深度学习领域正在经历一次地震般的变革,这要归功于Transformer模型的出现和快速演进。
这些开创性的架构不仅重新定义了自然语言处理(NLP)的标准,而且拓宽了它们的视野,从而革新了人工智能的许多方面。
Transformer模型以其独特的注意机制和并行处理能力而闻名,这些模型在理解和生成人类语言方面取得了前所未有的准确性和效率,成为创新飞跃的见证。
2017年首次出现在Google的“Attention is all you need”文章中,transformer架构是像ChatGPT这样的开创性模型的核心,引发了AI社区的新一波激动。它们在OpenAI的尖端语言模型中起到了重要作用,并在DeepMind的AlphaStar中发挥了关键作用。
在这个AI变革时代,对于有抱负的数据科学家和自然语言处理从业者来说,Transformer模型的重要性不言而喻。作为大多数最新技术飞跃的核心领域之一,本文旨在解密这些模型背后的秘密。
什么是Transformer?
Transformer最初是为了解决序列转换或神经机器翻译的问题而开发的,这意味着它们被设计用来解决将输入序列转换为输出序列的任何任务。这就是为什么它们被称为“Transformer”的原因。
但让我们从头开始。
什么是Transformer模型?
Transformer模型是一种神经网络,它学习顺序数据的上下文,并生成新的数据。
简单来说:
变压器是一种人工智能模型,通过分析大量文本数据中的模式来学习理解和生成类似人类的文本。
Transformer是当前最先进的自然语言处理模型,被认为是编码器-解码器架构的演进。然而,尽管编码器-解码器架构主要依赖于循环神经网络(RNN)来提取序列信息,但Transformer完全没有这种循环性。
那么,他们是如何做到的呢?
它们被专门设计用于通过分析不同元素之间的关系来理解上下文和含义,并且几乎完全依赖于一种称为注意力的数学技术来实现。

图片由作者提供。
历史背景
Transformer模型起源于Google于2017年的一篇研究论文,是机器学习领域最近和最有影响力的发展之一。第一个Transformer模型在一篇有影响力的论文《Attention is All You Need》中进行了解释。
这个开创性的概念不仅是理论上的进步,而且在TensorFlow的Tensor2Tensor包中得到了实际的应用。此外,哈佛大学的NLP小组通过提供一份带有注释的论文指南,并附带了一个PyTorch实现,为这个新兴领域做出了贡献。您可以在我们的独立教程中了解更多关于如何从头开始实现一个Transformer的内容。
他们的引入在该领域引发了一股显著的浪潮,通常被称为Transformer AI。这一革命性的模型为后来在大型语言模型领域的突破,包括BERT,奠定了基础。到2018年,这些发展已被誉为自然语言处理领域的一个分水岭时刻。
在2020年,OpenAI的研究人员宣布了GPT-3。几周内,GPT-3的多功能性迅速得到证明,人们开始使用它来创作诗歌、程序、歌曲、网站等,全球用户的想象力被深深吸引。在2021年的一篇论文中,斯坦福学者恰如其分地将这些创新称为“基础模型”,强调了它们在重塑人工智能领域中的基础性作用。他们的工作突出了转换器模型不仅革新了该领域,而且推动了人工智能可实现的前沿,预示着一个新时代的可能性。
