这篇文章是我们社区的一项有价值的贡献,并由DataCamp进行了编辑,以提高清晰度和准确性。
有兴趣分享您自己的专业知识吗?我们很乐意听到您的声音!请随时通过我们的社区贡献表格提交您的文章或想法。
什么是Apache Airflow?
Apache Airflow,或简称Airflow,是一个用于在生产环境中运行数据流水线的开源工具和框架。作为业界领先的数据工作流管理工具,Apache Airflow利用Python允许数据从业者将其数据流水线定义为代码。Airflow添加了调度流水线执行和观察性能的功能,使其成为您所有数据工作流的集中式中心。无论您是为模型准备训练数据还是将数据持久化到数据湖中,Airflow都提供了使您的数据流水线能够投入生产的功能。
Airflow最初由Maxime Beauchemin于2014年在Airbnb创建,并于2016年3月加入Apache Software Foundation的孵化器计划,后来在2019年被宣布为顶级项目。根据Airflow的2022年调查,Airflow每月下载数百万次,成千上万家公司,无论大小,都依赖这个工具。
Airflow的关键特点
Airflow的框架和架构具有几个关键特点,使其独特。首先,让我们深入了解Airflow框架的最重要特点。
Airflow框架的特点
Airflow框架的最简单单元是任务。任务可以被看作是操作,对于大多数数据团队来说,是数据管道中的操作。
传统的ETL工作流程包括三个任务:提取、转换和加载数据。依赖关系定义了任务之间的关系。回到我们的ETL示例,”加载”任务依赖于”转换”任务,而”转换”任务又依赖于”提取”任务。任务和依赖关系的组合创建了有向无环图(DAGs)。DAGs代表Airflow中的数据流水线,并且定义起来有点复杂。相反,让我们来看一个基本ETL流水线的图示:
