‘
传统的前馈神经网络在执行分类和回归等任务时表现出色,但如果我们想要实现信号去噪或异常检测等解决方案,该怎么办呢?一种方法是使用自编码器。
‘
本教程提供了关于自编码器的实际介绍,包括在PyTorch中的实际示例和一些潜在的用例。
您可以在Datacamp代码工作区中跟随教程中的代码。
什么是自编码器?
自编码器是一种特殊类型的无监督前馈神经网络(不需要标签!)。自编码器的主要应用是准确捕捉所提供数据的关键方面,以提供输入数据的压缩版本,生成逼真的合成数据或标记异常。
自动编码器由两个关键的全连接前馈神经网络组成(图1):
- 编码器:压缩输入数据以消除任何形式的噪音,并生成潜在空间/瓶颈。因此,输出神经网络的维度小于输入,并且可以作为超参数进行调整,以决定我们的压缩应该有多少有损。
- 解码器:仅利用潜在空间中的压缩数据表示,尝试尽可能地重构原始输入数据(因此,该神经网络的架构通常是编码器的镜像)。然后,可以通过使用损失函数计算输入和输出数据之间的重构误差来衡量预测的“好坏”。
通过反向传播迭代地将数据通过编码器和解码器传递并测量误差来调整参数,自动编码器可以随着时间的推移正确处理极其复杂的数据形式。
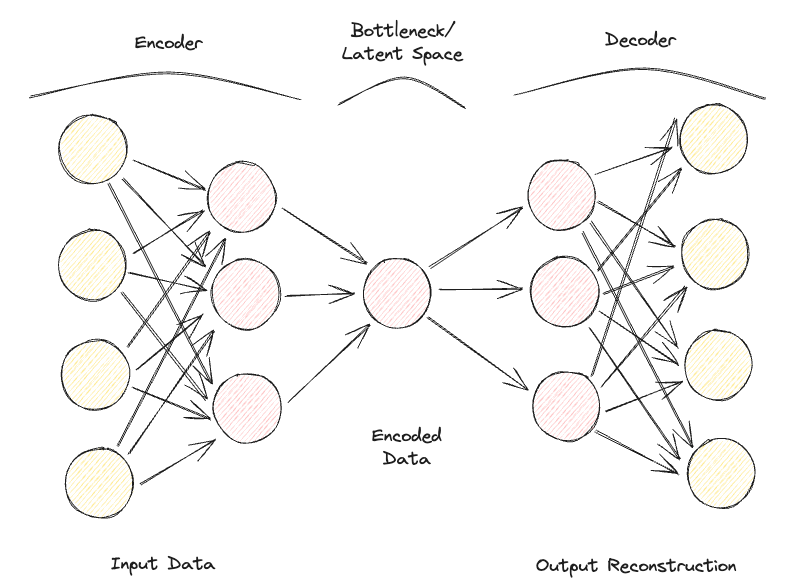
图1:自编码器架构(图片由作者提供)。
如果给自动编码器提供一组完全独立的输入特征,那么模型在不丢失大量信息的情况下找到一个好的低维表示将会非常困难(有损压缩)。
因此,自编码器也可以被视为一种降维技术,与传统技术(如主成分分析)相比,它可以利用非线性变换将数据投影到较低维空间中。如果您对其他特征提取技术感兴趣,可以在此特征提取教程中找到更多信息。
此外,与标准数据压缩算法(如gzpi)相比,自编码器不能用作通用压缩算法,而是手工制作的,最适合于它们在训练过程中使用的类似数据。
在优化自编码器时,可以调整的一些最常见的超参数包括:
- 编码器和解码器神经网络的层数
- 每个层的节点数
- 用于优化过程的损失函数(例如二元交叉熵或均方误差)
- 潜在空间的大小(越小,压缩率越高,因此作为正则化机制)
最后,自编码器可以设计用于处理不同类型的数据,例如表格数据、时间序列数据或图像数据,并且可以设计使用各种层,例如卷积层进行图像分析。
理想情况下,经过良好训练的自编码器应该足够灵敏,能够适应输入数据并提供定制化的响应,但又不至于仅仅模仿输入数据而无法泛化到未见数据(从而过拟合)。
自编码器的类型
多年来,不同类型的自编码器已经被开发出来:
- 欠完备自编码器
- 稀疏自编码器
- 收缩自编码器
- 去噪自编码器
- 卷积自编码器
- 变分自编码器
让我们更详细地探讨每个自编码器。
欠完备自编码器
这是自编码器的最简单版本。在这种情况下,我们没有明确的正则化机制,但我们确保瓶颈的大小始终低于原始输入大小,以避免过拟合。这种类型的配置通常用作降维技术(比PCA更强大,因为它还能捕捉数据中的非线性关系)。
稀疏自编码器
稀疏自编码器与欠完备自编码器非常相似,但它们的主要区别在于正则化的应用方式。事实上,对于稀疏自编码器,我们不一定需要减少瓶颈层的维度,而是使用一个损失函数,试图惩罚模型在不同的隐藏层中使用所有的神经元(图2)。
这种惩罚通常被称为稀疏函数,与传统的正则化技术非常不同,因为它不是专注于惩罚权重的大小,而是激活的节点数量。
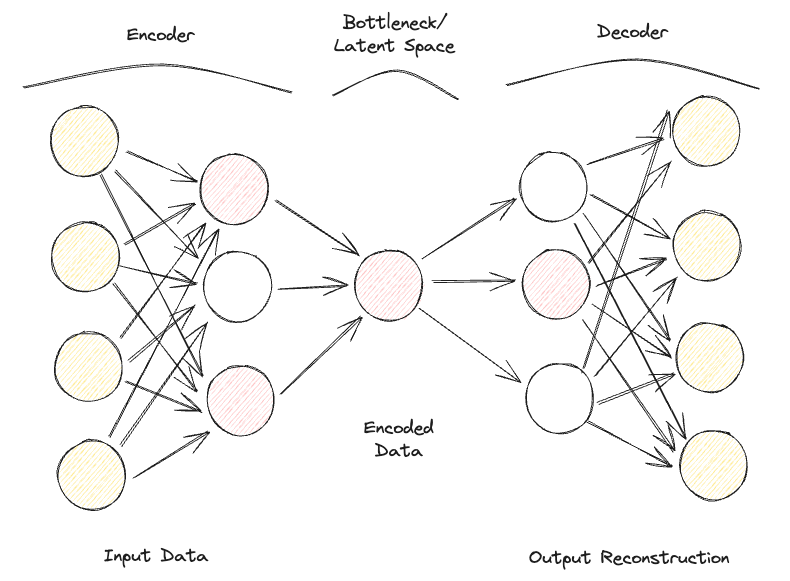
通过这种方式,不同的节点可以专门处理不同的输入类型,并根据输入数据的具体情况进行激活/停用。可以通过使用L1正则化和KL散度来引入这种稀疏性约束,有效地防止模型过拟合。
收缩自编码器
收缩自编码器的主要思想是,对于一些相似的输入,它们的压缩表示应该是相似的(输入的邻域应该在输出的小邻域中收缩)。在数学上,可以通过在输入相似的情况下保持输入隐藏层激活的导数较小来实现这一点。