“我们正处于一个简单方法如神经网络给我们带来新能力爆炸的时代,”谷歌前高级研究科学家、企业家Ashish Vaswani说。
从LSTM等RNN模型向Transformer模型在NLP问题中的转变
在Transformer模型引入时,处理具有特定输入顺序的序列数据的首选方法是RNNs。
RNN(循环神经网络)的工作方式与前馈神经网络类似,但是它们按顺序逐个元素地处理输入。
Transformer模型的灵感来自于RNN中的编码器-解码器架构。然而,与其使用循环,Transformer模型完全基于注意力机制。
除了提高循环神经网络(RNN)的性能外,Transformer 还提供了一种新的架构来解决许多其他任务,例如文本摘要、图像字幕和语音识别。
那么,循环神经网络(RNN)的主要问题是什么?它们在自然语言处理(NLP)任务中相当低效,原因有两个:
- 它们按顺序处理输入数据,一个接一个地。这种循环过程不利用现代图形处理单元(GPU),而GPU是为并行计算而设计的,因此训练这种模型相当慢。
- 当元素彼此之间距离较远时,它们变得相当无效。这是因为信息在每一步传递,链条越长,信息丢失的可能性就越大。
从循环神经网络(RNN)如LSTM到NLP中的Transformer的转变是由这两个主要问题驱动的,而Transformer通过利用注意机制的改进来评估这两个问题:
- 注意特定的单词,无论它们有多远。
- 提高性能速度。
因此,Transformer成为了RNN的自然改进。
接下来,让我们来看一下transformers是如何工作的。
Transformer架构
概述
Transformer最初用于序列转换或神经机器翻译,它在将输入序列转换为输出序列方面表现出色。它是第一个完全依赖自注意力机制来计算输入和输出表示的转换模型,而不使用序列对齐的RNN或卷积。Transformer架构的主要核心特征是它维护了编码器-解码器模型。
如果我们将Transformer视为一个简单的黑盒子来考虑语言翻译,它会将一个句子作为输入,比如英语,然后输出它的英语翻译。

图片由作者提供。
如果我们深入研究一下,我们会发现这个黑盒子由两个主要部分组成:
- 编码器接收我们的输入并输出该输入的矩阵表示。例如,英文句子“How are you?”
- 解码器接收编码表示,并逐步生成输出。在我们的例子中,翻译成的句子是“¿Cómo estás?”
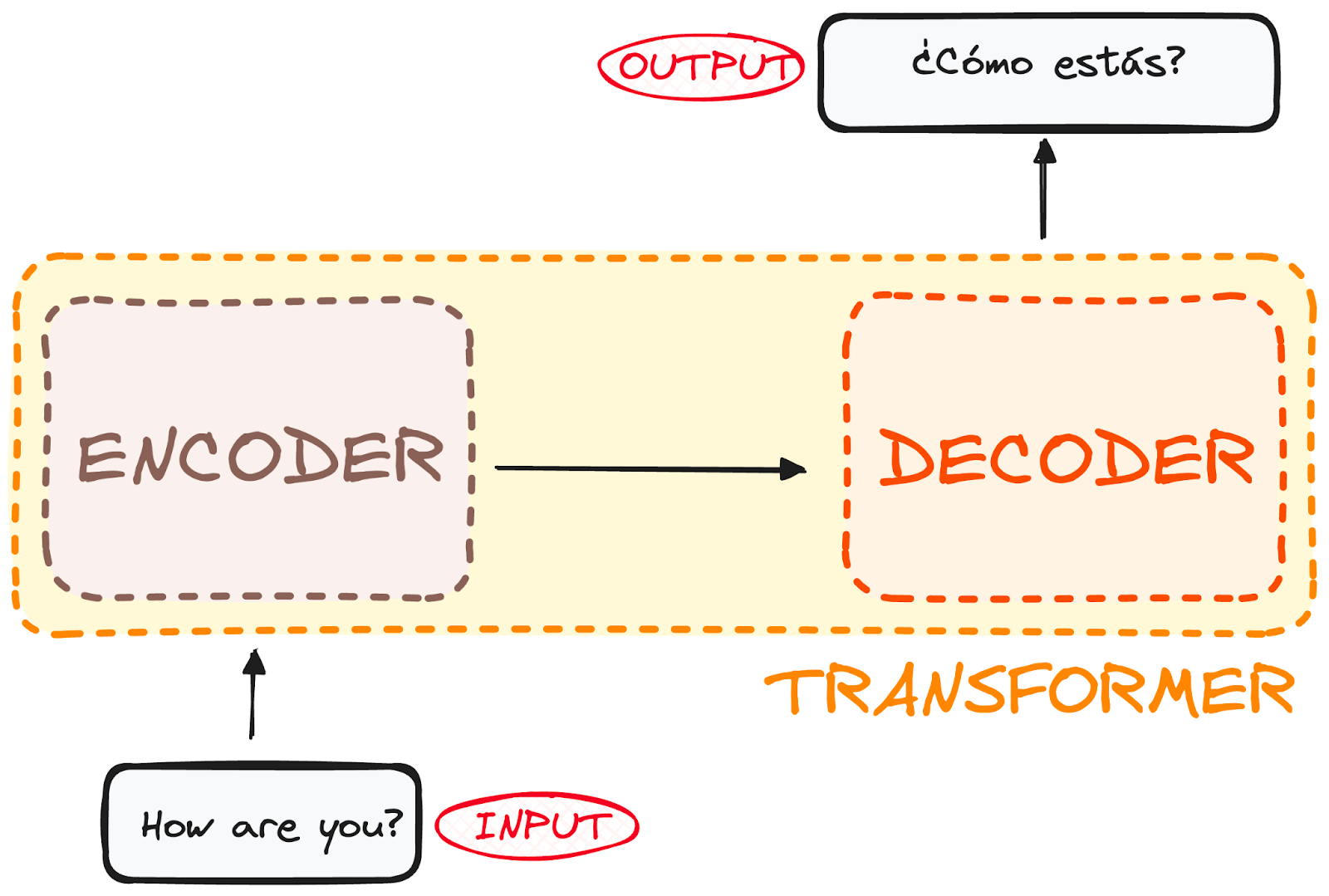
作者提供的图片。编码器-解码器的全局结构。
然而,编码器和解码器实际上都是具有多个层的堆栈(每个层的数量相同)。所有编码器都具有相同的结构,输入进入每个编码器并传递给下一个编码器。所有解码器也具有相同的结构,并从最后一个编码器和前一个解码器获取输入。
原始架构由6个编码器和6个解码器组成,但我们可以复制任意数量的层。所以假设每个层有N个。
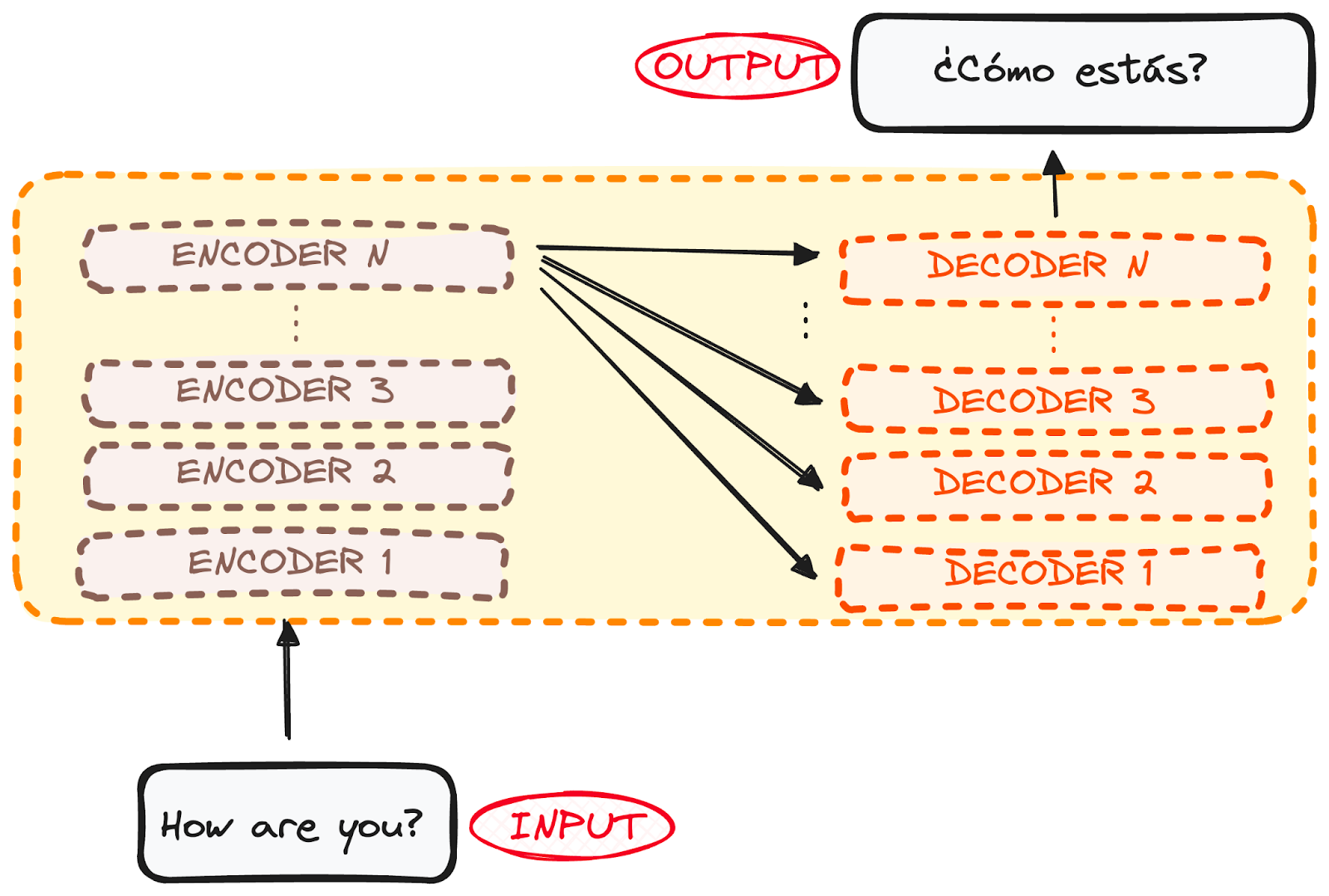
作者提供的图片。编码器-解码器的全局结构。多层。