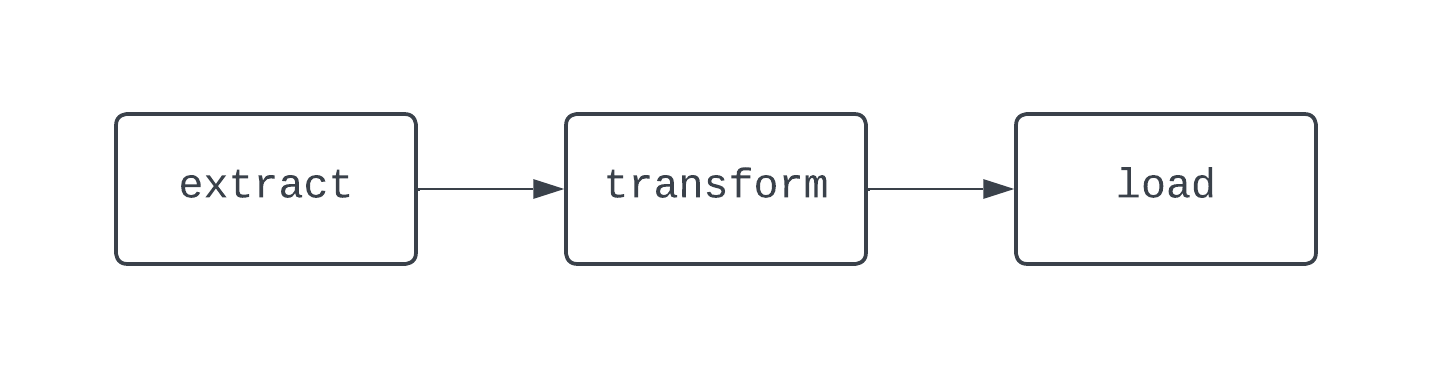
这段文字的中文翻译如下:上面的DAG有三个任务,有两个依赖关系。它被认为是一个DAG,因为任务之间没有循环(或循环)。在这里,箭头显示了过程的有向性;首先运行extract任务,然后是transform和load任务。使用DAG,即使逻辑复杂,也很容易看到过程的明确开始和结束,就像下面显示的DAG一样:
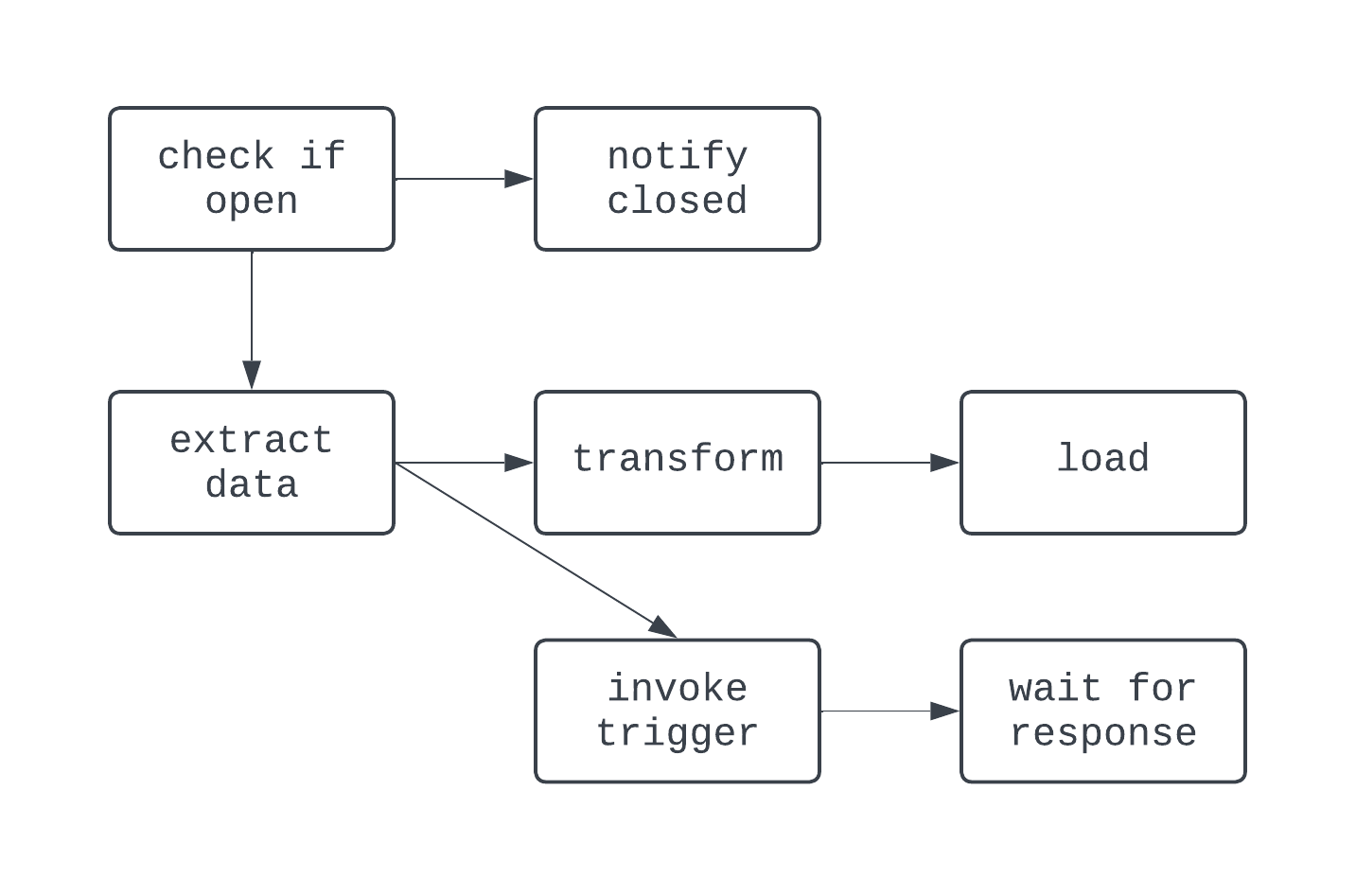
这段文字的中文翻译如下:在这个有向无环图中,逻辑有点疯狂。根据条件进行分支,并且有一些任务并行运行。然而,图是有向的,任务之间没有循环依赖。现在,让我们来看一个不是有向无环图的过程:
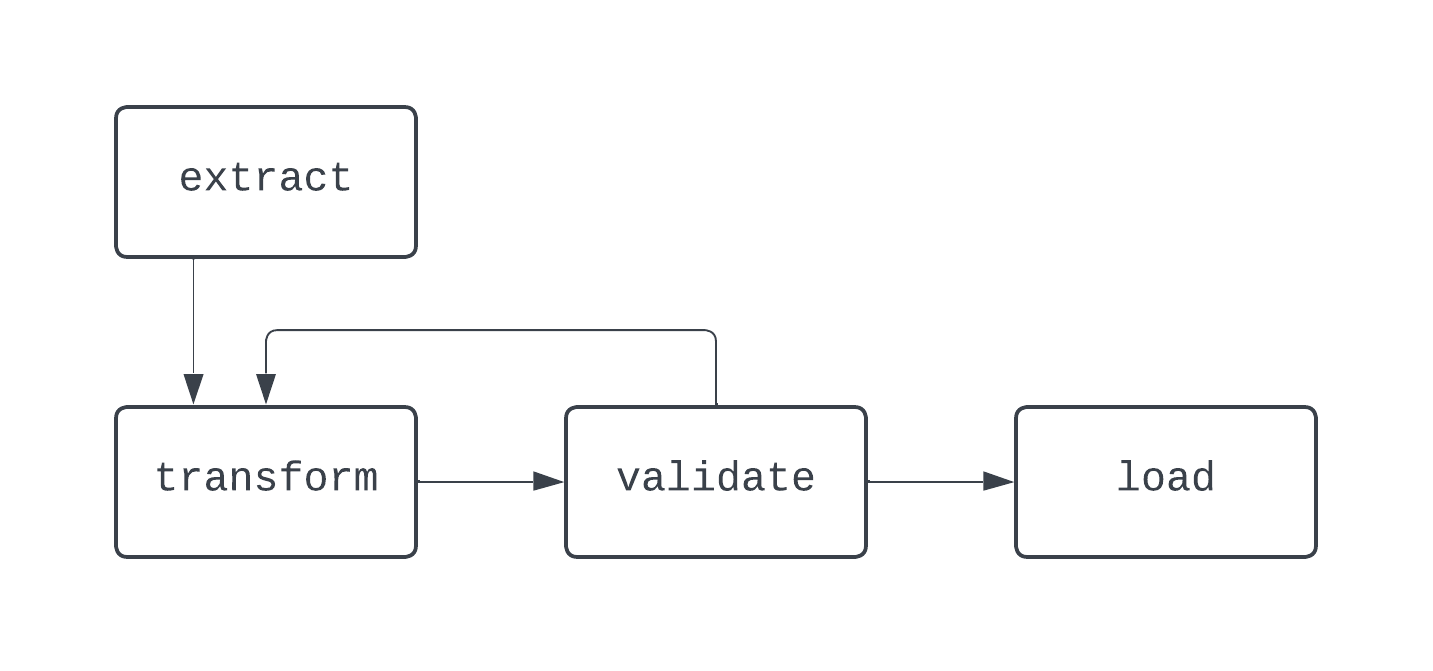
这段文字的中文翻译如下:在这个图表中,transform和validate任务之间存在一个明显的循环。在某些情况下,如果没有办法打破这个循环,这个有向无环图可能会永远运行下去。在构建数据管道时,即使不使用Airflow,最佳实践也是避免创建无法表示为有向无环图(DAG)的工作流程,因为这样可能会丢失关键功能,例如确定性或幂等性。
Airflow架构的特点
为了调度DAG、执行任务并提供数据流水线执行细节的可见性,Airflow利用了以下组件构成的基于Python的架构:
- 调度器
- 执行器
- 元数据数据库
- Web服务器(用户界面)
无论是在本地运行Airflow还是在生产环境中运行,这些组件都必须正常运行,才能使Airflow正常工作。
调度器负责(你可能已经猜到了)调度DAG。要调度DAG,必须在将DAG编写为Python代码时提供DAG的开始日期和调度间隔。
