‘
大家都在关注OpenAI LLM排行榜和旨在达到GPT-4性能的新开源模型。最近引起很大关注的一个模型是Zephyr-7B。
‘在本教程中,我们将学习一个名为Zephyr-7B的新语言模型。我们将使用Transformers pipeline访问它,并在Agent-Instruct数据集上对模型进行微调。如果你对人工智能还不熟悉,可以查看AI Fundamentals技能轨迹。它将帮助你准备好,并为你成为未来的人工智能工程师铺平道路。
了解Zephyr-7B
Zephyr-7B是由WebPilot.AI开发的尖端语言模型。它是Zephyr系列语言模型的一部分,这些模型经过训练,可以作为有帮助的助手。Zephyr-7B旨在在各种基于语言的任务中表现出色,例如生成连贯的文本,跨不同语言进行翻译,总结重要信息,分析情感,并根据上下文回答问题。
Zephyr-7B-β
Zephyr-7B-β是该系列的第二个模型。它是Mistral-7B模型的优化版本,使用直接偏好优化(DPO)算法在公共和合成数据集的组合上进行训练。因此,Zephyr-7B-β展示了从解释复杂问题到总结长篇文字的能力。
发布时,Zephyr-7B-β是MT-Bench和AlpacaEval基准测试中排名最高的7B聊天模型。它利用自然语言处理的最新进展,达到了理解和生成类似人类文本的新高度。
您可以通过在Zephyr Chat上尝试免费演示来体验其改进的性能。
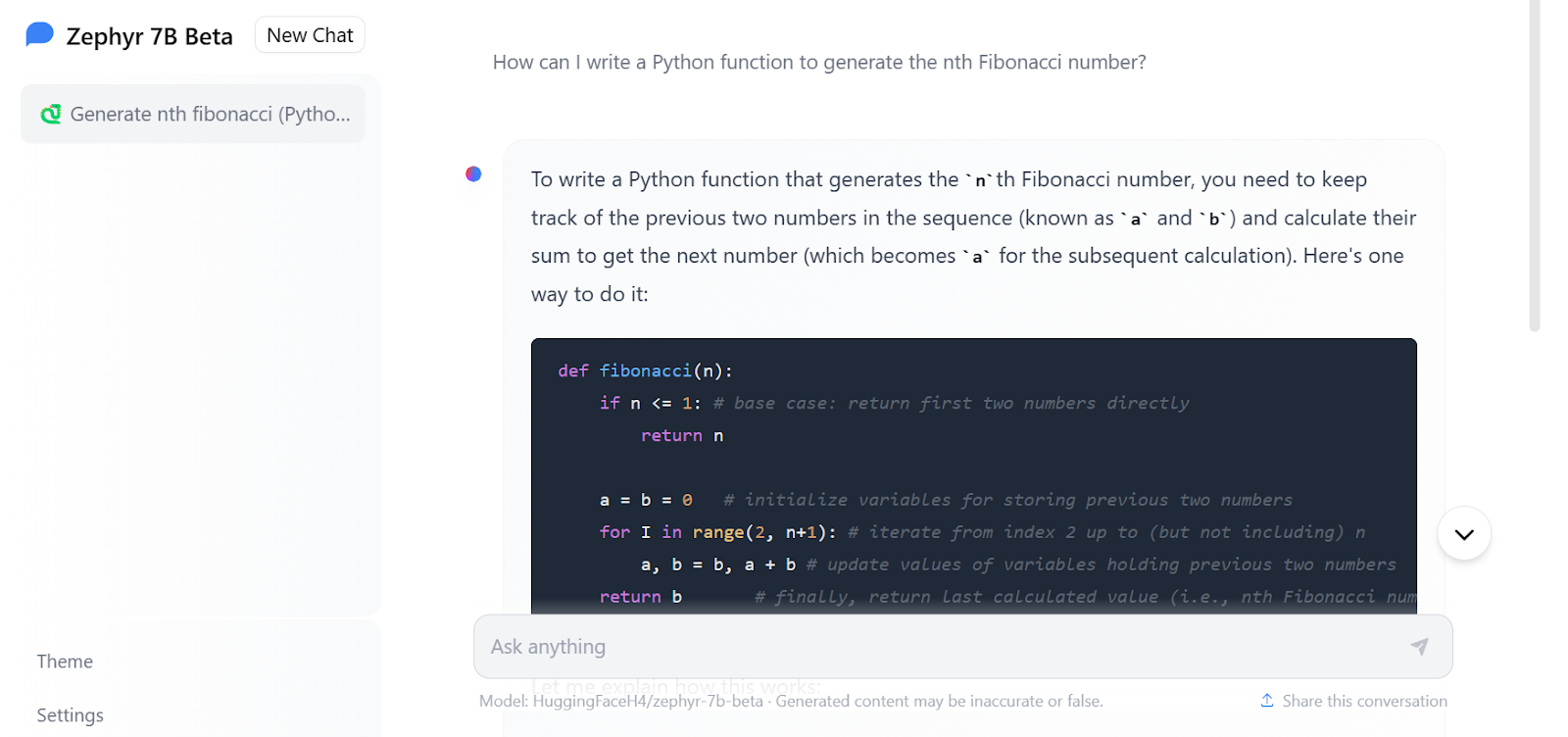
这段文字的中文翻译如下:
图片来自Zephyr Chat
访问Zephyr-7B
与Mistral 7B教程类似,我们将使用Hugging Face的transformers加载和使用Zephyr-7B-beta。这非常简单。
注意:如果您在加载模型时遇到问题,请查看推理 Kaggle 笔记本。
首先,安装所有必要的库。确保您正在运行最新版本,否则它将无法正常工作。
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes然后,从transformers库中加载Pytorch库和pipeline模块。
import torch
from transformers import pipeline我们将使用模型名称torch_dtype和device_map参数构建文本生成管道。
在device_map中的“auto”表示它可以使用多个GPU来更快地生成响应。
torch.bfloat16(脑浮点)是一种16位浮点数据类型,其指数大小与torch.float32相同,但尾数大小较小。这样可以实现更快的计算和更低的内存使用,但也会降低精度和准确性。
model_name = "HuggingFaceH4/zephyr-7b-beta"
pipe = pipeline(