现在我们对Transformer的整体架构有了一个通用的概念,让我们专注于编码器和解码器,以更好地理解它们的工作流程:
编码器工作流程
编码器是Transformer架构的基本组件。编码器的主要功能是将输入的标记转换为上下文化的表示。与之前独立处理标记的模型不同,Transformer编码器捕捉每个标记相对于整个序列的上下文。
它的结构组成如下:
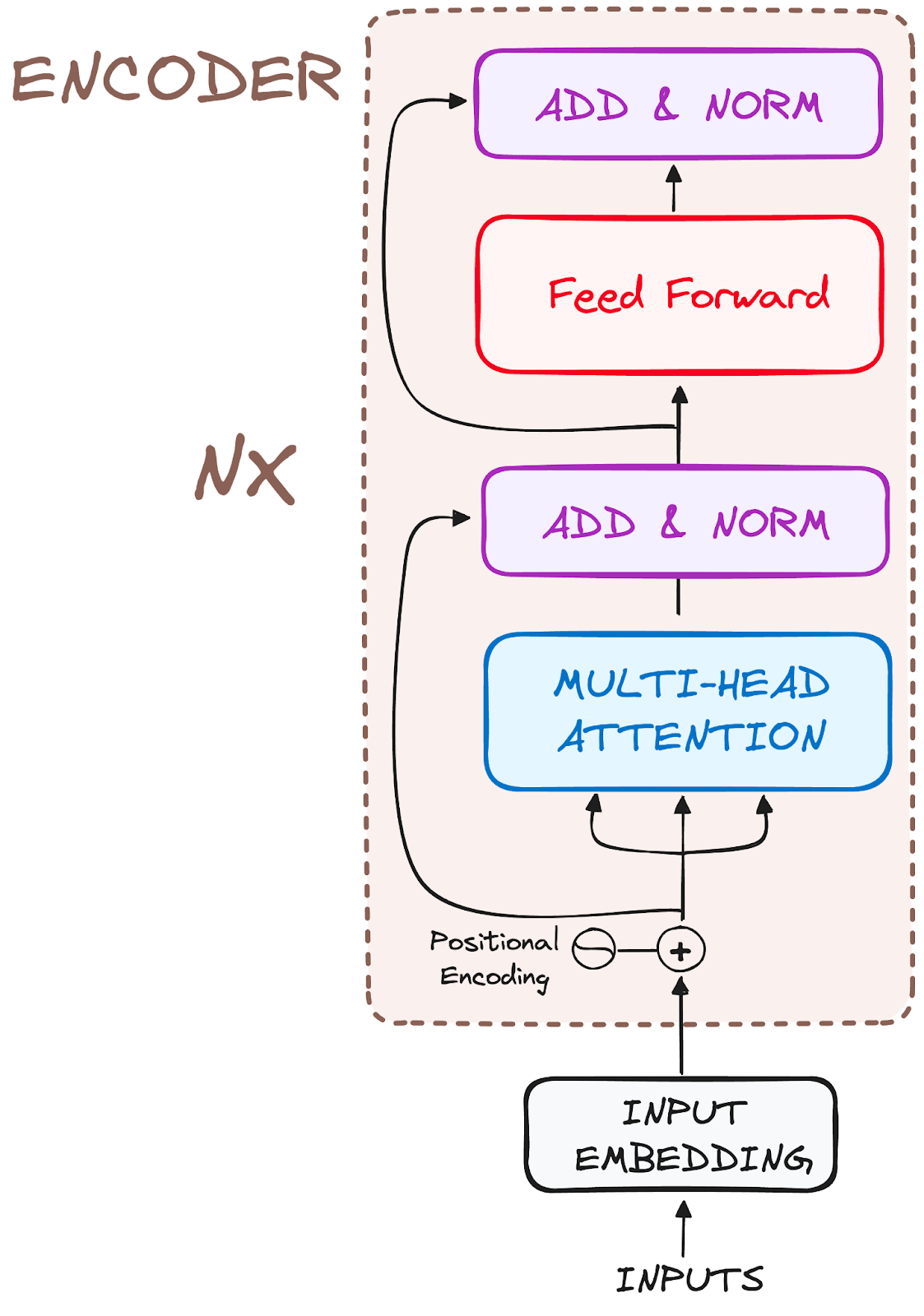
作者提供的图片。编码器的全局结构。
所以让我们将其工作流程分解为最基本的步骤:
步骤1 – 输入嵌入
嵌入只发生在最底层的编码器中。编码器首先通过使用嵌入层将输入标记 – 单词或子词 – 转换为向量。这些嵌入捕捉标记的语义含义,并将其转换为数值向量。
所有的编码器都接收一个大小为512的向量列表(固定大小)。在底部编码器中,这将是词嵌入,但在其他编码器中,它将是直接位于它们下方的编码器的输出。
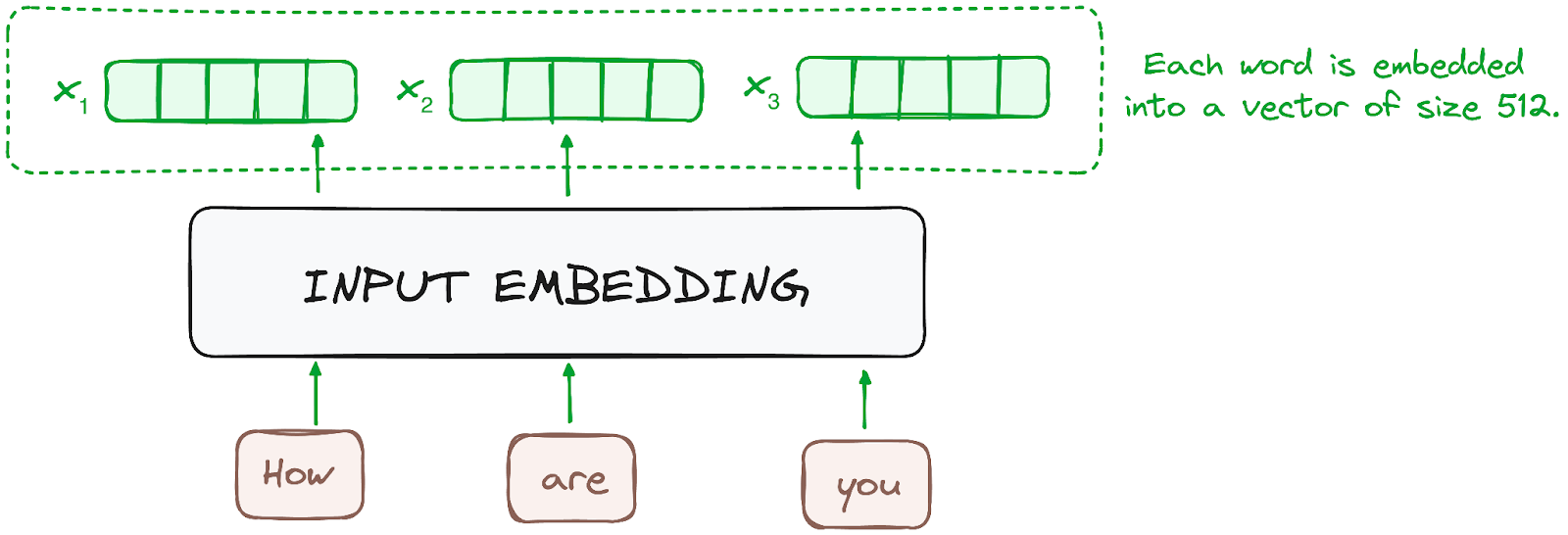
作者提供的图片。编码器的工作流程。输入嵌入。
步骤2 – 位置编码
由于Transformer没有像RNN那样的循环机制,它们使用位置编码添加到输入嵌入中,以提供关于序列中每个标记位置的信息。这使它们能够理解句子中每个单词的位置。
为了做到这一点,研究人员建议使用各种正弦和余弦函数的组合来创建位置向量,从而使得可以将这个位置编码器用于任意长度的句子。在这种方法中,每个维度由波的唯一频率和偏移量表示,其值范围从-1到1,有效地表示每个位置。
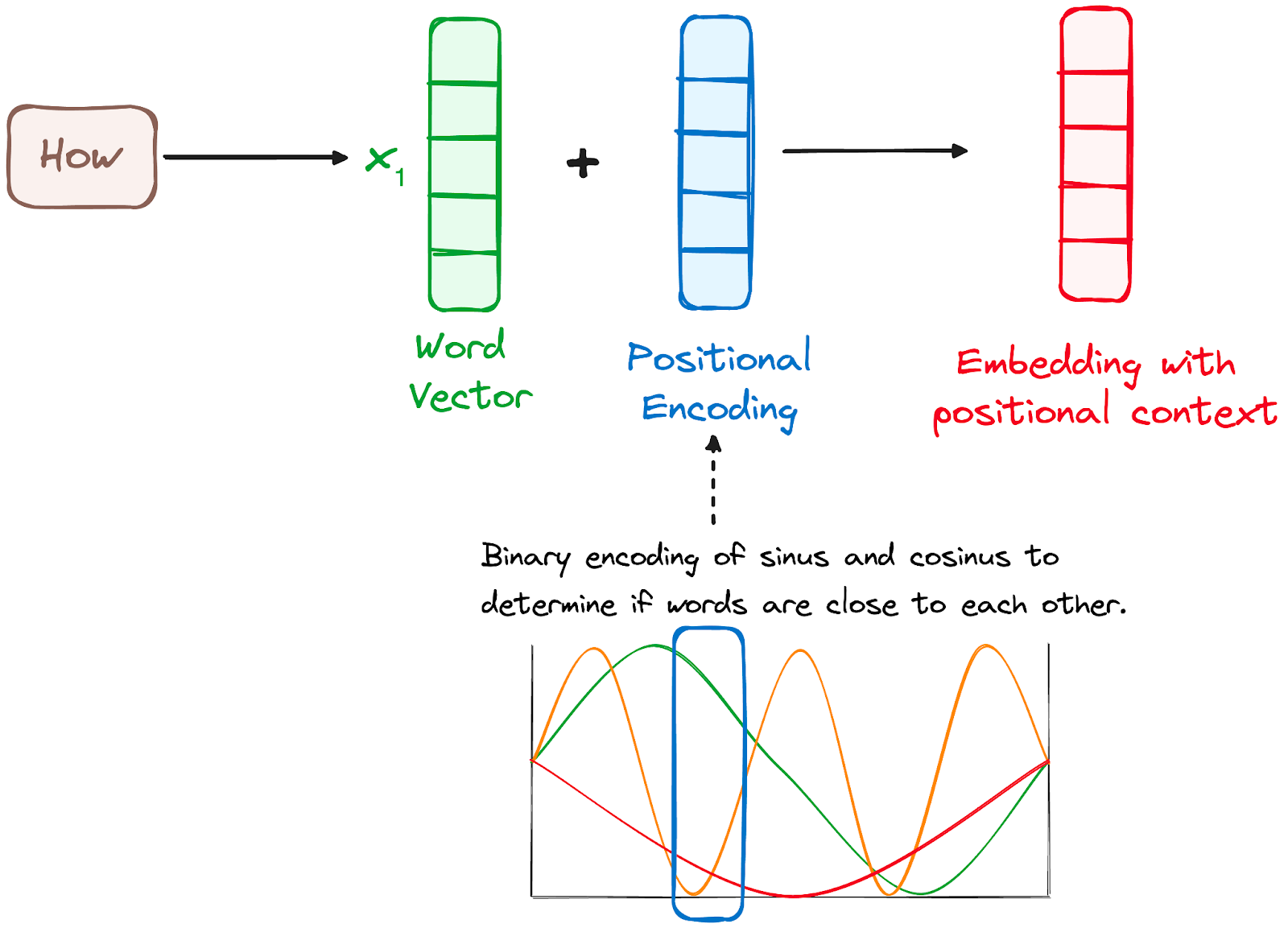
作者提供的图片。编码器的工作流程。位置编码。
第三步 – 编码器层的堆叠
Transformer编码器由一堆相同的层组成(原始Transformer模型中有6层)。
编码器层的作用是将所有输入序列转化为一个连续的、抽象的表示,该表示封装了整个序列中学到的信息。该层包括两个子模块:
- 一个多头注意力机制。
- 一个全连接网络。
此外,它还包括每个子层周围的残差连接,然后是层归一化。
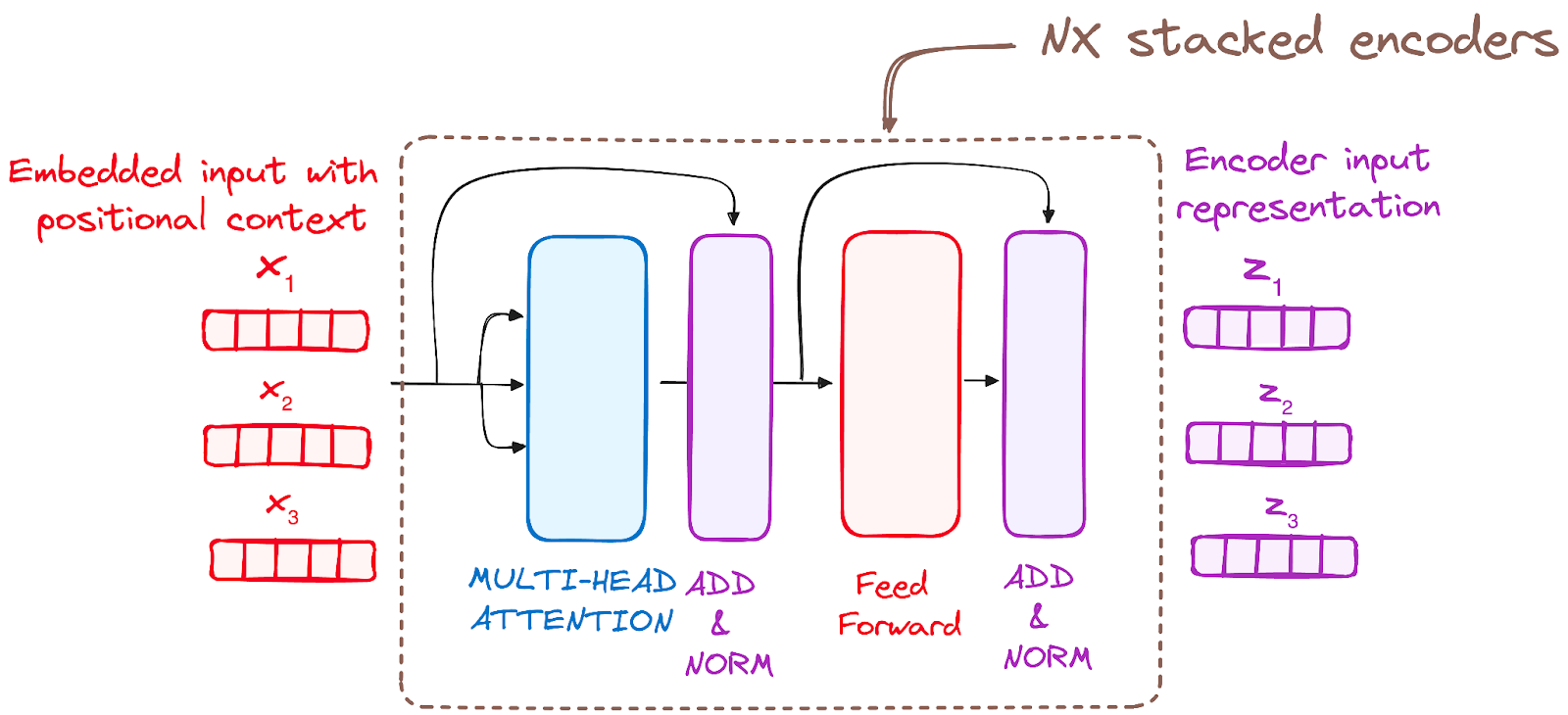
作者提供的图片。编码器的工作流程。编码器层的堆栈
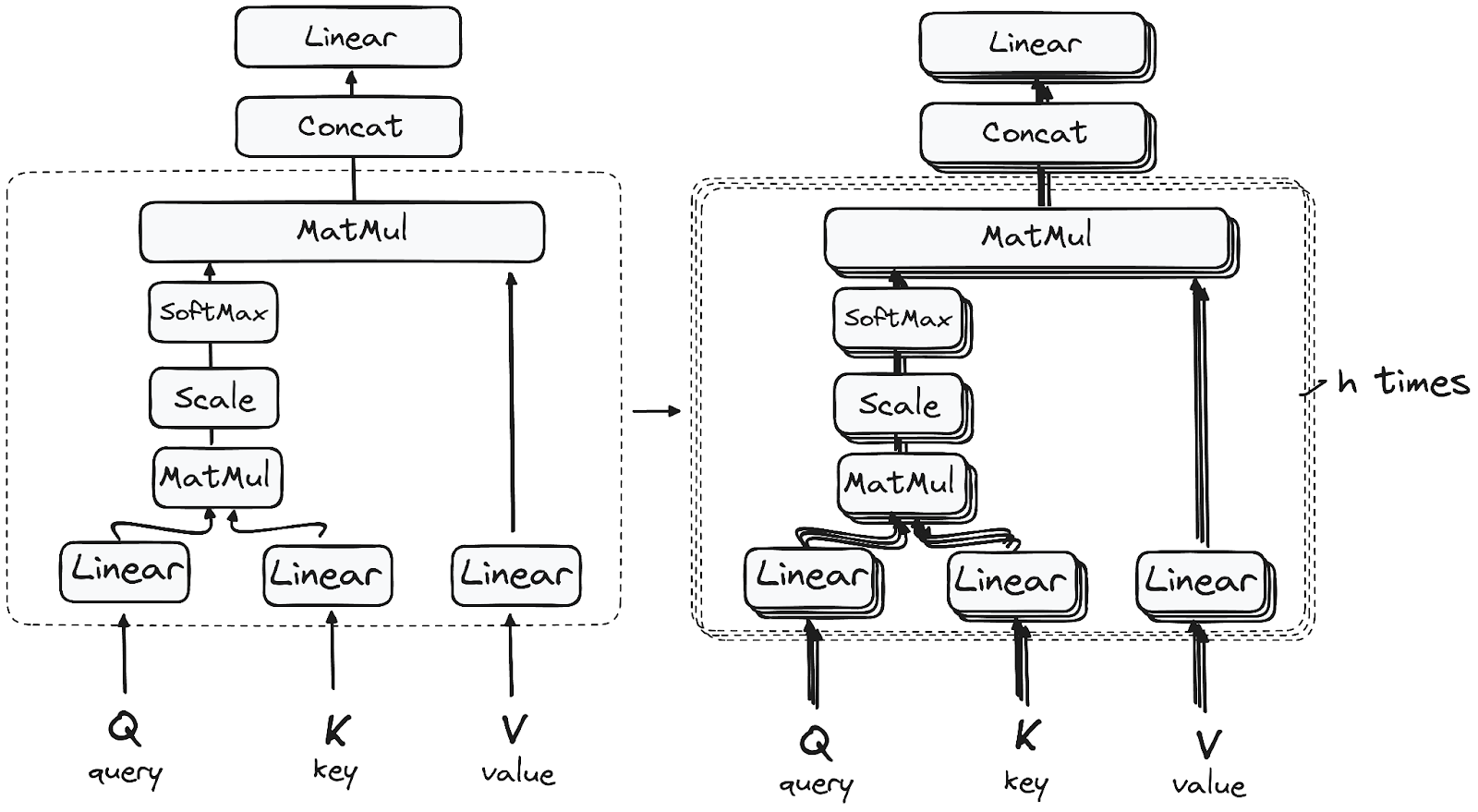
步骤3.1 多头自注意力机制
在编码器中,多头注意力机制利用一种称为自注意力的专门注意力机制。这种方法使得模型能够将输入中的每个单词与其他单词相关联。例如,在给定的示例中,模型可能学会将单词“are”与“you”连接起来。
这个机制允许编码器在处理每个标记时专注于输入序列的不同部分。它根据以下内容计算注意力分数:
- 查询是在注意机制中表示输入序列中特定单词或标记的向量。
- 键也是注意机制中的向量,对应于输入序列中的每个单词或标记。
- 每个值与一个键相关联,并用于构建注意层的输出。当查询和键匹配良好时,也就是说它们具有较高的注意分数,相应的值在输出中被强调。
这个第一个自注意模块使模型能够从整个序列中捕捉上下文信息。不是执行单个注意函数,而是将查询、键和值线性投影h次。在这些投影版本的查询、键和值上并行执行注意机制,产生h维的输出值。
详细的架构如下:
矩阵乘法(MatMul)- 查询和键的点积
一旦查询、键和值向量通过线性层,查询和键之间进行点积矩阵乘法运算,从而创建一个得分矩阵。
分数矩阵确定了每个单词在其他单词上应该放置的重点程度。因此,每个单词都被分配一个与同一时间步内的其他单词相关的分数。较高的分数表示更大的关注。
这个过程有效地将查询映射到它们对应的键。
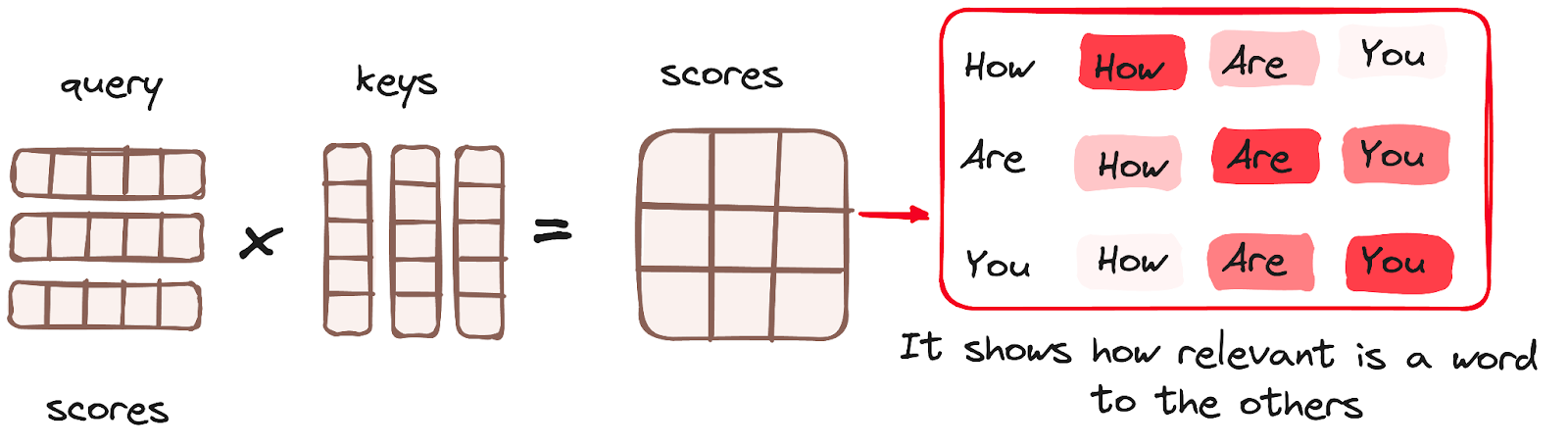
作者提供的图片。编码器的工作流程。注意机制 – 矩阵乘法。
减小注意力分数的幅度
然后,通过将它们除以查询和键向量的维度的平方根来缩小分数。这一步骤的目的是确保更稳定的梯度,因为值的乘法可能导致过大的影响。
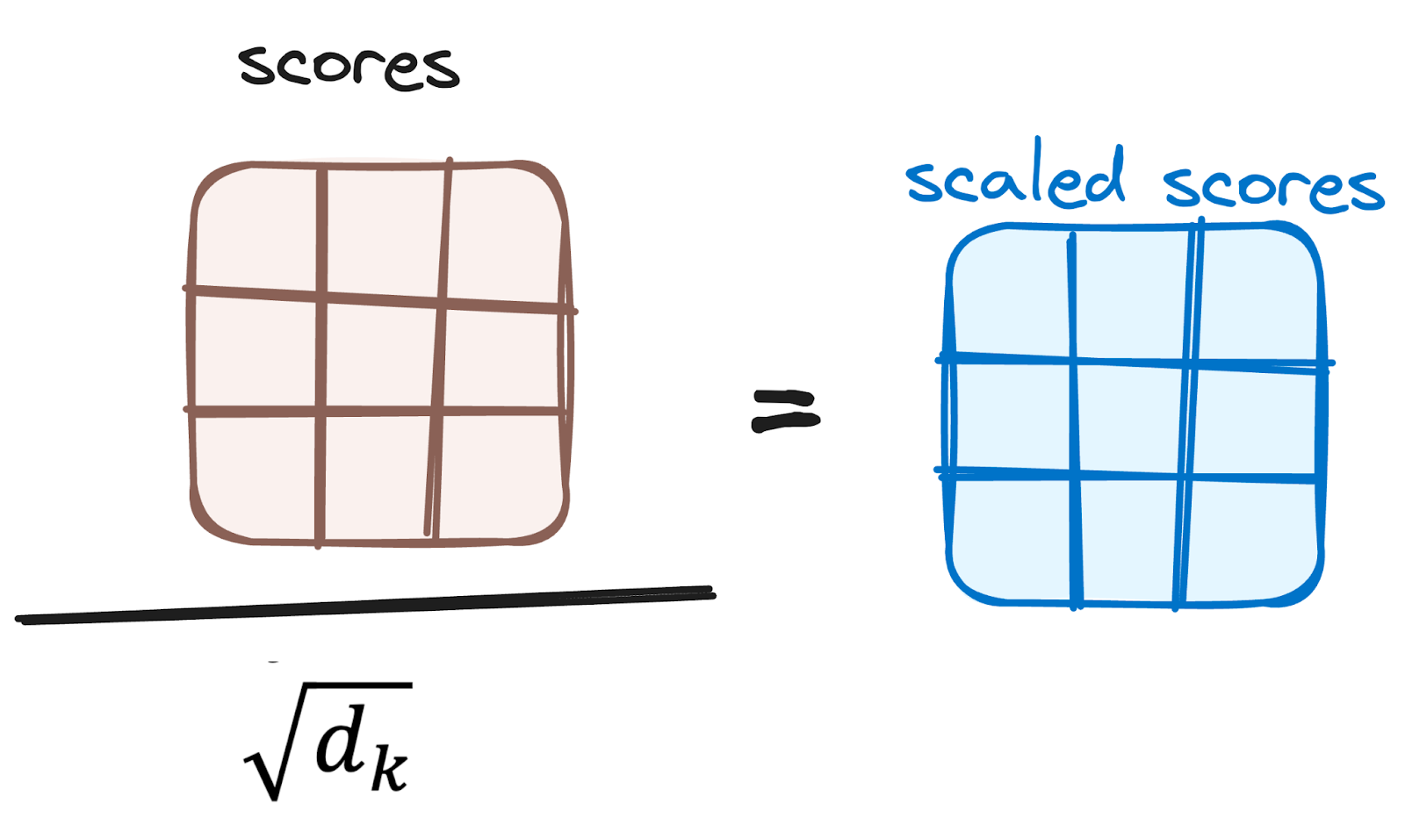
作者提供的图片。编码器的工作流程。减少注意力分数。
将调整后的分数应用于Softmax函数
随后,将Softmax函数应用于调整后的分数,以获得注意力权重。这将导致概率值从0到1。Softmax函数强调较高的分数,减弱较低的分数,从而增强模型有效确定哪些单词应该受到更多关注的能力。
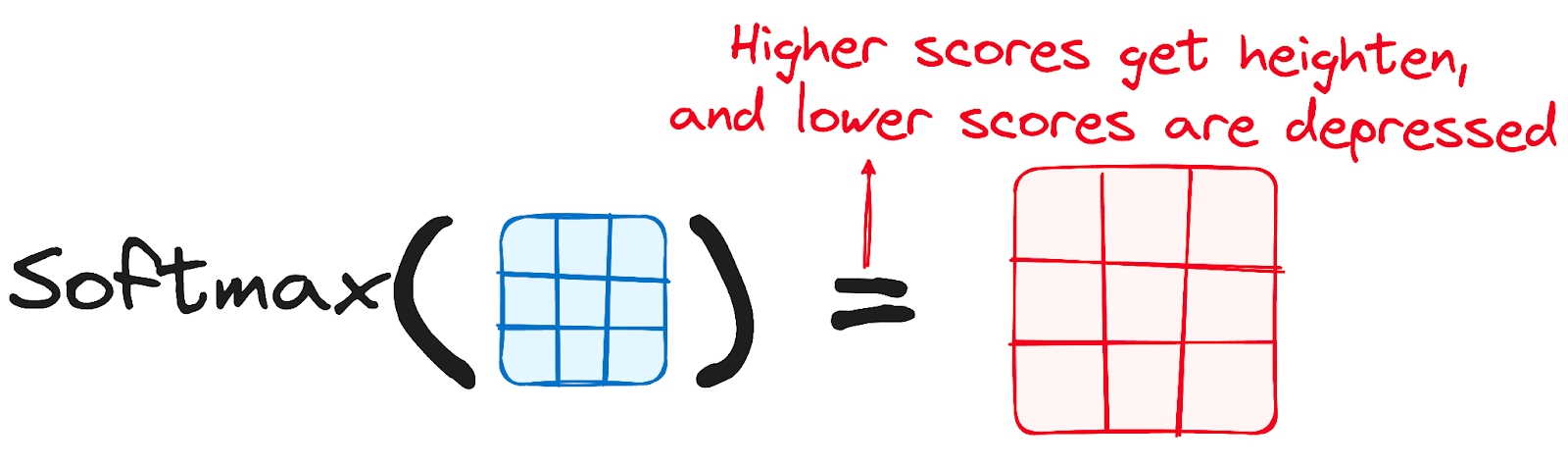
作者提供的图片。编码器的工作流程。Softmax调整的分数。
将Softmax结果与值向量相结合
注意机制的下一步是,从Softmax函数中得出的权重与值向量相乘,得到一个输出向量。
在这个过程中,只有具有高softmax分数的单词被保留。最后,这个输出向量被输入到一个线性层进行进一步处理。
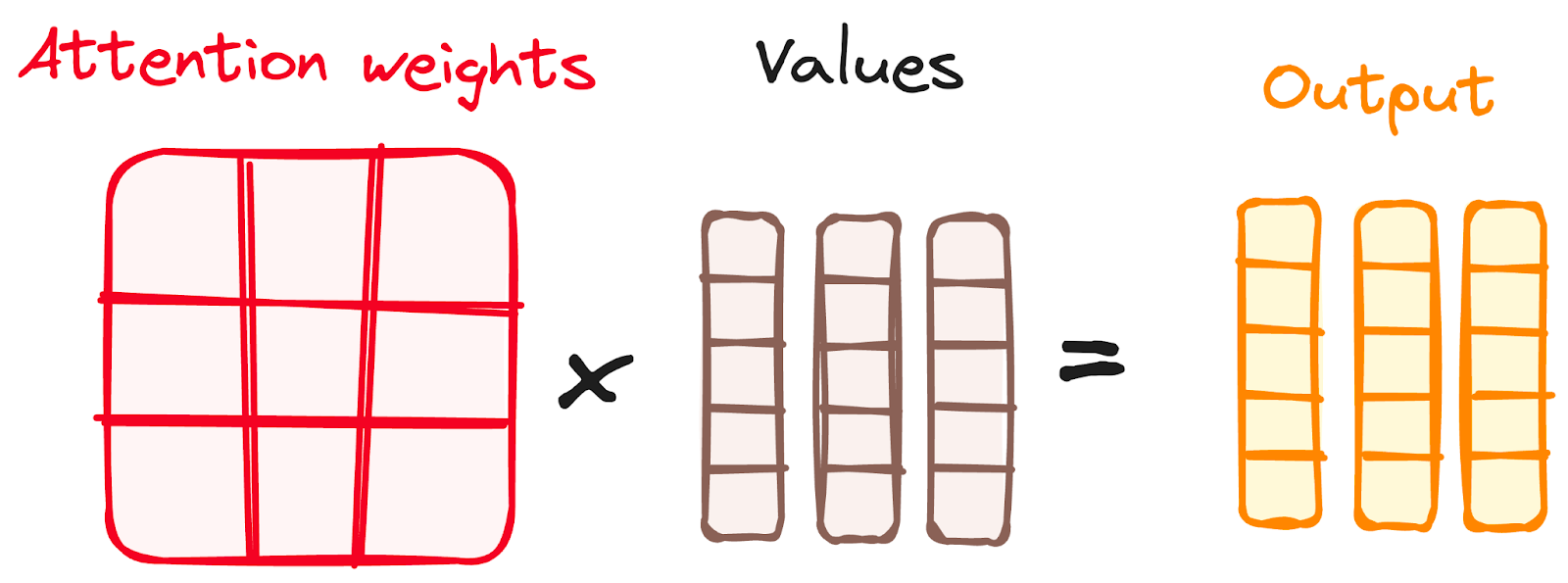
作者提供的图片。编码器的工作流程。将Softmax结果与值向量相结合。
我们终于得到了注意力机制的输出!
所以,你可能想知道为什么它被称为多头注意力?
在整个过程开始之前,请记住我们将查询、键和值分成h个部分。这个过程被称为自注意力,它在每个较小的阶段或“头部”中分别进行。每个头部都独立地进行自己的魔法,产生一个输出向量。
这个集合通过一个最后的线性层,就像一个过滤器,对它们的集体表现进行微调。这里的美妙之处在于每个头部之间的学习多样性,为编码器模型提供了强大而多方面的理解。
步骤 3.2 标准化和残差连接
编码器层中的每个子层后面都跟随一个标准化步骤。此外,每个子层的输出会与其输入相加(残差连接),以帮助缓解梯度消失问题,从而允许更深层的模型。这个过程在前馈神经网络之后也会重复进行。
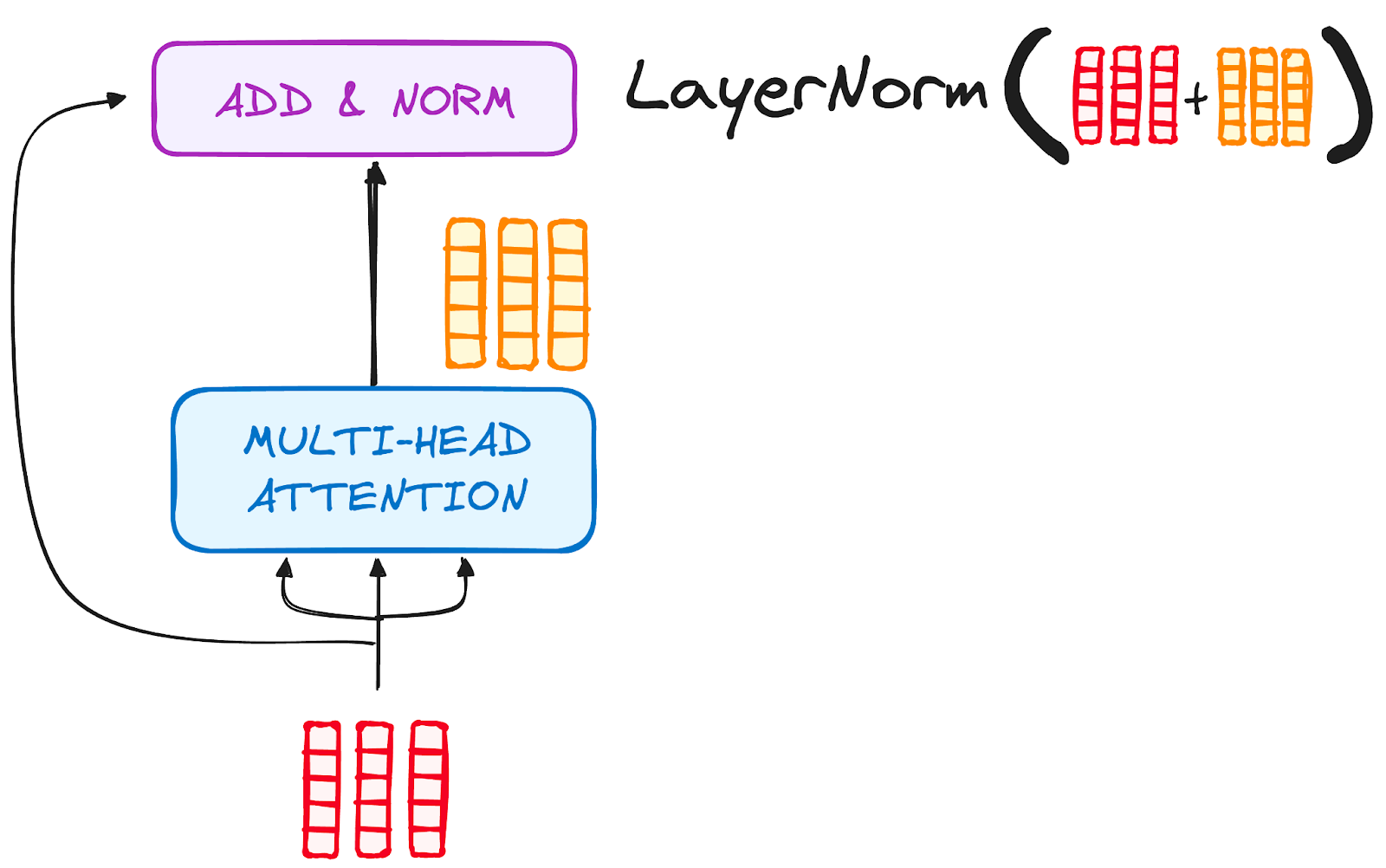
作者提供的图片。编码器的工作流程。在多头注意力之后进行归一化和残差连接。
步骤 3.3 前馈神经网络
标准化残差输出的旅程在通过逐点前馈网络时继续进行,这是一个关键的阶段,用于进一步的优化。
将这段文字翻译成中文,不要去除视频和图片标签,保留代码块: ‘
将这个网络想象成由两个线性层组成,中间嵌套着一个ReLU激活函数,作为桥梁。一旦处理完毕,输出就会进入一个熟悉的路径:它会循环回来并与逐点前馈网络的输入合并。
‘
这次重聚之后,还会进行另一轮的规范化,确保一切都能够良好调整并同步进行下一步。
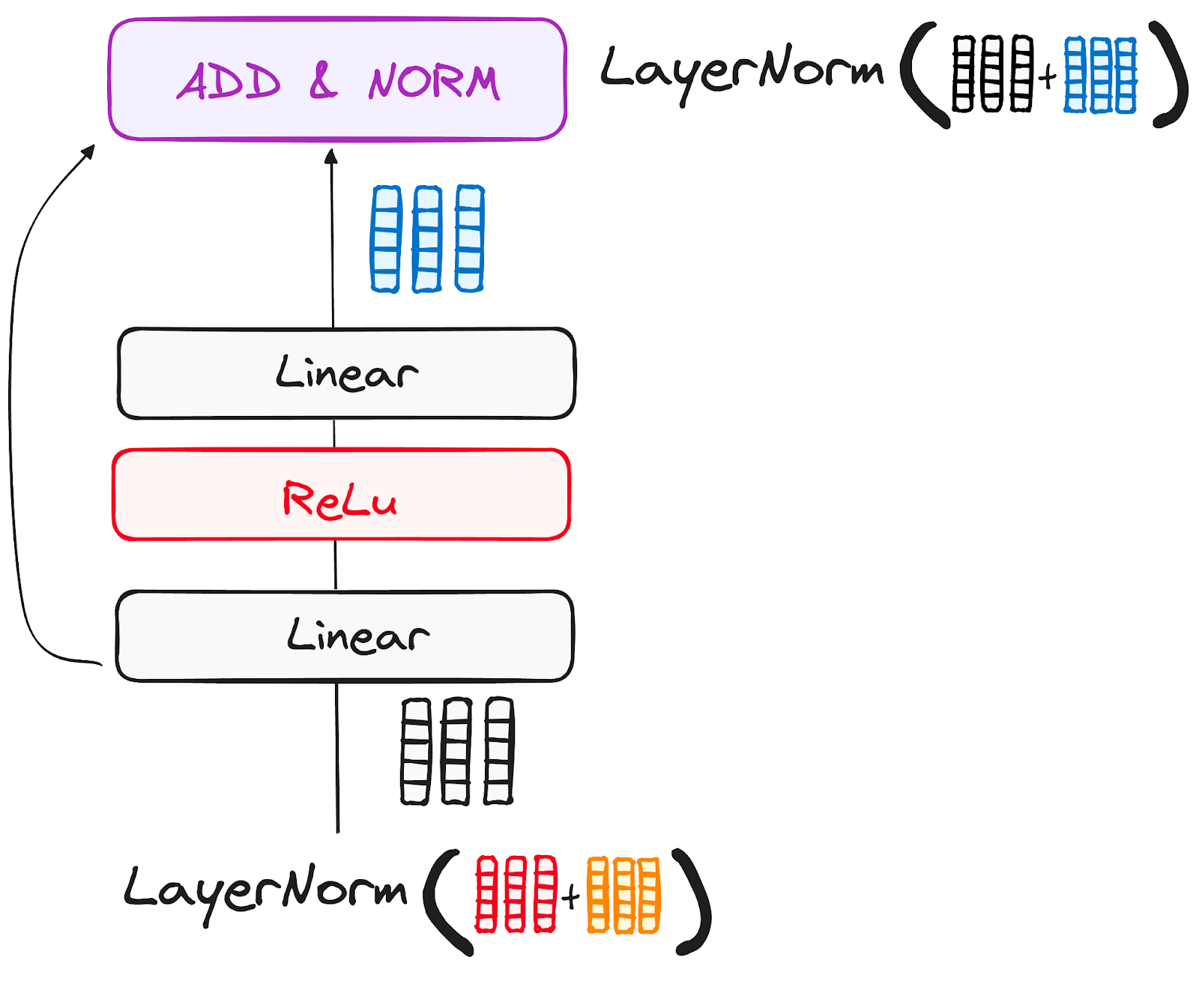