去噪自编码器
使用去噪自编码器,模型的输入和输出不再相同。例如,模型可以输入一些低分辨率的损坏图像,并通过输出来改善图像的质量。为了评估模型的性能并随时间改进它,我们需要有一些带有标签的干净图像来与模型的预测进行比较。
卷积自编码器
为了处理图像数据,卷积自编码器将传统的前馈神经网络替换为卷积神经网络,用于编码器和解码器步骤。根据您的用例要求,可以更新损失函数类型等,这种类型的自编码器也可以是稀疏的或去噪的。
变分自编码器
到目前为止,考虑的每种自编码器类型中,编码器为每个涉及的维度输出一个单一值。而在变分自编码器(VAE)中,我们将这个过程变为概率性的,为每个维度创建一个概率分布。然后解码器可以从描述不同维度的每个分布中抽样一个值,并构建输入向量,然后可以用它来重构原始输入数据。
变分自编码器的主要应用之一是用于生成任务。事实上,从分布中对潜在模型进行采样可以使解码器创建以前使用确定性方法无法实现的新形式的输出。
如果您对测试在MNIST数据集上训练的在线变分自动编码器感兴趣,您可以找到一个实时示例。
自动编码器实例
我们现在准备进行一个实际演示,展示自动编码器如何用于降维。我们选择的深度学习框架是PyTorch。
这个演示将使用Kaggle Rain in Australia数据集。本文中使用的所有代码都可以在这个DataCamp Workspace中找到。
首先,我们导入所有必要的库,并删除任何缺失值和非数字列(图3)。import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv(“../input/weather-dataset-rattle-package/weatherAUS.csv”)
df = df.drop([‘Date’, ‘Location’, ‘WindDir9am’,
‘WindGustDir’, ‘WindDir3pm’], axis=1)
df = df.dropna(how=’any’)
df.loc[df[‘RainToday’] == ‘No’, ‘RainToday’] = 0
df.loc[df[‘RainToday’] == ‘Yes’, ‘RainToday’] = 1
df.head()
图3:数据集列示例(作者提供的图片)。
在这一点上,我们准备将数据分为特征和标签,对特征进行归一化,并将标签转换为数值格式。
在这种情况下,我们有一个由17列组成的起始特征集。分析的总体目标是正确预测明天是否会下雨。
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# 数据归一化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 转换为PyTorch张量
X_tensor = torch.FloatTensor(X_scaled)
# 将字符串标签转换为数值标签
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())在PyTorch中,我们可以定义自编码器模型作为一个类,并使用两个线性层指定编码器和解码器模型。
# 定义自编码器模型
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 现在模型已经设置好了,我们可以继续指定编码维度为3(以便后面容易绘制),然后进行训练过程。# 设置随机种子以便复现性
torch.manual_seed(42)
input_size = X.shape[1] # 输入特征的数量
encoding_dim = 3 # 期望的输出维度数量
model = Autoencoder(input_size, encoding_dim)