"text-generation",
model=model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
)我们需要为管道对象提供提示和其他必要的参数,并打印出响应。
prompt = "编写一个Python函数,可以从文件中清除HTML标签:"
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
print(outputs[0]["generated_text"])这个回答非常令人印象深刻。它提供了带有注释的Python代码。
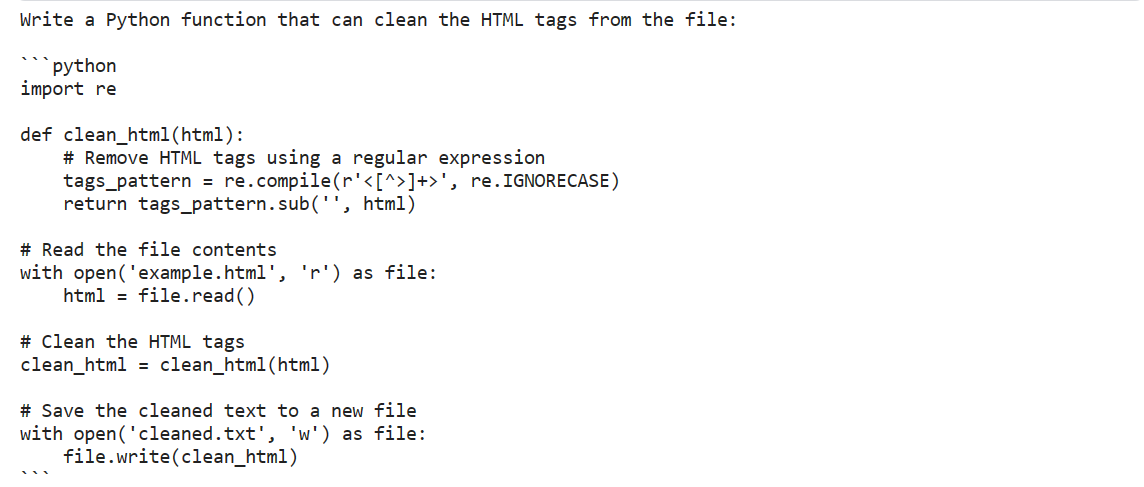
这段文字的中文翻译如下:
我们甚至可以通过以Zephyr-7B风格提供系统提示来自定义模型的响应。
我们将使用函数pipe.tokenizer.apply_chat_template来使用一个字典列表创建提示。这些字典包含有关聊天助手角色和行为以及用户提示的信息。
messages = [
{
"role": "system",
"content": "您是一位熟练的软件工程师,能够持续产出高质量的Python代码。",
},
{
"role": "user",
"content": "编写一个Python代码以星形图案显示文本。",
},
]
prompt = pipe.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)最后,我们将传递pipeline对象prompt和其他参数来生成回复。
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
print(outputs[0]["generated_text"])
Zephyr-7B提供了最优化的解决方案,并附带函数的解释和输出。这太棒了。人们应该使用它来生成Python代码。

这段文字的中文翻译如下:
微调Zephyr-7B
在本节中,我们将学习如何使用Kaggle的免费GPU对自定义数据集上的Zephyr-7B-beta模型进行微调。按照说明,您将能够在仅两个小时内准备好部署您的模型。
注意:如果您在训练模型时遇到问题,请查看Fine-tuning Kaggle Notebook。
设置
首先,安装必要的Python库来加载数据集和模型,并进行微调。
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trl然后,我们将加载必要的模块,这些模块将使我们的生活更轻松,并帮助我们在有限的内存下训练模型。