作者提供的图片。编码器的工作流程。前馈神经网络子层。
第四步 – 编码器的输出
最终编码器层的输出是一组向量,每个向量代表着具有丰富上下文理解的输入序列。然后,这个输出被用作Transformer模型中解码器的输入。
这种谨慎的编码为解码器铺平了道路,引导它在解码时注意输入中的正确单词。
将其想象成建造一座塔,您可以堆叠N个编码器层。这个堆栈中的每一层都有机会探索和学习注意力的不同方面,就像知识的层次一样。这不仅可以多样化理解,还可以显著增强变压器网络的预测能力。
解码器工作流程
解码器的作用是构建文本序列。与编码器相呼应,解码器配备了一组类似的子层。它拥有两个多头注意力层,一个逐点前馈层,并在每个子层之后都使用残差连接和层归一化。
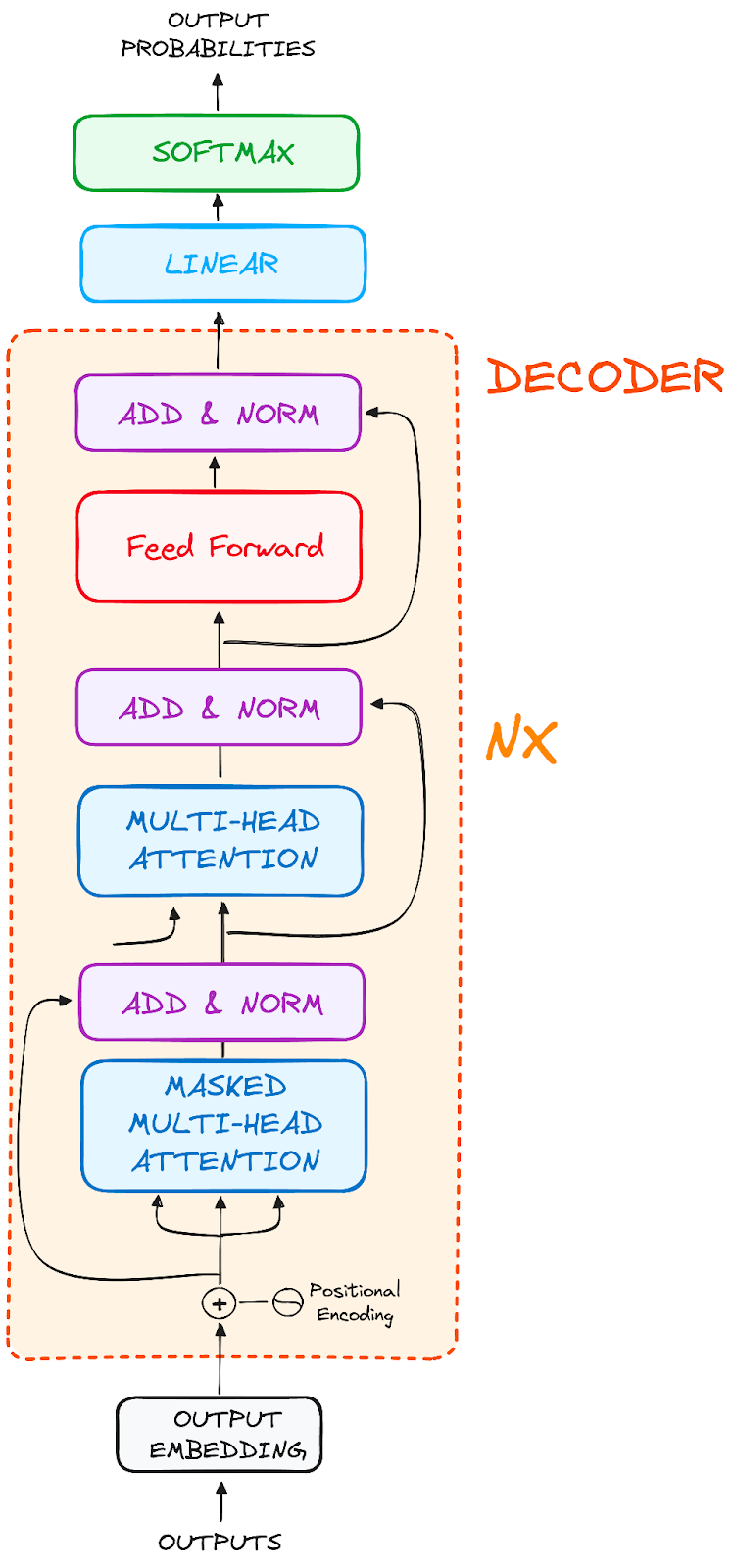
作者提供的图片。编码器的全局结构。
这些组件的功能类似于编码器的层,但有一个小变化:解码器中的每个多头注意力层都有其独特的任务。
解码器的最后一个步骤涉及一个线性层,作为分类器,最后使用softmax函数来计算不同单词的概率。
Transformer解码器具有专门设计的结构,通过逐步解码编码信息来生成此输出。
需要注意的是,解码器以自回归的方式运行,通过一个起始标记来启动其过程。它巧妙地使用先前生成的输出列表作为其输入,与来自编码器的输出一起使用,这些输出包含了来自初始输入的注意力信息。
这种顺序解码的舞蹈会一直持续下去,直到解码器达到一个关键时刻:生成一个标记,表示输出创建的结束。
步骤1 – 输出嵌入
在解码器的起始行,过程与编码器相似。在这里,输入首先通过一个嵌入层
步骤2 – 位置编码
在嵌入之后,就像解码器一样,输入经过位置编码层。这个序列被设计用来产生位置嵌入。
然后,这些位置嵌入被传送到解码器的第一个多头注意力层中,其中针对解码器输入的注意力分数被精确计算。
步骤3 – 解码器层的堆叠
解码器由一堆相同的层组成(原始Transformer模型中有6层)。每个层都有三个主要的子组件:
步骤 3.1 掩码自注意机制
这与编码器中的自注意机制类似,但有一个关键的区别:它防止位置关注后续位置,这意味着序列中的每个单词不会受到未来标记的影响。
例如,当计算单词”are”的注意力分数时,重要的是”are”不能窥视到序列中的后续单词”you”。
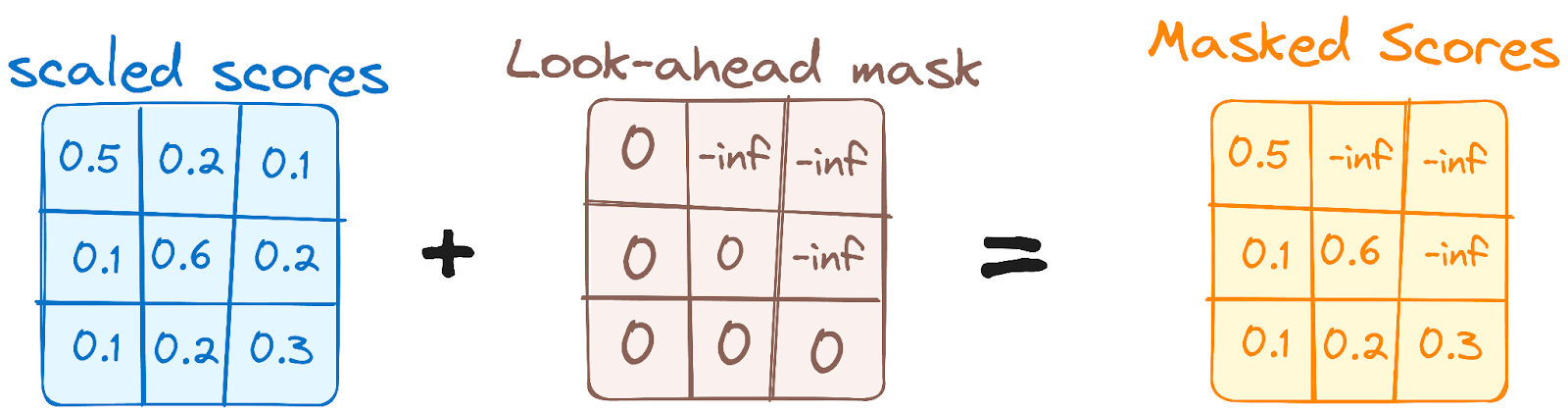
作者提供的图片。解码器的工作流程。首个多头注意力掩码。
这种掩码确保特定位置的预测只能依赖于之前位置的已知输出。
步骤3.2 – 编码器-解码器多头注意力或交叉注意力
在解码器的第二个多头注意力层中,我们可以看到编码器和解码器组件之间的独特相互作用。在这里,编码器的输出既扮演查询和键的角色,而解码器的第一个多头注意力层的输出则作为值。
这个设置有效地将编码器的输入与解码器的输入对齐,使解码器能够识别和强调编码器输入中最相关的部分。
在此之后,来自第二层多头注意力的输出通过一个逐点前馈层进行进一步的处理和优化。
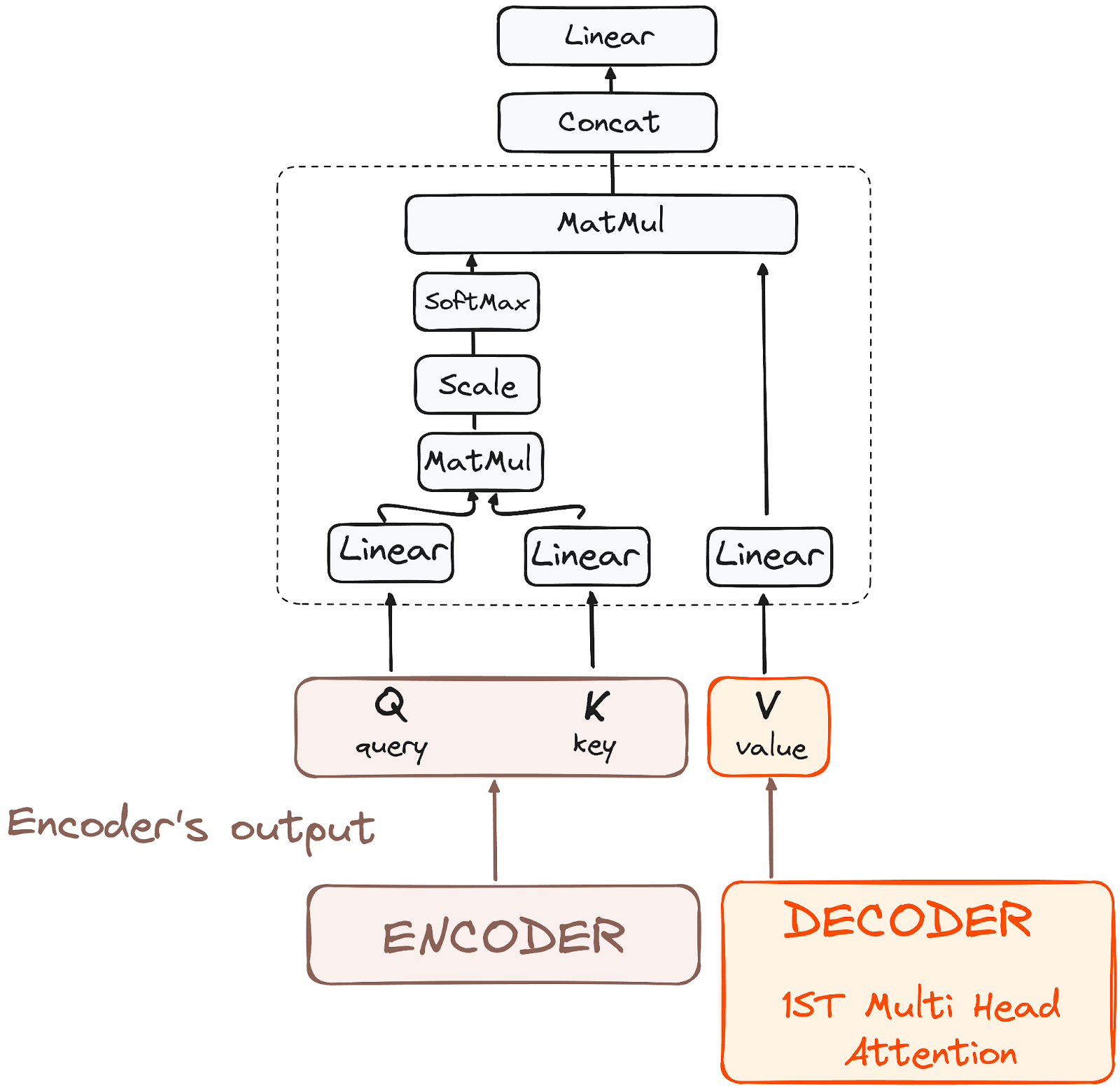
作者提供的图片。解码器的工作流程。编码器-解码器注意力。