一旦DAG被调度,其中的任务需要被执行,这就是执行器的作用。执行器不运行每个任务内部的逻辑,它只是分配任务给配置好的资源来运行。元数据数据库存储有关DAG运行的信息,例如DAG及其关联任务是否成功运行。
元数据数据库还存储了诸如用户定义的变量和连接等信息,这些信息在构建生产级数据管道时非常有帮助。最后,Web服务器为Airflow提供了用户界面。
这个用户界面(UI)为数据团队提供了一个集中的工具来管理他们的流水线执行。在Airflow UI中,数据团队可以查看他们的DAG的状态,手动重新运行DAG,存储变量和连接等等。Airflow UI提供了对数据摄取和传递过程的集中可见性,帮助数据团队了解和掌握他们的数据流水线性能。
安装Apache Airflow
有多种安装Apache Airflow的方法。我们将介绍其中两种最常见的方法。
使用pip安装Airflow
先决条件:
- 已安装
python3
要使用pip,Python的包管理器,安装Airflow,您可以运行以下命令:
pip install apache-airflow一旦安装完成该软件包,您需要创建Airflow项目的所有组件,例如设置Airflow主目录,创建airflow.cfg文件,启动元数据数据库等等。这可能是一项繁重的工作,并且需要具备相当多的Airflow先决经验。幸运的是,使用Astro CLI有一个更简单的方法。
使用Astro CLI安装Airflow
先决条件:
- 已安装
python3 - 已安装Docker
Astronomer是一个托管的Airflow提供商,提供了许多免费工具,以帮助更轻松地使用Airflow。其中一个工具是Astro CLI。
Astro CLI使得创建和管理运行Airflow所需的一切变得简单。要开始使用,您首先需要安装CL。要在您的计算机上进行此操作,请查看Astronomer的文档,并按照适用于您的操作系统的步骤进行操作。