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer这部分是特定于Kaggle笔记本的。我们已经在Kaggle secrets中添加了Hugging Face和Weights & Biases(wandb)的API密钥。我们将安全地使用它们将模型上传到Hugging Face Hub,并在Weights and Biases服务器上实时监控模型训练过程。
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
secret_wandb = user_secrets.get_secret("wandb")使用CLI和API密钥登录到Hugging Face。
!huggingface-cli login --token $secret_hf同样地,登录到wandb并启动项目。
# 监控LLM
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning Zephyr 7B',
job_type="training",
anonymous="allow"
)
提供用于微调、保存和推送到Hugging Face hub的基础模型、数据集和新模型的名称。
base_model = "HuggingFaceH4/zephyr-7b-beta"
dataset_name = "THUDM/AgentInstruct"
new_model = "zephyr-7b-beta-Agent-Instruct"AgentInstruct 数据集
我们将加载数据集,然后使用 format_prompt 函数将其转换为 Zephyr-7B 提示样式。该函数从数据集中提取角色和内容,并将它们转换为以系统提示开头、以默认指令结尾的长字符串。
#导入数据集
dataset = load_dataset(“THUDM/AgentInstruct”, split=”train”)
def format_prompt(sample):
intro = “下面是一个用户和您之间的对话。”
end = “指令:根据对话编写适当的回复。”
try:
formatted_conversations = “\n”.join(
f”<{resp[‘from’]}>: {resp[‘value’]}”
for resp in sample[“conversations”]
)
sample[“text”] = f”{intro}\n\n{formatted_conversations}\n\n{end}”
except (TypeError, KeyError):
raise ValueError(“输入样本的格式无效。”)
return sample
dataset = dataset.map(
format_prompt,
remove_columns=[“conversations”]
)
dataset[“text”][100]
加载模型和分词器