在这个子层中,查询来自前一个解码器层,而键和值来自编码器的输出。这使得解码器中的每个位置都可以关注输入序列中的所有位置,有效地将编码器中的信息与解码器中的信息整合在一起。
步骤 3.3 前馈神经网络
与编码器类似,每个解码器层都包括一个完全连接的前馈网络,分别应用于每个位置,并且相同。
步骤4 线性分类器和Softmax生成输出概率
数据通过变换器模型的旅程最终通过一个最终的线性层,该层充当分类器。
这个分类器的大小对应于涉及的类别总数(词汇表中包含的单词数)。例如,在一个表示1000个不同单词的1000个不同类别的场景中,分类器的输出将是一个包含1000个元素的数组。
然后,这个输出被输入到一个softmax层中,将其转换为一系列概率分数,每个分数都介于0和1之间。其中最高的概率分数是关键的,其对应的索引直接指向模型预测的序列中的下一个单词。
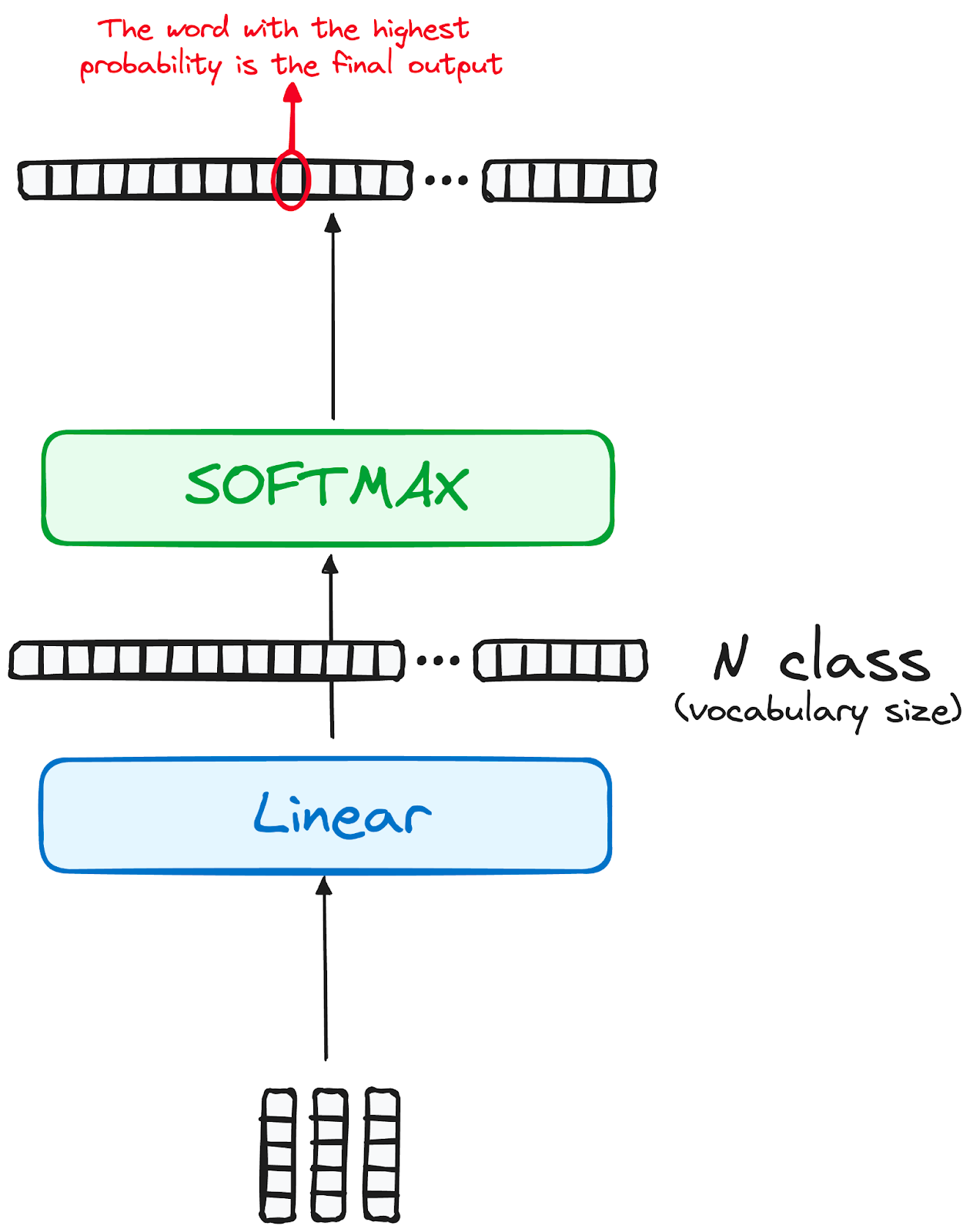
作者提供的图片。解码器的工作流程。Transformer的最终输出。
归一化和残差连接
每个子层(掩码自注意力,编码器-解码器注意力,前馈网络)后面都跟着一个归一化步骤,并且每个子层还包括一个围绕它的残差连接。
解码器的输出
最后一层的输出通过线性层转换为预测序列,通常在softmax之后生成对词汇表的概率。
解码器在其操作流程中,将新生成的输出整合到其不断增长的输入列表中,然后继续解码过程。这个循环重复进行,直到模型预测出特定的令牌,表示完成。
预测概率最高的令牌被分配为最终的类别,通常由结束令牌表示。
再次记住,解码器不限于单个层。它可以由N个层组成,每个层都建立在来自编码器和其前面层的输入之上。这种分层架构使模型能够多样化其关注点,并在其注意力头部中提取不同的注意力模式。
这样的多层次方法可以显著提高模型的预测能力,因为它可以更细致地理解不同的注意力组合。
最终的架构类似于这样(来自原始论文)
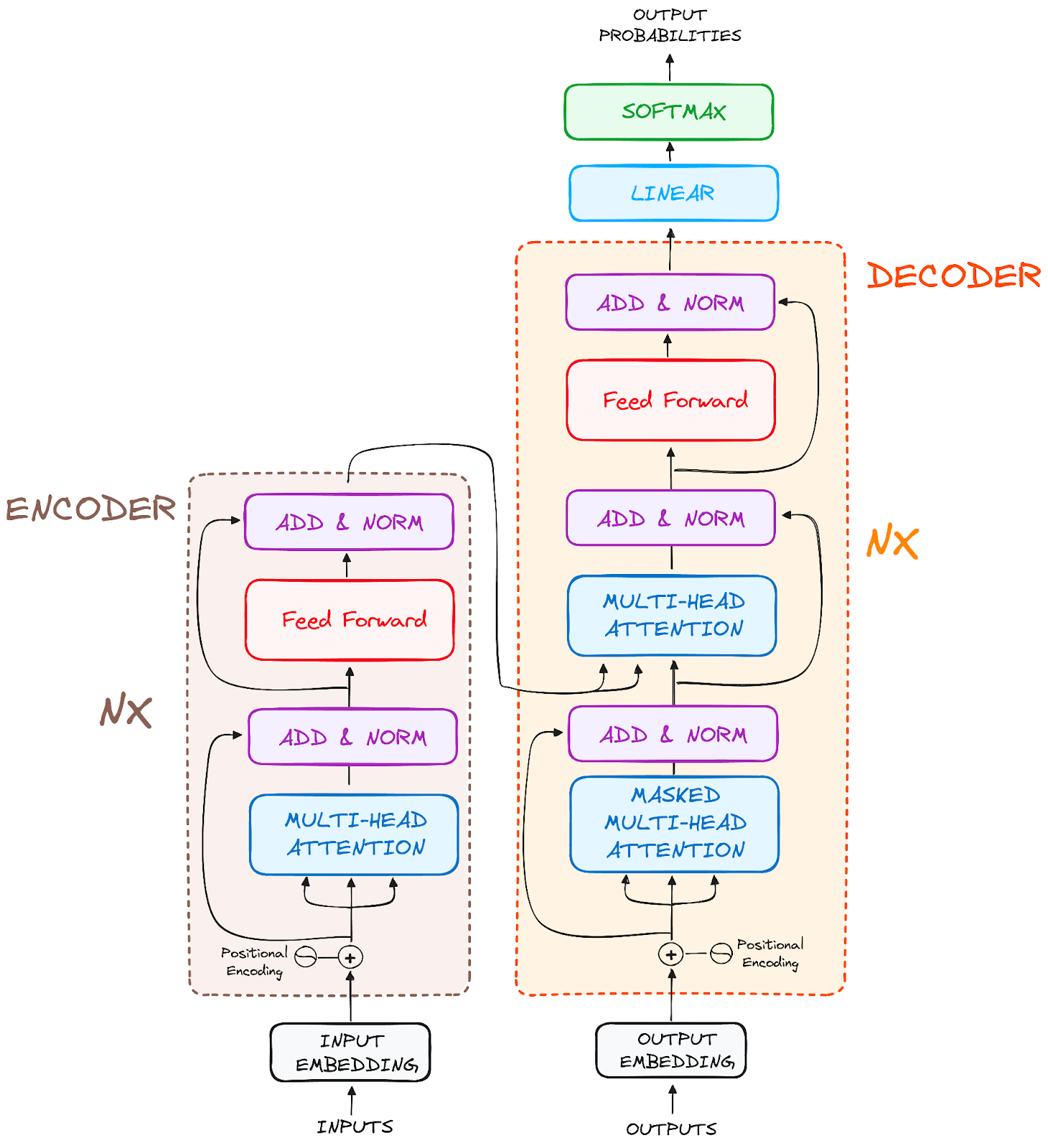
作者提供的图片。Transformer的原始结构。
为了更好地理解这个架构,我建议尝试从头开始应用一个Transformer,可以参考这个使用PyTorch构建Transformer的教程。
现实生活中的Transformer模型
BERT
Google于2018年发布了BERT,这是一个开源的自然语言处理框架,通过其独特的双向训练,彻底改变了NLP领域。这种训练方式使得模型能够更好地预测下一个词应该是什么,从而更好地理解上下文。
通过全面理解单词的各个方面的上下文,BERT在问答和理解模糊语言等任务中表现优于以前的模型。它的核心使用了Transformer,动态地连接每个输出和输入元素。
BERT,预训练于维基百科,在各种自然语言处理任务中表现出色,促使谷歌将其整合到其搜索引擎中,以实现更自然的查询。这一创新引发了开发先进语言模型的竞赛,并显著提升了该领域处理复杂语言理解的能力。
要了解更多关于BERT的信息,您可以查看我们的单独文章,该文章介绍了BERT模型。
LaMDA
LaMDA(对话应用语言模型)是由Google开发的基于Transformer的模型,专门为对话任务设计,并在2021年Google I/O主题演讲中发布。它们旨在生成更自然和上下文相关的回复,增强各种应用中的用户交互。