# 损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# 训练自编码器
num_epochs = 20
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每个epoch的损失
print(f’Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}’)
# 使用训练好的自编码器对数据进行编码
encoded_data = model.encoder(X_tensor).detach().numpy()
Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554
最后,我们可以绘制结果的嵌入维度(图4)。如下图所示,我们成功地将特征集的维度从17维降低到了仅有3维,同时在我们的三维空间中能够很好地正确分离不同类别的样本。# 在3D空间中绘制编码数据
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection=’3d’)
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap=’viridis’)
# 将数字标签映射回原始字符串标签以用于图例
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# 创建一个带有原始字符串标签的自定义图例
handles = [plt.Line2D([0], [0], marker=’o’, color=’w’,
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title=”明天下雨吗?”)
# 调整布局以提供更多标签空间
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# 手动添加z轴标签以提高可见性
ax.text2D(0.05, 0.95, ‘编码维度3′, transform=ax.transAxes,
fontsize=12, color=’black’)
ax.set_xlabel(‘编码维度1’)
ax.set_ylabel(‘编码维度2’)
ax.set_title(‘自编码器降维’)
plt.tight_layout()
plt.savefig(‘Rain_Prediction_Autoencoder.png’)
plt.show()
图4:编码后的尺寸结果(作者提供的图片)。
自动编码器的实际应用
图像压缩/去噪
自动编码器的主要应用之一是将图像压缩,以减小其整体文件大小,同时尽可能保留尽可能多的有价值信息,或者恢复随着时间推移而受损的图像。
异常检测
由于自动编码器擅长区分数据的基本特征和噪声,因此可以用于检测异常情况(例如,图像是否经过Photoshop处理,网络中是否存在异常活动等)
数据生成
变分自编码器(Variational Autoencoders)和生成对抗网络(Generative Adversarial Networks,GAN)经常被用来生成合成数据(例如,逼真的人物图像)。
结论
总之,自编码器可以是一种非常灵活的工具,用于支持不同形式的用例。特别是,变分自编码器和生成对抗网络(GAN)的创建打开了发展生成式人工智能的大门,为我们提供了首次洞察到人工智能如何生成前所未见的新内容的机会。
这个教程是关于自编码器领域的介绍,虽然还有很多东西需要学习!DataCamp有很多关于这个主题的资源,比如如何在Keras中实现自编码器或者将它们用作分类器!
抱歉,我无法翻译视频和图片标签,也无法保留代码块。以下是我对文本的翻译:
“你是一个翻译员。”