一旦安装了Astro CLI,配置整个Airflow项目只需要一个命令:
astro dev init这将在您当前的工作目录中配置Airflow项目所需的所有资源。然后,您当前的工作目录将类似于这样:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
项目创建完成后,要启动项目,请运行astro dev start。大约一分钟后,您可以在浏览器中打开Airflow UI,地址为https://localhost:8080/。现在,您已经准备好编写第一个DAG了!
编写你的第一个Airflow DAG
我们已经介绍了Airflow框架和架构的基础知识和更高级的特性。现在Airflow已经安装完成,你可以开始编写你的第一个DAG了。首先,在你刚创建的Airflow项目的dags/目录下创建一个名为sample_dag.py的文件。使用你喜欢的文本编辑器或IDE打开sample_dag.py文件。首先,让我们实例化这个DAG。
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
以上,我们使用airflow模块中的DAG函数与with上下文管理器一起定义了一个DAG。
提供了一个start_date、schedule间隔和catchup的值。这个DAG将在每天UTC时间上午9点运行。由于catchup设置为True,这个DAG将在首次触发的那天和2024年1月1日之间的每一天运行,max_active_runs=1确保一次只能运行一个DAG。
现在,让我们添加一些任务!首先,我们将创建一个任务来模拟从API中提取数据。请查看下面的代码:
...