LaMDA的设计使其能够理解和回应各种主题和用户意图,使其成为聊天机器人、虚拟助手和其他交互式人工智能系统的理想选择,其中动态对话至关重要。
这种对话理解和回应的关注使LaMDA成为自然语言处理和人工智能驱动通信领域的重大进展。
如果你对LaMDA模型进一步了解感兴趣,你可以通过LaMDA文章更好地理解。
GPT和ChatGPT
GPT和ChatGPT是由OpenAI开发的先进生成模型,以其产生连贯且与上下文相关的文本的能力而闻名。GPT-1是其于2018年6月推出的第一个模型,而GPT-3则是在两年后的2020年推出的最具影响力的模型之一。
这些模型擅长各种任务,包括内容创作、对话、语言翻译等等。GPT的架构使其能够生成与人类写作非常相似的文本,使其在创意写作、客户支持甚至编码辅助等应用中非常有用。ChatGPT是一种针对对话环境进行优化的变体,擅长生成类似人类对话的对话,增强了其在聊天机器人和虚拟助手中的应用。
其他变体
基础模型,特别是Transformer模型的领域正在迅速扩展。一项研究发现了50多个重要的Transformer模型,而斯坦福大学的研究小组评估了其中的30个,承认该领域的发展速度快。NLP Cloud是NVIDIA Inception计划中的一家创新型初创公司,商业上利用大约25个大型语言模型为航空公司和药店等各个行业提供服务。
越来越多的趋势是将这些模型开源,像Hugging Face的模型中心这样的平台引领着这一潮流。此外,已经开发了许多基于Transformer的模型,每个模型都专门针对不同的自然语言处理任务,展示了模型在各种应用中的多样性和效率。
您可以在一篇单独的文章中了解更多关于所有现有的基础模型的信息,该文章介绍了它们是什么以及哪些是最常用的。
基准测试和性能
在自然语言处理中,对Transformer模型进行基准测试和性能评估需要采用系统化的方法来评估其效果和效率。
根据任务的性质,有不同的方法和资源可以做到这一点:
Depending on the nature of the task, there are different ways and resources to do so:
机器翻译任务
在处理机器翻译任务时,您可以利用像WMT(机器翻译研讨会)这样的标准数据集,其中MT系统会遇到各种语言对,每个语言对都提供其独特的挑战。
BLEU、METEOR、TER和chrF等指标是导航工具,引导我们朝着准确性和流畅性的方向前进。
此外,跨越新闻、文学和技术文本等多个领域的测试,确保了机器翻译系统的适应性和多功能性,使其成为数字世界中真正的多语种工具。
QA基准测试
为了评估QA模型,我们使用特殊的问题和答案集合,例如SQuAD(斯坦福问答数据集)、自然问题或TriviaQA。
每个都像是一个有着自己规则的不同游戏。例如,SQuAD是关于在给定的文本中找到答案,而其他的则更像是一个问答游戏,问题可以来自任何地方。
为了评估这些程序的表现如何,我们使用诸如精确度、召回率、F1值,有时甚至还有完全匹配分数等评分指标。
NLI基准测试