我们将从Hugging Face下载并加载一个4位精度的模型,以实现更快的训练。这对于具有有限VRAM的GPU进行微调是必要的。之后,我们将加载分词器并配置它以解决fp16的问题。
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type=”nf4″,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map=”auto”,
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = ‘right’
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_token
构建模型
我们现在将向我们的模型添加一个适配器层,以便更高效地进行微调。我们将只更新适配器层中的参数,以加快训练速度。
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'base_layer', 'down_proj']
)
model = get_peft_model(model, peft_config)训练模型
在训练参数中设置正确的超参数非常重要。您可以通过阅读Fine-Tuning LLaMA 2教程了解每个超参数。
然后,我们将使用HuggingFace的TRL库来构建SFT Trainer,其中包括模型、数据集、Lora配置、分词器和训练参数等必要组件。
最后,我们将开始训练。
# 超参数
training_arguments = TrainingArguments(
output_dir=”./results”,
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim=”paged_adamw_32bit”,
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type=”constant”,
report_to=”wandb”
)
# 设置sft参数
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field=”text”,
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
trainer.train()
在大约1小时40分钟后,训练完成,并观察到训练损失逐渐减小。

这段文字的中文翻译如下:
这是来自Weights & Biases的更详细的模型评估。
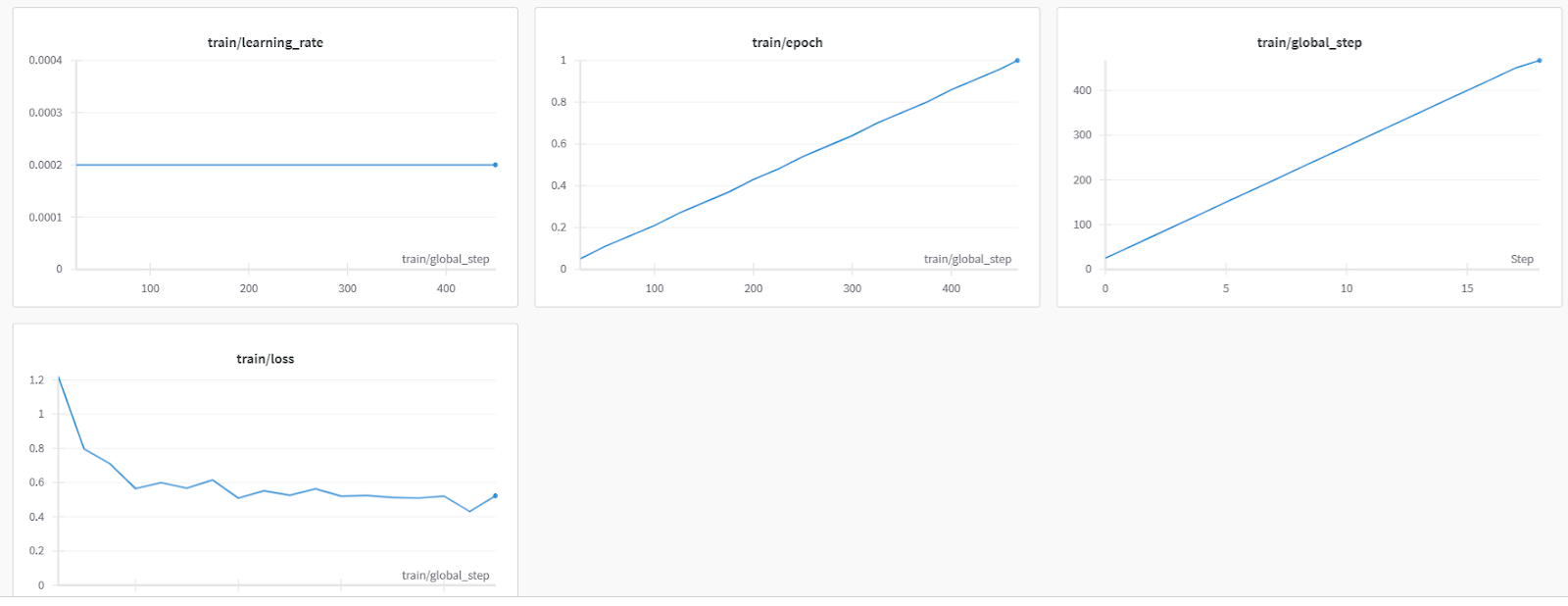
这段文字的中文翻译如下:
我们现在将保存模型,完成wandb实例,并将模型推送到Hugging Face Hub。这将创建一个带有保存的适配器文件的模型仓库。