# 导入PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# 打印消息,返回响应
print("从天气API中提取数据")
return {
"date": "2023-01-01",
"location": "纽约",
"weather": {
"temp": 33,
"conditions": "轻微雪和风"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
接下来,我们将创建一个任务来转换extract_data任务返回的数据。可以使用以下代码完成。在这里,我们使用了Airflow的一个功能,称为XComs,来从前一个任务中检索数据。
由于render_templat_as_native_obj被设置为True,这些值被共享为Python对象而不是字符串。然后,从extract_data任务中提取的原始数据作为关键字参数传递给transform_data_callable。然后对这些数据进行转换并返回,它将以类似的方式被load_data任务使用。
…
# 导入pandas库
import pandas as pd
…
def transform_data_callable(raw_data):
# 将响应转换为列表
transformed_data = [
[
raw_data.get(“date”),
raw_data.get(“location”),
raw_data.get(“weather”).get(“temp”),
raw_data.get(“weather”).get(“conditions”)
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id=”transform_data”,
python_callable=transform_data_callable,
op_kwargs={“raw_data”: “{{ ti.xcom_pull(task_ids=’extract_data’) }}”}
)
def load_data_callable(transformed_data):
# 将数据加载到DataFrame中,并设置列名
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
“date”,
“location”,
“weather_temp”,
“weather_conditions”
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id=”load_data”,
python_callable=load_data_callable,
op_kwargs={“transformed_data”: “{{ ti.xcom_pull(task_ids=’transform_data’) }}”}
)
…
最后,设置任务之间的依赖关系。这段代码设置了”extract_data”、”transform_data”和”load_data”任务之间的依赖关系,以创建一个基本的ETL DAG。
...
提取数据 >> 转换数据 >> 加载数据
最终产品将会是这样的!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# 从天气API中提取数据
print("从天气API中提取数据")
return {
"date": "2023-01-01",
"location": "纽约",
"weather": {