在处理自然语言推理(NLI)时,我们使用特殊的数据集,如SNLI(斯坦福自然语言推理)、MultiNLI和ANLI。
这些就像是语言变体和棘手案例的大型库,帮助我们了解计算机对不同类型句子的理解程度。我们主要检查计算机在理解陈述是否一致、相互矛盾或无关时的准确性。
同时,还要重点研究计算机如何解决一些棘手的语言问题,比如当一个词指的是前面提到的某个事物,或者理解’not’、’all’和’some’的含义。
与其他架构的比较
在神经网络领域,通常将Transformer与另外两种突出的结构进行比较。它们各自提供独特的优势和挑战,适用于特定类型的数据处理。RNNs已经在本文中多次出现,还有卷积层。
循环层
循环层是循环神经网络(RNN)的基石,擅长处理序列数据。这种架构的优势在于其能够执行顺序操作,对于语言处理或时间序列分析等任务至关重要。在循环层中,上一步的输出被反馈回网络作为下一步的输入。这种循环机制使得网络能够记住先前的信息,在理解序列中的上下文非常重要。
然而,正如我们已经讨论过的那样,这种顺序处理有两个主要的影响:
- 由于每一步都依赖于前一步,因此训练时间可能会更长,这使得并行处理变得具有挑战性。
- 由于梯度消失问题,它们经常在长期依赖性方面遇到困难,即网络在学习远离序列中的数据点时变得不太有效。
与使用循环层的架构相比,Transformer模型在很大程度上不同,因为它们缺乏循环性。正如我们之前所看到的,Transformer的Attention层解决了这两个问题,使它们成为自然演化的RNNs在NLP应用中。
卷积层
另一方面,卷积层是卷积神经网络(CNN)的构建模块,以其在处理像图片这样的空间数据方面的高效性而闻名。
这些层使用核(过滤器)在输入数据上进行扫描以提取特征。这些核的宽度可以调整,使网络能够根据手头的任务集中于小型或大型特征。
虽然卷积层在捕捉数据中的空间层次和模式方面非常出色,但它们在处理长期依赖性方面面临挑战。它们并不本质上考虑顺序信息,因此对于需要理解序列的顺序或上下文的任务来说,它们不太适用。
这就是为什么CNN和Transformer适用于不同类型的数据和任务。由于其在处理空间信息方面的高效性,CNN在计算机视觉领域占据主导地位,而Transformer则是处理复杂的顺序任务的首选,特别是在自然语言处理领域,因为它们能够理解长距离的依赖关系。
结论
总之,变形金刚已经成为人工智能和自然语言处理领域的重大突破。
通过有效地通过其独特的自注意机制管理顺序数据,这些模型已经超越了传统的RNN。它们处理长序列的能力更高效,并且并行化数据处理显著加速了训练。
开创性的模型,如Google的BERT和OpenAI的GPT系列,展示了Transformer在增强搜索引擎和生成类似人类文本方面的变革性影响。
作为结果,它们在现代机器学习中变得不可或缺,推动着人工智能的边界,并在技术进步中开辟了新的道路。如果你想了解 Transformers 及其使用方法,我们的文章《Transformers 和 Hugging Face 入门教程》是一个完美的起点!你还可以通过我们深入的指南学习如何使用 PyTorch 构建一个 Transformer。抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”