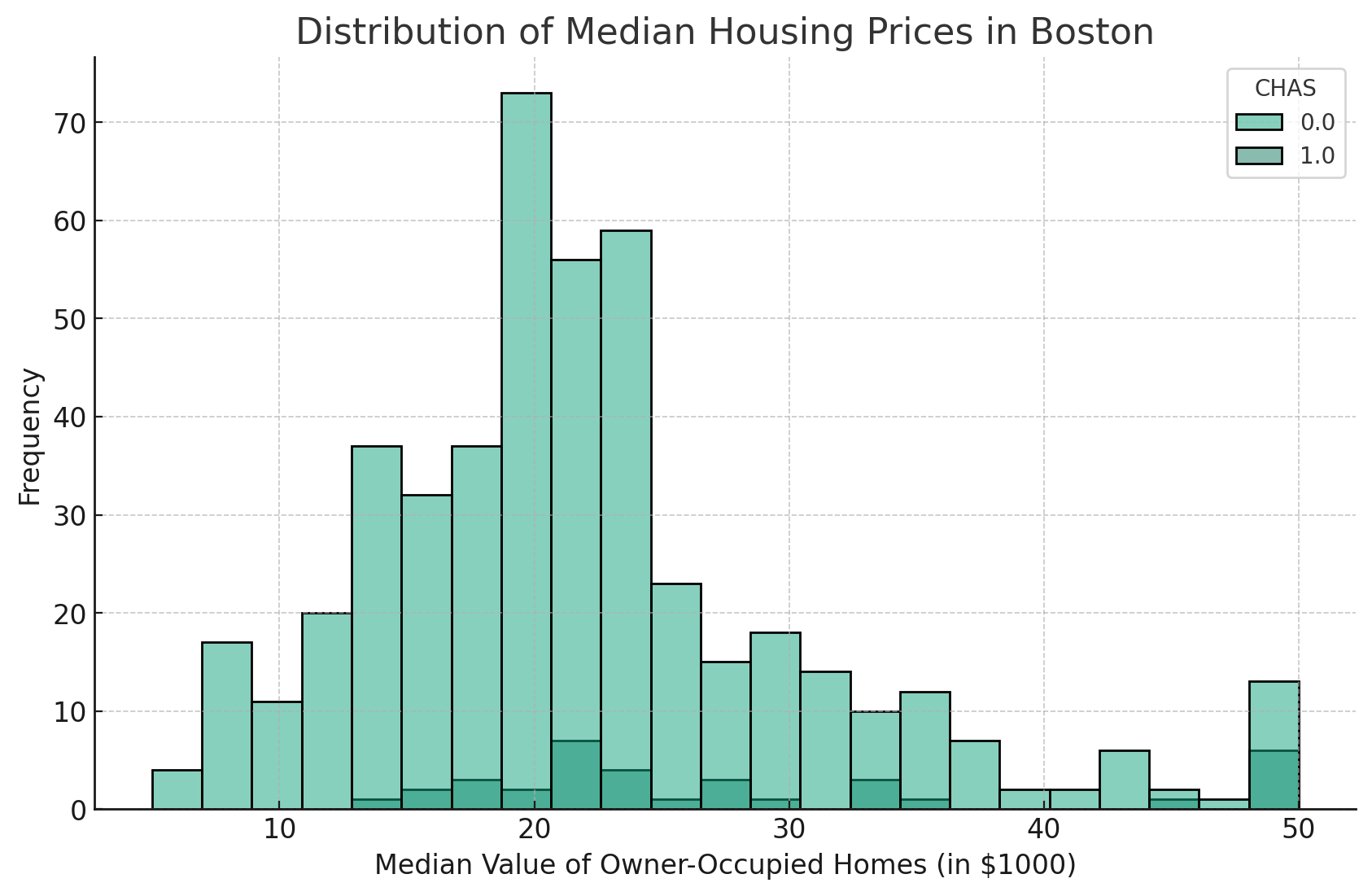
这段文字的中文翻译如下:
代码如下:
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='MEDV', hue='CHAS')
plt.title('波士顿房屋中位数价格分布')
plt.xlabel('自住房屋的中位数价值(以千美元计)')
plt.ylabel('频率')
plt.grid(True)
plt.show()
这将生成一个直方图,其中区分了沿查尔斯河(CHAS=1)的房屋的MEDV分布与不沿河的房屋(CHAS=0)的分布,每个分布用不同的颜色表示。
Seaborn直方图的最佳实践
构建Seaborn直方图时,有几个方面需要牢记,如下所述:
1. 选择合适的柱数
选择最佳的柱数对于创建一个信息丰富的直方图至关重要。虽然更多的柱数可以提供更多的细节,但也可能导致过拟合和数据的错误表达。
另一方面,过少的箱子可能会过于简化分布。
选择正确的箱子数量的一种方法是使用一个叫做斯科特规则的经验法则。这个规则根据数据集中的数据点数量来计算理想的箱子大小。
2. 平衡细节和清晰度
在直方图中提供足够的细节很重要,但确保可视化保持清晰易懂也是至关重要的。
添加过多的元素,如KDE线条或过多的颜色,可能会导致视觉混乱,难以理解。
在添加信息元素和保持简洁之间取得平衡是最好的。
3. 考虑数据类型
被可视化的数据类型也在选择适当的直方图参数时起到了作用。
例如,与分类变量相比,连续变量将需要不同的分箱大小。
在创建直方图时,考虑数据的性质非常重要,以确保它们准确地表示分布情况。
然而,Seaborn只是Python中可用的数据可视化库之一。如果你喜欢的话,你也可以考虑在Matplotlib中创建你的直方图。
最后的想法
Seaborn是一个在Python中创建可视化图表的强大库,`histplot`函数可以轻松创建直方图。只需在函数中更改参数,您就能够修改图表的外观,以达到您想要的详细程度和美观度。
请记住上面提到的所有Seaborn直方图的提示:始终考虑数据类型,选择适当的箱宽,并在使用Seaborn创建直方图时在细节和清晰度之间取得平衡。
想要了解更多关于Seaborn及其其他强大的数据可视化功能吗?我们的Seaborn数据可视化入门课程是一个非常适合初学者的课程。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”