"temp": 33,
"conditions": "轻微雪和风"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# 将响应转换为列表
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# 将数据加载到DataFrame中,并设置列名
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# 设置任务之间的依赖关系
extract_data >> transform_data >> load_data
一旦您将管道定义为Python代码,您可以使用Airflow UI打开DAG。点击weather_etl DAG,然后在左上角切换开关。观察您的任务和DAG成功完成运行。
恭喜,你已经编写并运行了你的第一个Airflow DAG!
除了使用传统的运算符外,Airflow还引入了TaskFlow API,使用装饰器和原生Python代码更容易定义DAG和任务。
与其明确地使用XCom在任务之间共享数据,TaskFlow API将这个逻辑抽象出来,而是在幕后使用XCom。下面的代码展示了与上面完全相同的逻辑和功能,这次是使用TaskFlow API实现的,对于习惯于构建基于脚本的ETL逻辑的数据分析师和科学家来说更直观。
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# 从天气API中提取数据
print("从天气API中提取数据")
return {
"date": "2023-01-01",
"location": "纽约",
"weather": {
"temp": 33,
"conditions": "轻微雪和风"
}
}
@task()
def transform_data(raw_data):
# 将响应转换为列表
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# 将数据加载到DataFrame中,并设置列名
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# 使用函数调用设置依赖关系
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# 允许运行DAG
weather_etl()
Airflow最佳实践
构建Airflow DAG可能会很棘手。在构建数据管道和工作流时,不仅要考虑Airflow,还要考虑其他工具的一些最佳实践。
模块化
通过任务,Airflow帮助更容易可视化模块化。不要在一个任务中尝试做太多事情。虽然整个ETL流水线可以在一个任务中构建,但这会使故障排除变得困难。这也会使DAG的性能可视化变得困难。
创建任务时,确保任务只做一件事情非常重要,就像Python中的函数一样。
看一下下面的示例。两个DAG在代码的同一点上都执行相同的操作并失败。然而,在左边的DAG中,很明显是load逻辑导致了失败,而在右边的DAG中这一点并不太清楚。
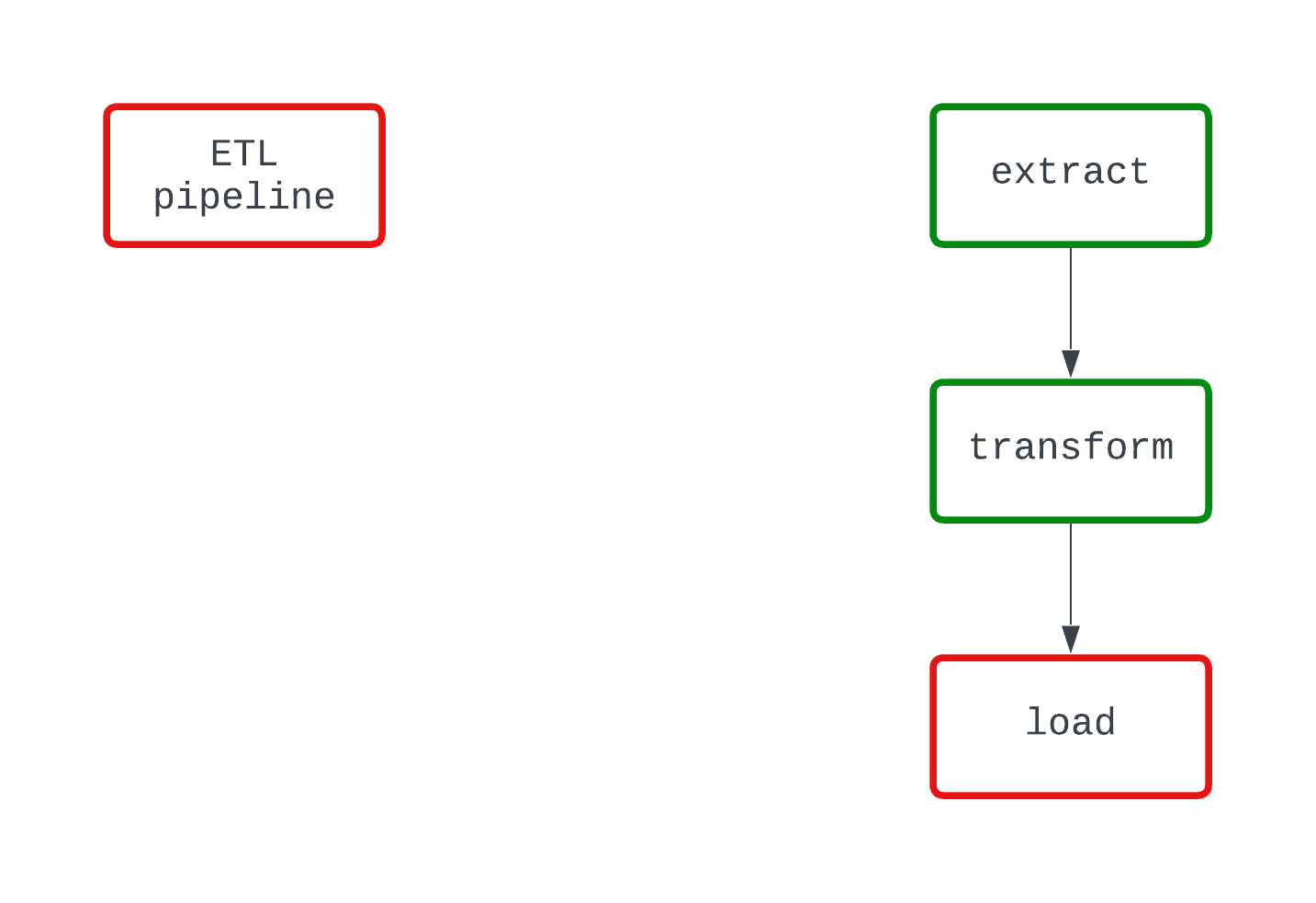
这段文字的中文翻译如下:
确定性
确定性过程是指在给定相同输入的情况下产生相同结果的过程。当有向无环图(DAG)在特定时间间隔内运行时,它应该每次生成相同的结果。虽然确定性是数据流水线的一个更复杂的特征,但它对于确保一致的结果非常重要。
使用Airflow,利用Jinja模板将模板字段传递给Airflow操作符,而不是使用datetime.now()函数来创建时间数据。