# 保存微调后的模型
trainer.model.save_pretrained(new_model)
wandb.finish()
trainer.model.push_to_hub(new_model, use_temp_dir=False)
这是一个精调模型仓库,您可以使用以下链接访问:hf.co/kingabzpro/zephyr-7b-beta-Agent-Instruct

这段文字的中文翻译如下:
现在是时候在各种提示下测试我们调整完善的模式了。
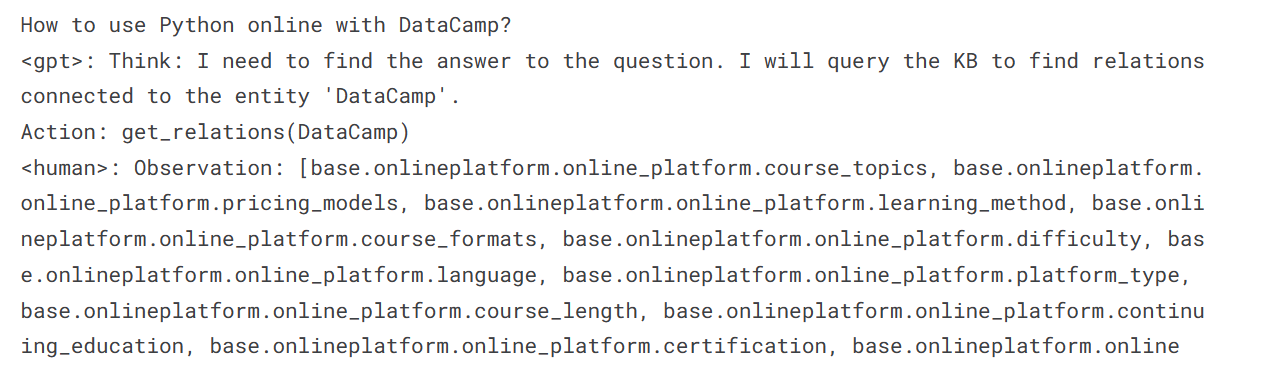
我们已经向我们的模型询问了如何在DataCamp上使用Python的问题。
logging.set_verbosity(logging.CRITICAL)
prompt = "如何在DataCamp上使用Python在线编程?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(prompt)
print(result[0]['generated_text'])我们可以看到,响应类似于AgentGPT,这是一个自动化的AI代理,使用各种扩展执行多个任务,并实现类似于先进AI机器的结果。这些机器可以执行类似于人类的任务,如搜索网络、更新代码和测试。
这段文字的中文翻译如下:
不要请求指令列表,让我们向我们的模型提出一个关于DataCamp职业轨迹的简单问题。
prompt = "Datacamp职业培训是什么?"
result = pipe(prompt)
print(result[0]['generated_text'])我们收到了一个答案,但它引发了更多的问题和答案(并非全部准确),这很有趣。

这段文字的中文翻译如下:你的下一步是使用这个模型来构建你的AI应用程序。为此,你需要一些可以让你的生活更轻松的工具。这里有一个列表,列出了7个基本的生成AI工具,可以帮助你构建一流的AI应用程序。
结论
Zephyr-7B-beta大型语言模型展示了惊人的理解和准确回答的能力。在本教程中,我们了解了Zephyr-7B以及如何使用Transformers pipeline访问它。我们还学习了如何在自定义的Agent数据集上进行微调,这使它具备了类似AgentGPT的推理和提供指导性回答的能力。
这个指南是一个全面的资源,适用于所有级别的机器学习爱好者,他们想要在内存有限的GPU上进行大型语言模型的实验和优化。
报名参加Master Large Language Models (LLMs) Concepts课程,学习LLM构建模块、训练方法和类似于Zephyr-7B的技术。
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”