幂等性
如果你对同一个时间间隔运行一个DAG两次会发生什么?如果运行10次呢?你的目标存储介质中会出现重复数据吗?幂等性确保即使数据管道被多次执行,它就像只执行了一次。
为了使数据流水线具有确定性,请考虑将以下逻辑纳入您的DAG中:
- 在重新运行DAG时覆盖文件,而不是在同一时间间隔运行时创建一个具有不同名称的新文件
- 使用删除-写入模式将数据推送到数据库和数据仓库,而不是使用
INSERT,这可能会导致重复。
编排不是转换
Airflow并不适用于处理大量数据。如果要对超过几个千兆字节的数据进行转换,Airflow仍然是适合此工作的正确工具;但是,Airflow应该调用另一个工具(如dbt或Databricks)来运行转换。
通常情况下,任务在您的本地计算机上执行,或者在生产环境中使用工作节点执行。无论哪种方式,只有几个千兆字节的内存可用于任何需要的计算工作。
专注于使用Airflow进行轻量级数据转换,并作为在处理较大数据时的编排工具。
Apache Airflow在工业中的应用
由于Airflow能够将数据管道定义为代码,并且具有各种连接器和操作器,全球各地的公司都依赖Airflow来帮助驱动其数据平台。
在工业领域,数据团队可能会使用各种各样的工具,从SFTP站点到云文件存储系统再到数据湖。要构建一个数据平台,这些不同的系统之间的集成至关重要。
拥有一个充满活力的开源社区,有数千个预构建的连接器可帮助集成您的数据工具。想要将S3中的文件导入Snowflake吗?幸运的是,S3ToSnowflakeOperator使这一过程变得简单!那么,使用Great Expectations进行数据质量检查呢?这也已经被构建好了。
如果您找不到适合工作的预构建工具,那没关系。Airflow是可扩展的,这使得您可以轻松构建自己的定制工具以满足您的需求。
当在生产环境中运行Airflow时,您还需要考虑用于管理基础架构的工具。有多种方法可以做到这一点,包括像Astronomer这样的高级服务提供商,像MWAA这样的云原生选项,甚至是自己开发的解决方案。通常,这涉及成本和基础设施管理之间的权衡;更昂贵的解决方案可能意味着管理的工作较少,而在单个EC2实例上运行所有内容可能廉价但难以维护。
结论
Apache Airflow是一个在生产环境中运行数据管道的行业领先工具。它提供了调度、可扩展性和可观察性等功能,同时允许数据分析师、科学家和工程师将数据管道定义为代码。Airflow帮助数据专业人员专注于产生业务影响。
使用Airflow非常容易入门,尤其是使用Astro CLI和传统的operators以及TaskFlow API,可以轻松编写第一个DAG。在使用Airflow构建数据流水线时,确保在设计决策中始终保持模块化、确定性和幂等性;这些最佳实践将帮助您避免后续的麻烦,特别是当您的DAG遇到错误时。
使用Airflow,有很多东西可以学习。在你的下一个数据分析或数据科学项目中,试试Airflow吧。尝试使用预建的操作符,或者构建你自己的操作符。试试使用传统操作符和TaskFlow API在任务之间共享数据。不要害怕挑战极限。如果你准备好开始了,可以查看DataCamp的Python中的Airflow入门课程,该课程介绍了Airflow的基础知识,并探讨了如何在生产环境中实现复杂的数据工程流水线。
您还可以开始我们的数据管道入门课程,该课程将帮助您提升构建高效、高性能和可靠的数据管道的技能。
如果你想要更多资源,请查看下面的一些资源。祝你好运,编码愉快!
资源
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”